本文主要是介绍数据治理-数据质量管理-Data governance Day1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言:
一、数据与质量
1.1何为数据
1.2何为质量
二、管理
2.1管理啥
2.2减少不合格数据产生
1、自动化代替手工台账
2、流程优化
2.3清洗不合格数据
1、业务清洗
2、数据清洗
三、总结
前言:
首先我们来了解下数据治理七种常用方法,今天主要根据个人经验分享数据质量管理相关心得,一是记录个人数据治理的经验便于以后查看回顾,二是微雕自己成就他人、成就自己。
-
数据分类和标准化:将数据按照一定的规则进行分类和标准化,以便于后续的管理和使用。
-
数据元数据管理:对数据进行元数据管理,包括数据定义、数据结构、数据格式等,以确保数据的准确性和一致性。
-
数据质量管理:对数据进行质量管理,包括数据完整性、准确性、一致性、可靠性等,以确保数据质量符合业务需求。
-
数据安全管理:管理和保护数据的安全性,包括数据访问控制、数据加密、数据备份和恢复等。
-
数据生命周期管理:对数据进行全生命周期管理,包括数据采集、存储、处理、分析、使用等,以确保数据的可追溯性和合规性。
-
数据治理组织架构:建立数据治理组织架构,包括数据治理委员会、数据管理员、数据质量管理人员等,以确保数据治理工作的有效实施。
-
数据治理流程管理:建立数据治理流程管理,包括数据治理流程设计、数据治理流程执行、数据治理流程监控等,以确保数据治理工作的规范化和标准化。
一、数据与质量
1.1何为数据
数据是指对客观事件进行记录并可以鉴别的符号,是信息的表现形式和载体。据所指代的并不仅是狭义上的数字,还可以包括符号、文字、语音、图形和视频等。
在计算机科学中数据是指所有能输入到计算机中并被计算机程序处理的符号和介质的总称。数据经过加工后就成为信息。
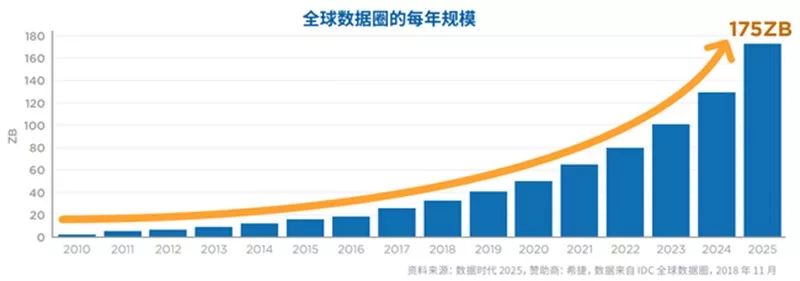
据IDC发布《数据时代2025》的报告显示,全球每年产生的数据将从2018年的33ZB增长到175ZB,相当于每天产生491EB的数据。
1.2何为质量
数据质量就是通过一组维度来测量数据的方式。就如同判断东西的好坏和性价比一样,数据也有一些好坏的评判标准。
包括数据完整性、准确性、一致性、可靠性等,以确保数据质量符合业务需求。
二、管理
2.1管理啥
由上所述数据质量管理的目标 是确保数据质量符合业务需求。因此在数据质量管理中离不开两个对象的共同参与业务与IT。业务包括主要应用部分,上下游关联部门。进而我们发现其实只要我们的数据符合规定的业务,我们就认为是好数据,不然就是坏数据。这样我们对数据好坏标准就明确了。
| 名称 | 定义 |
| 目标 | 确保数据质量符合业务需求 |
| 标准 | 好数据:符合业务规定 坏数据:不符合业务规定 |
| 影响 | 好数据:辅助决策、让智能决策成为可能 坏数据:对数据失信,令管理层无法果断决策 |
因此管理就是让数据符合业务规定,不让数据跑偏,即减少不合格数据产生+清洗不合格数据。
2.2减少不合格数据产生
减少不合格数据,一般分为两步
1、自动化代替手工台账
无纸化办公,让机器代替人工记录生产数据。比如进行数字化转型,iot、云计算、大数据等体系来支撑数据的自动标准化采集。
2、流程优化
企业流程梳理,前期调研应全面具体,首先问领导的需求(业务管控点)再结合具体业务需求点(业务流程完整性及标准化)。
往往在新系统或者新功能上线时会存在1-3个月的磨合期,一般高效的企业,会在一个月之内将线上化后,系统支撑不足的点暴露出来,并将流程固化下来了。
机器解决了效率和人工录入误差问题,标准化解决了数据是否能满足业务需求,减少垃圾数据产生。
2.3清洗不合格数据
在这个过程中也有两步:
1、业务清洗
通过前面的一步,我们对企业的业务有个较为深入的了解,这时也正是数据治理真正能发挥价值的阶段,经过的前期简单的“数据收集”。
我们会发现因很多客观和主观的因素发现现有的业务流转存在很多不合理的地方。如:为减少工作量和降低成本,会选择多个样品只打印一个标签,混检一次,这必然减少了工作量。
但正如核酸检测一样,当发现问题时,需要重新对里面的混批样进行抽检,相当于异常管控发现的时候就拉长了两倍,对于流程制造行业来说,一次异常造成的成本是前面单独检测成本的10倍还不止。

再看一个案例,在过去没有数字化手段时,整个异常管控闭环流程,需要1个多月才能完全处理。因为异常从发生、判定、修正、效果评估、重复性检查、效果验证整个过程相当复杂。常常会因为流程绩效的问题,导致整个流程闭环时间拉的很长,因此为促进业务发展,进行流程实时提醒,业务判定前移,将部分决策权下放来加速流程流转。
通过一系列的业务自我清洗,会让流程更优,业务流转更丝滑入扣。
2、数据清洗
数据清洗在过去的大数据建设过程中,大都认为是IT的问题的。认为这些都是IT才能去做的事情。但通过业务实践发现,IT的数据清洗手段真的只是工具而已。
在最近的数字化建设过程中,发现在实际应用过来发现两大类问题。
2.1数字化推进的不完整性
为了保证在异常情况(断网、断电、系统宕机)下业务“正常运转”,通常会保留一种手工的方式来处理异常。
如标签打印系统出问题了,允许人工EXCEL打印。事后将手工数据录入系统,如果操作人员对业务及系统熟悉,那数据的质量也是可以得到保障。
但实际情况下,往往人工的错误率会高达60-70%。因为对于高质量的数据应用,通常会因为录入的数据不合这个规范,那个制度导致数据不能用,如录入批次号,缺少了型号、年月日流水位数不对。如系统规范批号为:F1-20230407-WH503,在人工录入的时候一般会是F1-23047-WH503、F1-2023407-WH503、F1-2023047-WH503等等。

因此企业如果允许人工录入数据,需要在系统增加数据校验机制、通过流程来审核人工录入数据,审核完成后才允许数据进去系统等。
2.2不断挖掘的需求
以前我们经常说数据挖掘,其实需求实际上也是一步步挖掘出来的,从开始只需要简单的数据统计→数据分析→数据决策→数据AI提醒等。
这一套过程中,是因为我们将数据采集进来了,通过展示平台展示数据后,发现这些数据还很难去替代以前的线下数据统计,因此业务会针对线上的数据展示,提出比如需要将多个“相同”批次数据整合至一个批次,多个批次检测数据整合到一个批次,多个批次数据只显示一条数据,批次数据与标准比较自动判异等,当数据异常后自动推送至企业微信等实时性高的应用等。
如需要将1-H1-8-F1-4-08004-006CC、1-H1-8-F1-4-08004-006FC、1-H1-8-F1-4-08004-006HF多个批次的数据按上述要求进行数据清洗

多批次清洗

多检测项目清洗

异常实时推送
三、总结
因此数据治理工作更多的是一个管理的工作的。需要根据行业和业务需求,业务治理为主导来推进数据的治理,保障数据的质量,多产生好数据,从而辅助智能决策。下一节来谈谈,怎么让业务高热情的参与数据治理工作。
这篇关于数据治理-数据质量管理-Data governance Day1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







