本文主要是介绍二百零三、Flume——Flume实时采集数据频率为1s的高频率Kafka数据直接写入ODS层表的HDFS文件路径下,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、目的
在离线数仓中,需要用Flume去采集Kafka中的数据,然后写入HDFS中。
由于每种数据类型的频率、数据大小、数据规模不同,因此每种数据的采集需要不同的Flume配置文件。玩了几天Flume,感觉Flume的使用难点就是配置文件
二、使用场景
静态排队数据是数据频率为1s的数据类型代表,数据量很大、频率很高,因此搞定了静态排队数据的采集就搞定了这一类高频率数据的实时采集问题
1台雷达每日的静态排队数据规模是25MB,10台雷达的数据规模则是250MB
三、静态排队数据的配置文件
## agent a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
## configure source s1
a1.sources.s1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.s1.kafka.bootstrap.servers = 192.168.0.27:9092
a1.sources.s1.kafka.topics = topic_b_queue
a1.sources.s1.kafka.consumer.group.id = queue_group
a1.sources.s1.kafka.consumer.auto.offset.reset = latest
a1.sources.s1.batchSize = 1000
## configure channel c1
## a1.channels.c1.type = memory
## a1.channels.c1.capacity = 10000
## a1.channels.c1.transactionCapacity = 1000
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/data/flumeData/checkpoint/queue
a1.channels.c1.dataDirs = /home/data/flumeData/flumedata/queue
## configure sink k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hurys23:8020/user/hive/warehouse/hurys_dc_ods.db/ods_queue/day=%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = queue
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.rollSize = 10240000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 60
a1.sinks.k1.hdfs.minBlockReplicas = 1
## Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
四、Flume写入HDFS结果
Flume根据时间戳按照ODS层表的分区,将数据写入对应HDFS文件

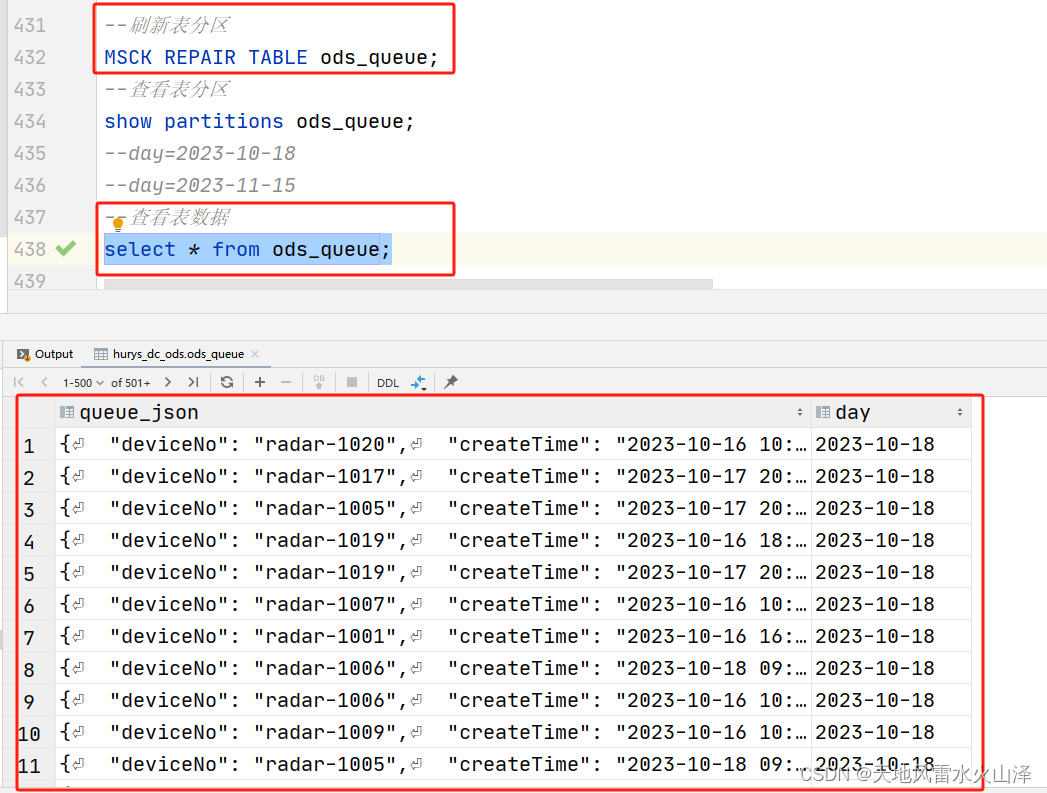
五、ODS表刷新分区后查验数据
(一)刷新表分区
MSCK REPAIR TABLE ods_queue;
(二)查看表数据
select * from ods_queue;
六、注意点
(一)配置文件中的重点是红色标记的几点
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.rollSize = 10240000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 60
a1.sinks.k1.hdfs.minBlockReplicas = 1
(二)这几个重点参数的含义
| 序号 | Flume参数 | 参数含义 |
| 1 | round | 是否启用时间上的”舍弃”,如果启用,则会影响除了%t的其他所有时间表达式 默认值:false |
| 2 | roundValue | 多少时间单位创建一个新的文件夹 |
| 3 | roundUnit | 重新定义时间单位 |
| 4 | rollSize | 当临时文件达到该大小(单位:bytes)时,滚动成目标文件;默认值:1024byte 如果设置成0,则表示不根据临时文件大小来滚动文件 |
| 5 | rollCount | 当events数据达到该数量时候,将临时文件滚动成目标文件;默认值:10 如果设置成0,则表示不根据events数据来滚动文件 |
| 6 | rollInterval | 多久将临时文件滚动成最终目标文件,单位:秒;默认值:30s 如果设置成0,则表示不根据时间来滚动文件; |
| 7 | idleTimeout | 当目前被打开的临时文件在该参数指定的时间(秒)内,没有任何数据写入,则将该临时文件关闭并重命名成目标文件; 默认值:0 |
| 8 | minBlockReplicas | 写入HDFS文件块的最小副本数,一般配置成1才能正确滚动文件 |

更多Flume配置文件参数含义请看鄙人另一篇博客
一百九十一、Flume——Flume配置文件各参数含义(持续完善中)
http://t.csdnimg.cn/o5XbG![]() http://t.csdnimg.cn/o5XbG
http://t.csdnimg.cn/o5XbG
就先这样吧,如果有问题的话后面再更新!!!
这篇关于二百零三、Flume——Flume实时采集数据频率为1s的高频率Kafka数据直接写入ODS层表的HDFS文件路径下的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





