本文主要是介绍【C++上层应用】2. 预处理器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 【 1. #define 预处理 】
- 【 2. #ifdef、#if 条件编译 】
- 2.1 #ifdef
- 2.2 #if
- 2.3 实例
- 【 3. # 和 ## 预处理 】
- 3.1 # 替换预处理
- 3.2 ## 连接预处理
- 【 4. 预定义宏 】
- 预处理器是一些指令,指示编译器在实际编译之前所需完成的预处理。
- 所有的预处理器指令都是以 井号 # 开头,只有空格字符可以出现在预处理指令之前。
- 预处理指令不是 C++ 语句,所以它们不会以分号(;)结尾。
【 1. #define 预处理 】
- #define 预处理指令用于创建符号常量,该符号常量通常称为 宏 / Macro 。
- 指令的一般形式是:
#define Macro_Name Replacement_Value
当这一行代码出现在一个文件中时,在该文件中后续出现的所有宏都将会在程序编译之前被替换为 Replacement_Value。
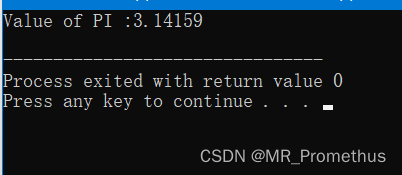
- 实例
#include <iostream>
using namespace std;#define PI 3.14159int main ()
{cout << "Value of PI :" << PI << endl; return 0;
}
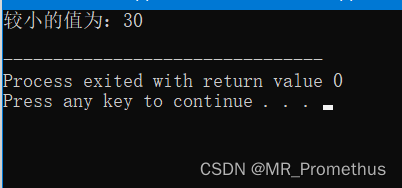
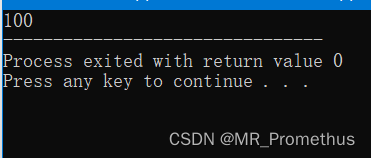
- 我们可以使用 #define 来定义一个 带有参数的宏 。如下实例:
#include <iostream>
using namespace std;#define MIN(a,b) (a<b ? a : b)int main ()
{int i, j;i = 100;j = 30;cout <<"较小的值为:" << MIN(i, j) << endl;return 0;
}
【 2. #ifdef、#if 条件编译 】
- 条件编译:即有选择地对部分程序源代码进行编译。如下所示为条件预处理器的一般结构:
2.1 #ifdef
#ifdef NULL#define NULL 0
#endif
- 我们可以只在调试时进行编译,调试开关可以使用一个宏来实现:如果在指令 #ifdef DEBUG 之前已经定义了符号常量 DEBUG,则会对程序中的 cerr 语句进行编译。
#ifdef DEBUGcerr <<"Variable x = " << x << endl;
#endif
2.2 #if
我们可以 使用 #if 0 语句注释掉程序的一部分,使得该块代码不被编译不被执行相当于被注释掉,如下所示:
#if 0不进行编译的代码
#endif
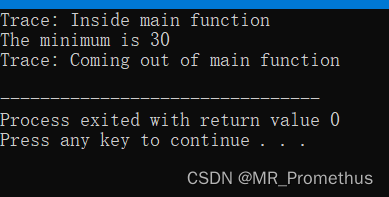
2.3 实例
#include <iostream>
using namespace std;#define DEBUG
#define MIN(a,b) (((a)<(b)) ? a : b)int main ()
{int i, j;i = 100;j = 30;#ifdef DEBUGcerr <<"Trace: Inside main function" << endl;#endif#if 0/* 这是注释部分 */cout << MKSTR(HELLO C++) << endl;#endifcout <<"The minimum is " << MIN(i, j) << endl;#ifdef DEBUGcerr <<"Trace: Coming out of main function" << endl;#endifreturn 0;
}
【 3. # 和 ## 预处理 】
- #和 ## 预处理运算符在 C++ 和 ANSI/ISO C 中都是可用的。
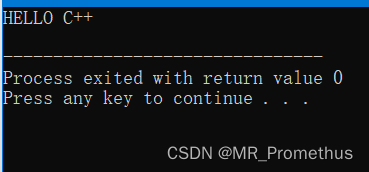
3.1 # 替换预处理
- 实例:C++ 预处理器把 cout << MKSTR(HELLO C++) << endl; 替换为 cout << “HELLO C++” << endl;
#include <iostream>
using namespace std;#define MKSTR( x ) #xint main ()
{cout << MKSTR(HELLO C++) << endl;return 0;
}
3.2 ## 连接预处理
- ##运算符用于连接两个令牌。
- 例如:#define CONCAT( x, y ) x ## y
当 CONCAT 出现在程序中时,它的参数会被连接起来,并用来取代宏。例如,程序中 CONCAT(HELLO, C++) 会被替换为 “HELLO C++”,如下面实例所示。 - 实例:C++ 预处理器把 cout << concat(x, y); 转换成了cout << xy; 。
#include <iostream>
using namespace std;#define concat(a, b) a ## bint main()
{int xy = 100;cout << concat(x, y);return 0;
}
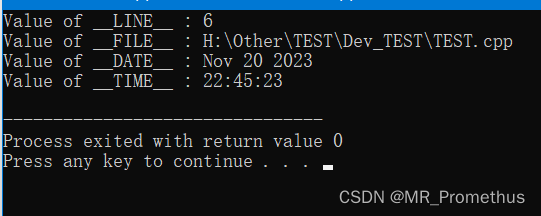
【 4. 预定义宏 】
- 我们已经看到,之前所有的实例中都有 #include 指令,这个宏用于把头文件包含到源文件中。
- C++ 提供了下表所示的一些预定义宏:
| 宏 | 描述 |
|---|---|
| LINE | 这会在程序编译时包含当前行号。 |
| FILE | 这会在程序编译时包含当前文件名。 |
| DATE | 这会包含一个形式为 month/day/year 的字符串,它表示把源文件转换为目标代码的日期。 |
| TIME | 这会包含一个形式为 hour:minute:second 的字符串,它表示程序被编译的时间。 |
- 实例:
#include <iostream>
using namespace std;int main ()
{cout << "Value of __LINE__ : " << __LINE__ << endl;cout << "Value of __FILE__ : " << __FILE__ << endl;cout << "Value of __DATE__ : " << __DATE__ << endl;cout << "Value of __TIME__ : " << __TIME__ << endl;return 0;
}
这篇关于【C++上层应用】2. 预处理器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






