本文主要是介绍基于OpenVINO在英特尔开发套件上实现眼部追踪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:汕头大学 罗毅成
本文将以训练一个眼部追踪AI 小模型为背景,介绍从 Pytorch 自定义网络模型,到使用 OpenVINO™ NNCF 量化工具优化模型,并部署到英特尔开发套件的流程。
本项目已开源:RedWhiteLuo/HeadEyeTrack (github.com)
开发环境: Windows 11 + Pycharm。模型训练平台为 12700H,部署平台为英特尔开发套件
英特尔开发套件介绍
此开发人员套件采用英特尔® 赛扬® 处理器 N 系列,已通过 Ubuntu* Desktop 和 OpenVINO™ 工具套件的预验证,有助于在教育方面取得更多成绩。这一组合为学生提供了在 AI、视觉处理和物联网领域培养编程技能和设计解决方案原型所需的性能。
开始的开始当然是开箱啦~~




一、确定整体的流程
在 V1.0 版本中,我将眼部图片直接用来训练神经网络,发现结果并不理想,经过检查后发现由于头部的朝向会朝着目光方向偏转,导致训练集中的样本分布差异很小,由此导致结果并不理想,于是在V1.5 版本中采用了复合的模型结构,以此引入头部的位置信息:
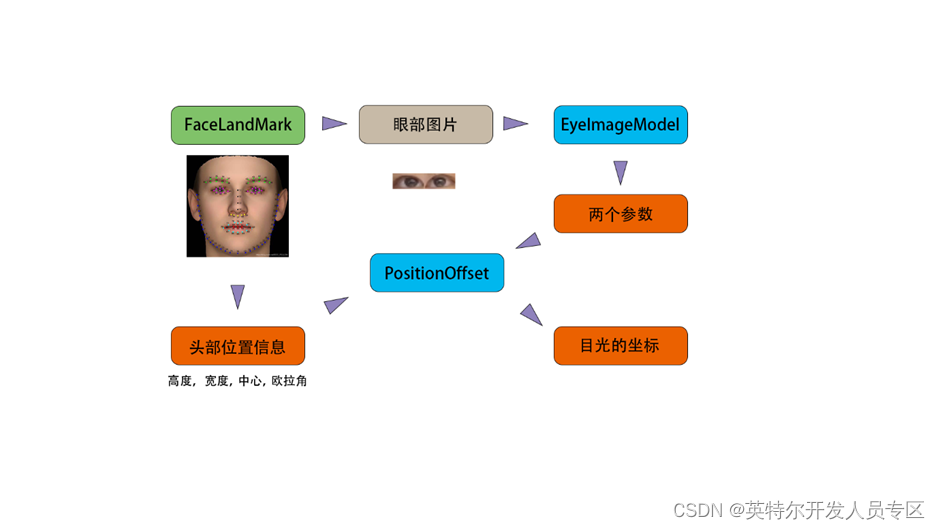
二、 模型结构
以网络上已有的项目 ”lookie-lookie“ 为参考,通过查看其源码可以得知该项目所使用的网络结构, 我们可以以此为基础进行修改。
因此,在Pytroch 中我们可以继承 nn.Module 并定义如下的模型:
class EyeImageModel(nn.Module):def __init__(self):super(EyeImageModel, self).__init__()self.model = Sequential(# in-> [N, 3, 32, 128]BatchNorm2d(3),Conv2d(3, 2, kernel_size=(5, 5), padding=2),LeakyReLU(),MaxPool2d(kernel_size=(2, 2), stride=(2, 2)),Conv2d(2, 20, kernel_size=(5, 5), padding=2),ELU(),Conv2d(20, 10, kernel_size=(5, 5), padding=2),Tanh(),Flatten(1, 3),Dropout(0.01),Linear(10240, 1024),Softplus(),Linear(1024, 2),)def forward(self, x):return self.model(x)class PositionOffset(nn.Module):def __init__(self):super(PositionOffset, self).__init__()self.model = Sequential(Conv2d(1, 32, kernel_size=(2, 2), padding=0),Softplus(),Conv2d(32, 64, kernel_size=(2, 2), padding=1),Conv2d(64, 64, kernel_size=(2, 2), padding=0),ELU(),Conv2d(64, 128, kernel_size=(2, 2), padding=0),Tanh(),Flatten(1, 3),Dropout(0.01),Linear(128, 32),Sigmoid(),Linear(32, 2),)def forward(self, x):return self.model(x)class EyeTrackModel(nn.Module):def __init__(self):super(EyeTrackModel, self).__init__()self.eye_img_model = EyeImageModel()self.position_offset = PositionOffset()def forward(self, x):eye_img_result = self.eye_img_model(x[0])end = torch.cat((eye_img_result, x[1]), dim=1)end = torch.reshape(end, (-1, 1, 3, 3))end = self.position_offset(end)return end
由两个小模型组成一个复合模型,EyeImageModel 负责将眼部图片转换成两个参数,在EyeTrackModel中与头部位置信息组成一个 N*1*3*3 的矩阵,在PositionOffset 中进行卷积操作,并将结果返回
三、训练数据集的获取
定义好了网络结构后,我们需要去获取足够的数据集,通过 Peppa_Pig_Face_Landmark 这个项目可以很容易地获取脸部 98个关键点。
610265158/Peppa_Pig_Face_Landmark: A simple face detect and alignment method, which is easy and stable. (github.com)
通过让目光跟随鼠标位置,实时获取图片与鼠标位置并进行保存,我们便可以快捷地获取到数据集。
为了尽量保持有效信息的占比,我们先分别截取两个眼睛的图片后 再拼接成一张图片,即删去鼻梁部分的位置,再进行保存,通过这种方法可以一定程度减少由头部偏转带来眼部图片的过度畸变。
def save_img_and_coords(img, coords, annot, saved_img_index):img_save_path = './dataset/img/' + '%d.png' % saved_img_indexannot_save_path = './dataset/annot/' + '%d.txt' % saved_img_indexcv2.imwrite(img_save_path, img)np.savetxt(annot_save_path, np.array([*coords, *annot]))print("[INFO] | SAVED:", saved_img_index)def trim_eye_img(image, face_kp):""":param image: [H W C] 格式人脸图片:param face_kp: 面部关键点:return: 拼接后的图片 [H W C] 格式"""l_l, l_r, l_t, l_b = return_boundary(face_kp[60:68])r_l, r_r, r_t, r_b = return_boundary(face_kp[68:76])left_eye_img = image[int(l_t):int(l_b), int(l_l):int(l_r)]right_eye_img = image[int(r_t):int(r_b), int(r_l):int(r_r)]left_eye_img = cv2.resize(left_eye_img, (64, 32), interpolation=cv2.INTER_AREA)right_eye_img = cv2.resize(right_eye_img, (64, 32), interpolation=cv2.INTER_AREA)return np.concatenate((left_eye_img, right_eye_img), axis=1)
这一步将保存的文件命名为 index.png 和 index.txt,并保存在/img 和 /annot两个子文件夹中。
需要注意的是,使用cv2.VideoCapture() 的时候,获取的图片默认是 (640,480)大小的。经过FaceLandMark 后得到的眼部图片过于模糊,因此需要手动指定摄像头的分辨率:
vide_capture = cv2.VideoCapture(1)
vide_capture.set(cv2.CAP_PROP_FRAME_WIDTH, HEIGHT)
vide_capture.set(cv2.CAP_PROP_FRAME_HEIGHT, WEIGHT)
四、简单的DataLoader
由于每个样本图片的大小只有 32 x 128, 相对来说比较小,因此就干脆直接全部加载到内存中
def EpochDataLoader(path, batch_size=64):""":param path: 数据集的根路径:param batch_size: batch_size:return: epoch_img, epoch_annots, epoch_coords:
[M, batch_size, C, H, W], [M, batch_size, 7], [M, batch_size, 2]"""epoch_img, epoch_annots, epoch_coords = [], [], []all_file_name = os.listdir(path + "img/") # get all file name -> listfile_num = len(all_file_name)batch_num = file_num // batch_sizefor i in range(batch_num): # how many batchcurr_batch = all_file_name[batch_size * i:batch_size * (i + 1)]batch_img, batch_annots, batch_coords = [], [], []for file_name in curr_batch:img = cv2.imread(str(path) + "img/" + str(file_name)) # [H, W, C] formatimg = img.transpose((2, 0, 1))img = img / 255 # [C, H, W] formatdata = np.loadtxt(str(path) + "annot/" + str(file_name).split(".")[0] + ".txt")annot_mora, coord_mora = np.array([1920, 1080, 1920, 1080, 1, 1, 1.4]), np.array([1920, 1080])annot, coord = data[2:]/annot_mora, data[:2]/coord_morabatch_img.append(img)batch_annots.append(annot)batch_coords.append(coord)epoch_img.append(batch_img)epoch_annots.append(batch_annots)epoch_coords.append(batch_coords)epoch_img = torch.from_numpy(np.array(epoch_img)).float()epoch_annots = torch.from_numpy(np.array(epoch_annots)).float()epoch_coords = torch.from_numpy(np.array(epoch_coords)).float()return epoch_img, epoch_annots, epoch_coords
这个函数可以一次性返回所有的样本。
五、定义损失函数并训练
由于网络输出的结果是N 个二维坐标,因此直接使用 torch.nn.MSELoss() 作为损失函数
def eye_track_train():img, annot, coord = EpochDataLoader(TRAIN_DATASET_PATH, batch_size=TRAIN_BATCH_SIZE)batch_num = img.size()[0]model = EyeTrackModel().to(device).train()loss = torch.nn.MSELoss()optim = torch.optim.SGD(model.parameters(), lr=LEARN_STEP)writer = SummaryWriter(LOG_SAVE_PATH)trained_batch_num = 0for epoch in range(TRAIN_EPOCH):for batch in range(batch_num):batch_img = img[batch].to(device)batch_annot = annot[batch].to(device)batch_coords = coord[batch].to(device)# infer and calculate lossoutputs = model((batch_img, batch_annot))result_loss = loss(outputs, batch_coords)# reset grad and calculate grad then optim modeloptim.zero_grad()result_loss.backward()optim.step()# save loss and print infotrained_batch_num += 1writer.add_scalar("loss", result_loss.item(), trained_batch_num)print("[INFO]: trained epoch num | trained batch num | loss ", epoch + 1, trained_batch_num, result_loss.item())if epoch % 100 == 0:torch.save(model, "../model/ET-" + str(epoch) + ".pt")# save modeltorch.save(model, "../model/ET-last.pt")writer.close()print("[SUCCEED!] model saved!")
训练过程中每100轮都会保存一次模型,训练结束后也会进行保存。
六、通过导出为ONNX 模型
通过torch.onnx.export() 我们便可以很方便导出onnx模型
def export_onnx(model_path, if_fp16=False):""":param model_path: 模型的路径
:param if_fp16: 是否要将模型压缩为 FP16 格式
:return: 模型输出路径"""model = torch.load(model_path, map_location=torch.device('cpu')).eval()print(model)model_path = model_path.split(".")[0]dummy_input_img = torch.randn(1, 3, 32, 128, device='cpu')dummy_input_position = torch.randn(1, 7, device='cpu')torch.onnx.export(model, [dummy_input_img, dummy_input_position], model_path + ".onnx", export_params=True)model = mo.convert_model(model_path + ".onnx", compress_to_fp16=if_fp16) # if_fp16=False, output = FP32serialize(model, model_path + ".xml")print(EyeTrackModel(), "\n[FINISHED] CONVERT DONE!")return model_path + ".xml"
七、使用Openvino 的 NNCF 工具进行int8量化
Neural Network Compression Framework (NNCF) provides a new post-training quantization API available in Python that is aimed at reusing the code for model training or validation that is usually available with the model in the source framework, for example, PyTorch* or TensroFlow*. The API is cross-framework and currently supports models representing in the following frameworks: PyTorch, TensorFlow 2.x, ONNX, and OpenVINO.
Post-training Quantization with NNCF (new) — OpenVINO™ documentation
通过Openvino 的官方文档我们可以知道:Post-training Quantization with NNCF 分为两个子模块:
- Basic quantization
- Quantization with accuracy control
def basic_quantization(input_model
def basic_quantization(input_model_path):# prepare required datadata = data_source(path=DATASET_ROOT_PATH)nncf_calibration_dataset = nncf.Dataset(data, transform_fn)# set the parameter of how to quantizesubset_size = 1000preset = nncf.QuantizationPreset.MIXED# load modelov_model = Core().read_model(input_model_path)# perform quantizequantized_model = nncf.quantize(ov_model, nncf_calibration_dataset, preset=preset, subset_size=subset_size)# save modeloutput_model_path = input_model_path.split(".")[0] + "_BASIC_INT8.xml"serialize(quantized_model, output_model_path)def accuracy_quantization(input_model_path, max_drop):# prepare required datacalibration_source = data_source(path=DATASET_ROOT_PATH, with_annot=False)validation_source = data_source(path=DATASET_ROOT_PATH, with_annot=True)calibration_dataset = nncf.Dataset(calibration_source, transform_fn)validation_dataset = nncf.Dataset(validation_source, transform_fn_with_annot)# load modelxml_model = Core().read_model(input_model_path)# perform quantizequantized_model = nncf.quantize_with_accuracy_control(xml_model,calibration_dataset=calibration_dataset,validation_dataset=validation_dataset,validation_fn=validate,max_drop=max_drop)# save modeloutput_model_path = xml_model_path.split(".")[0] + "_ACC_INT8.xml"serialize(quantized_model, output_model_path)def export_onnx(model_path, if_fp16=False):""":param model_path: the path that will be converted:param if_fp16: if the output onnx model compressed to fp16:return: output xml model path"""model = torch.load(model_path, map_location=torch.device('cpu')).eval()print(model)model_path = model_path.split(".")[0]dummy_input_img = torch.randn(1, 3, 32, 128, device='cpu')dummy_input_position = torch.randn(1, 7, device='cpu')torch.onnx.export(model, [dummy_input_img, dummy_input_position], model_path + ".onnx", export_params=True)model = mo.convert_model(model_path + ".onnx", compress_to_fp16=if_fp16) # if_fp16=False, output = FP32serialize(model, model_path + ".xml")print(EyeTrackModel(), "\n[FINISHED] CONVERT DONE!")return model_path + ".xml"
这里需要注意的是 nncf.Dataset(calibration_source, transform_fn) 这一部分,calibration_source 所返回的必须是一个可迭代对象,每次迭代返回的是一个训练样本 [1, C, H, W],transform_fn 则是对这个训练样本作转换(比如改变通道数,交换 H, W) 这里的操作是进行归一化,并转换为numpy。
八、量化后的性能提升
测试的硬件平台 12700H
这种小模型通过OpenVINO NNCF 方法量化后可以获得很明显的性能提升:
benchmark_app -m ET-last_ACC_INT8.xml -d CPU -api async<br/>
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 226480 iterations
[ INFO ] Duration: 60006.66 ms
[ INFO ] Latency:
[ INFO ] Median: 3.98 ms
[ INFO ] Average: 4.18 ms
[ INFO ] Min: 2.74 ms
[ INFO ] Max: 38.98 ms
[ INFO ] Throughput: 3774.25 FPS
benchmark_app -m ET-last_INT8.xml -d CPU -api async<br/>
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 513088 iterations
[ INFO ] Duration: 60002.85 ms
[ INFO ] Latency:
[ INFO ] Median: 1.46 ms
[ INFO ] Average: 1.76 ms
[ INFO ] Min: 0.82 ms
[ INFO ] Max: 61.07 ms
[ INFO ] Throughput: 8551.06 FPS
九、在英特尔开发套件上进行部署
由于英特尔开发套件上已经安装好了Python 因此只需要再安装 OpenVINO即可
下载英特尔发行版 OpenVINO 工具套件 (intel.cn)
然后在项目的根目录执行 python eye_track.py 即可查看到网络的推理结果,如下图所示

性能概览:

在iGPU上的运行性能

在CPU上运行的性能
十、总结
OpenVINO™ 提供了一个方便快捷的开发方式,通过几个核心的API便可实现模型转换和模型量化。
英特尔开发套件 基于 x86架构提供了一个高通用、高性能的部署平台,体积小巧,非常适合项目的最终部署。
自训练 Pytorch 模型在通过 OpenVINO™ 的模型优化工具优化后,使用 OpenVINO™ Runtime 进行推理,对于如上文所示的小模型可以获得巨大的性能提升,并且推理过程简单清晰。在开发板上推理仅需几个核心函数便可实现基于自训练 Pytorch 模型的推理。
这篇关于基于OpenVINO在英特尔开发套件上实现眼部追踪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






