本文主要是介绍ACL'22 | e-CARE: 可解释的因果推理数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
每天给你送来NLP技术干货!
论文名称:e-CARE: a New Dataset for Exploring Explainable Causal Reasoning
论文作者:杜理,丁效,熊凯,刘挺,秦兵
原创作者:杜理
出处:哈工大SCIR
1. 简介
因果推理是人类的一项核心认知能力。借助因果推理能力,人类得以理解已观测到的各种现象,并预测将来可能发生的事件。然而,尽管当下的各类因果推理模型已经在现有的因果推理数据集上取得了令人印象深刻的性能,然而,这些模型与人类的因果推理能力相比仍存在显著差距。
造成这种差距的原因之一在于,当下的因果推理模型往往仅能够从数据中捕获到经验性的因果模式,但是人类则能够进一步追求于对于因果关系的相对抽象的深入理解。如图1中例子所示,当观察到原因事件: 将石头加入盐酸造成结果:石头溶解 之后,人类往往不会停留在经验性地观察现象这一层面,而会进一步深入思考,为什么这一现象能够存在?通过种种手段,最终得到一个概念性的解释,即酸具有腐蚀性。值得注意的是,这一对于因果现象的概念性解释是超越具体的现象本身,能够解释一系列相关现象的。借助此类解释信息,模型将可能产生对于因果命题的更加深入的理解。
虽然这种概念性解释在因果推理过程中具有相当的重要性,迄今的因果推理数据集中尚未具备这一信息以支撑训练更强的、更接近人类表现的因果推理模型。为此,我们提供了一个人工标注的可解释因果推理数据集( explainable CAusal REasoning dataset, e-CARE)。e-CARE数据集包含超过2万个因果推理问题,这使得e-CARE成为目前最大的因果推理数据集。并且对于每个因果推理问题,提供了一个自然语言描述的,有关于因果关系为何能够成立的解释。下表提供了一个e-CARE数据集的例子。
依托于e-CARE数据集,在传统的多项选择式的因果推理任务之外,我们还进一步提出了一个因果解释生成任务,即给定一个因果事件对,模型需要为这个因果事件对生成合理的解释,并提出了一个新指标衡量解释生成的质量。
| Key | Value |
|---|---|
| Premise | Tom holds a copper block by hand and heats it on fire. |
| Ask-for | Effect |
| Hypothesis 1 | His fingers feel burnt immediately. (✔) |
| Hypothesis 2 | The copper block keeps the same. (✖) |
| Conceptual Explanation | Copper is a good thermal conductor. |
2. 基于e-CARE的因果推理相关任务
基于e-CARE数据集,我们提出了两个任务以评价模型因果推理能力:
因果推理任务
解释生成任务
2.1 因果推理:
这一任务要求模型从给定的两个候选hypothesis中选出一个,使得其与给定的premise构成一个合理的因果事实。例如,如下例所示,给定premise "Tom holds a copper block by hand and heats it on fire.", hypothesis 1 "His fingers feel burnt immediately."能够与给定premise构成合理的因果事件对。
{"index": "train-0","premise": "Tom holds a copper block by hand and heats it on fire.","ask-for": "effect", "hypothesis1": "His fingers feel burnt immediately.", "hypothesis2": "The copper block keeps the same.", "label": 1
}2.2 解释生成:
这一任务要求模型为给定的由<原因,结果>构成的因果事件对生成一个合理解释,以解释为何该因果事件对能够存在。例如, 给定因果事件对<原因: Tom holds a copper block by hand and heats it on fire. 结果: His fingers feel burnt immediately.>, 模型需要生成一个合理的解释,如"Copper is a good thermal conductor."。
{"index": "train-0", "cause": "Tom holds a copper block by hand and heats it on fire.","effect": "His fingers feel burnt immediately.","conceptual_explanation": "Copper is a good thermal conductor."
}3. 数据集统计信息
问题类型分布
| Ask-for | Train | Test | Dev | Total |
|---|---|---|---|---|
| Cause | 7,617 | 2,176 | 1,088 | 10881 |
| Effect | 7,311 | 2,088 | 1,044 | 10443 |
| Total | 14,928 | 4,264 | 2,132 | 21324 |
解释信息数量
| Overall | Train | Test | Dev |
|---|---|---|---|
| 13048 | 10491 | 3814 | 2012 |
4. 解释生成质量评价指标CEQ Score
当用于评价解释生成的质量时,经典的生成质量自动评价指标,如BLEU,Rough等仅从自动生成的解释与给定的人工标注的解释的文本或语义相似度来评判解释生成的质量。但是,理想的解释生成质量评价指标需要能够直接评价自动生成的解释是否恰当地解释了给定的因果事实。为此,我们提出了一个新的解释生成质量评价指标CEQ Score (Causal Explanation Quality Score)。
简言之,一个合理的解释,需要能够帮助预测模型更好理解因果事实,从而更加合理准确地预测给定事实的因果强度。其中因果强度是一个[0,1]之间的数值,衡量给定因果事实的合理性。因此,对于确证合理的因果事实,其因果强度应该等于1.
因此,我们可以通过衡量生成的解释能够为因果强度的度量带来何种程度的增益,来衡量解释生成的质量。因此,我们将CEQ定义为:
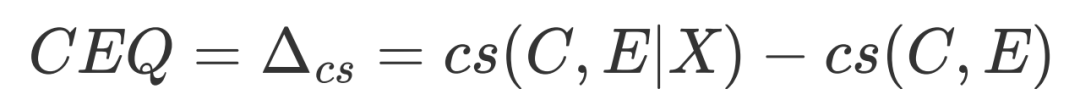
其中,和分别是原因与结果,是因果强度预测模型度量的原始的因果强度,是给定解释后,因果预测模型给出的因果强度。
值得注意的是,这一指标依赖于具体的因果强度预测方式的选取,以及如何将解释信息融入因果强度预测过程。在本文中,我们选择基于统计的、不依赖具体模型的因果强度预测方式CausalNet[5]。CausalNet能够依赖大语料上的统计信息,得到给定原因与结果间的因果强度。而为将解释信息融因果强度预测过程以得到,我们定义(其中+为字符串拼接操作):
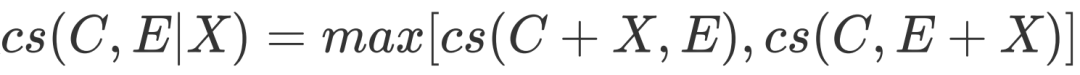
5. 数据集下载与模型性能评价
5.1 数据集下载
模型的训练与开发集可在以下链接下载: https://github.com/Waste-Wood/e-CARE/files/8242580/e-CARE.zip
5.2 模型性能评测
为提升方法结果的可比性,我们提供了leaderboard用以评测模型性能:https://scir-sp.github.io/
6. 实验结果
6.1 因果推理
表1 因果推理实验结果
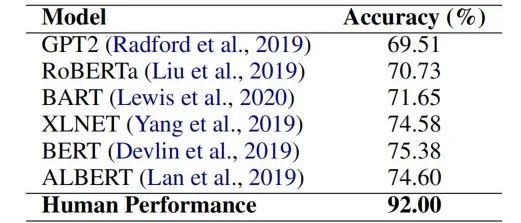
针对多项选择式的因果推理任务,我们利用一系列预训练语言模型(均为base-sized版本)进行了实验。我们使用准确率衡量模型性能。其中,ALBERT取得了最高性能,但是和人类表现(92%)仍有较大差距。这显示e-CARE所提供的因果推理任务仍为一相对具有挑战性的任务。
6.2 解释生成
表2 解释生成实验结果

为测试模型在给定因果事实后生成合理的解释的能力,我们利用经典的GRU-Seq2Seq模型以及GPT2进行了解释生成实验。其中,我们使用自动评价指标AVG-BLEU、ROUGH-l、PPL,以及人工评价衡量生成质量。由表2可得,虽然相比于GRU-Seq-Seq,GPT2性能有明显提高,但是和人类生成的解释质量相比仍存在巨大差距,尤其在人工评价指标上。这显示,深度理解因果事实,并为此生成合理解释仍是相当具有挑战性的任务。而无法深度理解因果事实也可能是阻碍当前的因果推理模型性能进一步提高的主要因素之一。另一方面,这也一定程度显示所提出的解释生成质量评价指标CEQ的合理性。
7. 潜在研究方向
7.1 作为因果知识库
因果知识对于多种NLP任务具有重要意义。因此,e-CARE中包含的因果知识可能能够提升因果相关任务上的模型性能。为了验证这一点,我们首先在e-CARE上微调了e-CARE模型,并将微调后的模型(记作BERTE)分别 迁移至因果抽取数据集EventStoryLine[1]、两个因果推理数据集BECauSE 2.0[2]和COPA[3],和一个常识推理数据集CommonsenseQA[4]上,并观察模型性能。如下表所示,e-CARE微调后的模型在四个因果相关任务上均表现出了更好性能。这显示e-CARE能够提供因果知识以支撑相关任务上的性能。
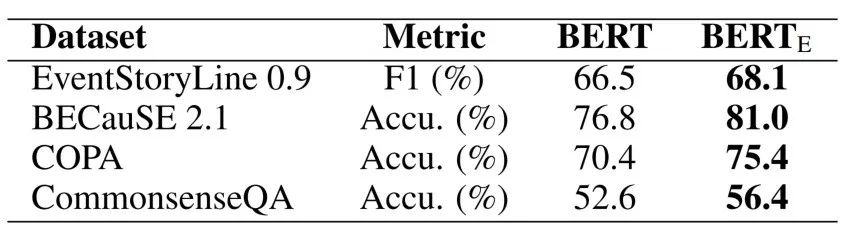
表3 知识迁移实验结果
7.2 支持溯因推理
前期研究将解释生成过程总结为一个溯因推理过程。并强调了溯因式的解释生成的重要性,因为它可以与因果推理过程相互作用,促进对因果机制的理解,提高因果推理的效率和可靠性。
例如,如下图所示,人们可能会观察到 C1: 将岩石加入盐酸中 导致 E1: 岩石溶解。通过溯因推理,人们可能会为上述观察提出一个概念性解释,即酸具有腐蚀性。之后,可以通过实验验证,或者外部资料来确认或纠正解释。通过这种方式,关于因果关系的知识可以被引入到因果推理过程中。如果解释得到证实,它可以通过帮助解释和验证其他相关的因果事实,来进一步用于支持因果推理过程,例如 C2:将铁锈加入硫酸可能导致 E2:铁锈溶解。这显示了概念解释在学习和推断因果关系中的关键作用,以及 e-CARE 数据集在提供因果解释并支持未来对更强大的因果推理系统的研究中可能具有的意义。
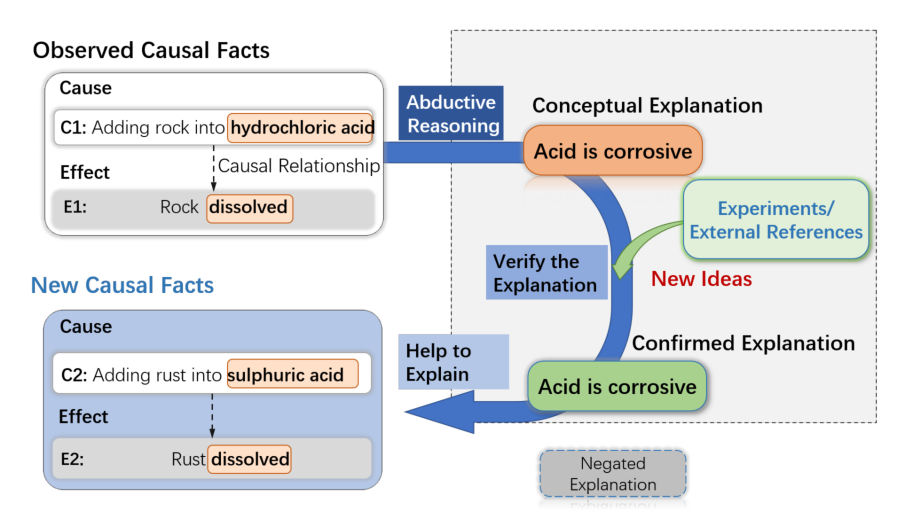
图1 溯因推理与因果推理关系示意图
8. 结论
本文关注于因果推理问题中的可解释性。针对这一点,本文标注了一个可解释因果推理数据集e-CARE,这一数据集包含21K因果推理问题,并为每个问题提供了一个解释因果关系为何能够成立的自然语言形式的解释。依托于这一数据集,我们进一步提出了一个因果推理和一个因果生成任务。实验显示,当前的预训练语言模型在这两个任务上仍面临较大困难。
欢迎大家共同推动因果推理领域的研究进展!
参考文献
[1] Caselli T, Vossen P. The event storyline corpus: A new benchmark for causal and temporal relation extraction. Proceedings of the Events and Stories in the News Workshop. 2017.
[2] Dunietz J, Levin L, Carbonell J G. The BECauSE corpus 2.0: Annotating causality and overlapping relations. Proceedings of the 11th Linguistic Annotation Workshop. 2017.
[3] Roemmele M, Bejan C A, Gordon A S. Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning. AAAI spring symposium: logical formalizations of commonsense reasoning. 2011.
[4] Talmor A, Herzig J, Lourie N, et al. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2019.
[5] Luo Z, Sha Y, Zhu K Q, et al. Commonsense causal reasoning between short texts. Fifteenth International Conference on the Principles of Knowledge Representation and Reasoning. 2016.
本期责任编辑:刘 铭
本期编辑:彭 湃
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
这篇关于ACL'22 | e-CARE: 可解释的因果推理数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




