本文主要是介绍非理工科编程零基础文科生秒懂python学习笔记:pandas库dataframe核心基础数据选取loc与iloc,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

#本数据纯属虚构,如有雷同实属巧合
本次拜读的是:

目录
创建
读取
使用loc索引读取dataframe:
使用iloc读取数据表格dataframe
""" dataframe是python数据分析基础中的核心, 这位按字面意义可理解为数据表格、数据框架, 她跟excel的table很相似, 由三部分组成: 行索引,称为index; 列索引,称为column; 数据内容。 她的每一列都是一个series对象。 """
创建
使用字典创建dataframe,并设置索引号
import pandas as pd #导入pandas库,缩写为pd
print("\n使用字典创建dataframe,并设置索引号:")
characters01 = pd.DataFrame({"name" : ["zhongli","yanfei", "jiangjun","tuoma","xinhai","chongyun","xingqiu","anbo","xiangling"],"age" : [17,18,19,21,29,15,19,14,17],"score" : [98780,36895,54100,20523,36895,54100,20523,36895,54100]
}, index = [1,2,3,4,"num5","第6",7,8,9])
print(characters01)

索引index的结果对应第一列,如果不设置index的参数,默认使用整数类型
print("\n\n索引index的结果对应第一列,如果不设置index的参数,默认使用整数类型:")
characters02 = pd.DataFrame({"name" : ["zhongli","yanfei", "jiangjun","tuoma","xinhai","chongyun","xingqiu","anbo","xiangling"],"age" : [17,18,19,21,29,15,19,14,17],"score" : [98780,36895,54100,20523,36895,54100,20523,36895,54100]
})
print(characters02)
可以使用columns参数定义列名
print("\n\n可以使用columns参数定义列名:")
characters03 = pd.DataFrame({"name" : ["zhongli","yanfei", "jiangjun","tuoma","xinhai","chongyun","xingqiu","anbo","xiangling"],"age" : [17,18,19,21,29,15,19,14,17],"score" : [98780,36895,54100,20523,36895,54100,20523,36895,54100]
}, index = [1,2,3,4,"num5","第6",7,8,9], columns=["score", "name", "age", "newcol"])
print(characters03)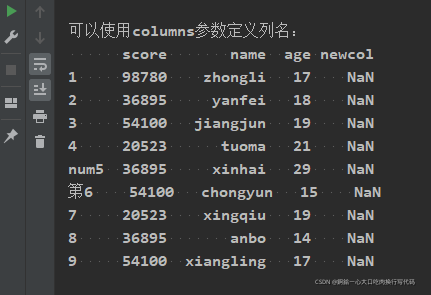
如果某一字段没有数据会自动变成NaN
print("\n\n如果某一字段没有数据会自动变成NaN:")
gdp = pd.DataFrame({'2018': {'GDP': "1%", '人口': 3},'2019': {'GDP': "3%", '人口': 2},'2020': {'GDP': "2%", '人口': 1},'2021': {'人口': 1},'2022': {'GDP': "4%"}
})
print(gdp)
实现多层嵌套索引
print("\n\n实现多层嵌套索引:")
values = [[10, "A"], [11, "B"], [13, "C"], [10, "D"], [12, "E"], [12, "F"],
]
salesData = pd.DataFrame(values, columns=["销量", "型号"], index=[["一月", "一月", "二月", "二月", "三月", "三月"],["huawei", "apple", "huawei", "apple", "huawei", "apple"],
])
print(salesData)
通过元组直接实现MultiIndex多层嵌套索引
print("\n\n通过元组直接实现MultiIndex多层嵌套索引:")
index = pd.MultiIndex.from_tuples([('f', 1), ('f', 2), ('w', 2)], names=['e', 'c'])
df01 = pd.DataFrame({"a01": [400, 500, 600],"b02": [702, 805, 903],"c03": [101, 110, 120]
}, index=index)
print(df01)
读取
使用索引读取dataframe
print("\n\n使用索引读取dataframe:")
characters04 = pd.DataFrame({"name" : ["zhongli","yanfei", "jiangjun","tuoma","xinhai","chongyun","xingqiu","anbo","xiangling"],"age" : [17,18,19,21,29,15,19,14,17],"score" : [98780,36895,54100,20523,36895,54100,20523,36895,54100]
}, index = [1,2,3,4,5,6,7,8,9])
print("\n\n读取name列:\n", characters04['name'])
print("\n\n读取name和age列:\n", characters04[['name', 'age']])
print("\n\n读取前两行的所有内容:\n", characters04[:2])
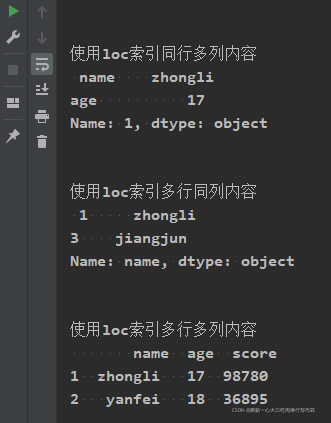
print("\n\n使用loc索引读取dataframe:")
print("\n\n使用loc索引第一行所有内容\n", characters04.loc[1])
print("\n\n使用loc索引同行多列内容\n", characters04.loc[1, ['name', "age"]])
print("\n\n使用loc索引多行同列内容\n", characters04.loc[[1, 3], "name"])
print("\n\n使用loc索引多行多列内容\n", characters04.loc[1:2])
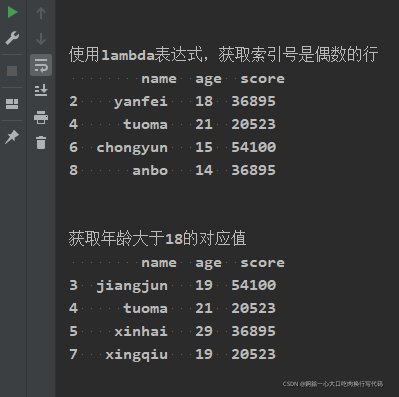
print("\n\n使用lambda表达式,获取索引号是偶数的行\n", characters04.loc[lambda x: x.index % 2 == 0])
print("\n\n获取年龄大于18的对应值\n", characters04.loc[lambda x: x['age'] > 18 ])
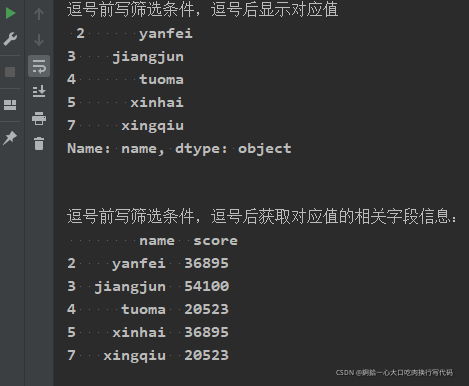
print("\n\n逗号前写筛选条件,逗号后显示对应值\n", characters04.loc[characters04['age'] > 17, 'name'])
print("\n\n逗号前写筛选条件,逗号后获取对应值的相关字段信息:\n", characters04.loc[characters04['age'] > 17, ['name', 'score']])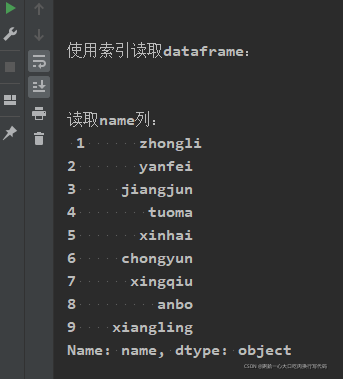


使用loc索引读取dataframe:


使用loc读取多层索引dataframe
print("\n\n使用loc读取多成索引dataframe:")
salesData = pd.DataFrame([[10, "A"], [11, "B"], [13, "C"], [10, "D"], [12, "E"], [12, "F"],
], columns=["销量", "型号"], index=[["六月", "六月", "七月", "七月", "八月", "八月"],["huawei", "apple", "huawei", "apple", "huawei", "apple"],
])
print("\n\n输出整个表:\n",salesData)
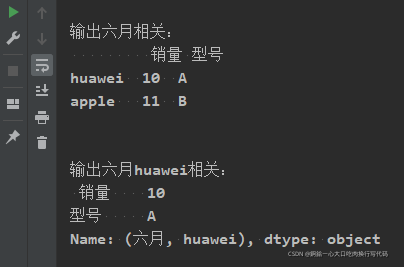
print("\n\n输出六月相关:\n",salesData.loc['六月'])
print("\n\n输出六月huawei相关:\n",salesData.loc['六月', 'huawei']) 
使用iloc读取数据表格dataframe
print("\n\n使用iloc读取数据表格dataframe:")
df001 = pd.DataFrame( [[39,35940,8,703], [51,45468,4,815], [84, 83694, 4, 894], [57, 46540, 2, 973], [19, 20316, 3, 436], [46, 53104, 6, 735]] ,index=list(range(0, 12, 2)), #定义显示行索引起始为0,结束为12,步长为2columns=list(range(0, 8, 2)))#定义显示列索引起始为0,结束为8,步长为2
print("\n\n输出整个表:\n",df001)
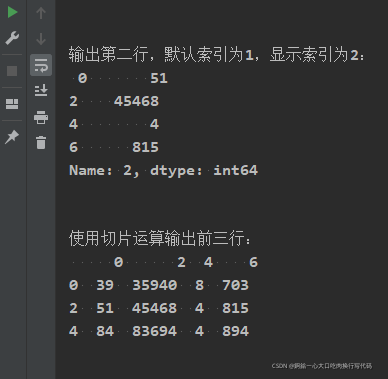
print("\n\n输出第二行,默认索引为1,显示索引为2:\n",df001.iloc[1])
print("\n\n使用切片运算输出前三行:\n",df001.iloc[:3])
print("\n\n使用切片超出范围也不会报错:\n",df001.iloc[3:100])
# print("\n\n但如果读取某个不存在的索引会报错:\n",df001.iloc[4, 8, 9])
print("\n\n选择第二行第二列的一个数据:\n",df001.iloc[1, 1])
print("\n\n连续选择第二到五行的第三到第四列的数据:\n",df001.iloc[1:5, 2:4])
print("\n\n跳选第二、四、六行的第二、四列的数据:\n",df001.iloc[[1, 3, 5], [1, 3]])
print("\n\n使用冒号表示获取一整行:\n",df001.iloc[1:3, :])
print("\n\n使用冒号表示获取一整列:\n",df001.iloc[:, 1:3])



使用iterrows遍历读取每一行
print("\n\n使用iterrows遍历读取每一行:")
characters05 = pd.DataFrame({"name" : ["zhongli","yanfei", "jiangjun","tuoma","xinhai","chongyun","xingqiu","anbo","xiangling"],"age" : [17,18,19,21,29,15,19,14,17],"score" : [98780,36895,54100,20523,36895,54100,20523,36895,54100]
}, index = [1,2,3,4,5,6,7,8,9])
for index, row in characters05.iterrows():print("索引index: {0}".format(index))print("角色{0}, 年龄{1}, 分数{2}".format(row['name'], row['age'], row['score']))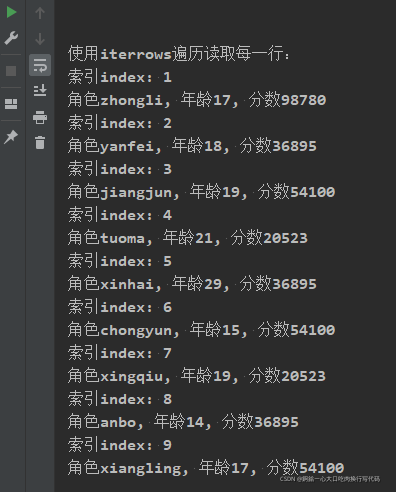
使用items遍历读取每一列
print("\n\n使用items遍历读取每一列:")
characters06 = pd.DataFrame({"name" : ["zhongli","yanfei", "jiangjun","tuoma","xinhai","chongyun","xingqiu","anbo","xiangling"],"age" : [17,18,19,21,29,15,19,14,17],"score" : [98780,36895,54100,20523,36895,54100,20523,36895,54100]
}, index = [1,2,3,4,5,6,7,8,9])
for label, item in characters06.items():print(label)print(item)

这篇关于非理工科编程零基础文科生秒懂python学习笔记:pandas库dataframe核心基础数据选取loc与iloc的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





