本文主要是介绍linux下 tcp接受数据不全_Linux下流水线式的TCP中继代理是如何提高吞吐的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CDN如何加速动态的内容? 如果答案是每次都回源站,那岂不是违背了 “CDN就是让内容离用户更近” 的承诺了吗?
答案确实是每次都回源站。但是另一方面,CDN并非仅仅是让内容离用户更近,更高层面上,CDN代表了一种颠覆性的架构,除了数据离用户的距离上的考量之外,更多地是打碎了TCP对IP路由网络的信任,IP做不好的事情,TCP自己来做。
非常具有讽刺意味,加入拥塞控制算法以后的TCP从来都没有优雅地应对过拥塞,相反在加入了越来越多的所谓 拥塞控制算法 之后,TCP违背最初设计理念的地方越来越多,事实证明,TCP根本就做不好长距离的端到端的拥塞控制,是的,完全做不到!
既然做不好长距离的端到端控制,那就做短距离的呗。
更具讽刺意味的是,人们似乎只要听到TCP代理,就会想到一个字,慢! 然而非也!
两个TCP端节点之间如果架一个TCP中继代理,整个的吞吐会提高。
你可能觉得有点不可思议,貌似这个论述违背了常识,但是确实如此。我不准备用理论去论述这个结论,只给出下面的图示就能基本明白:
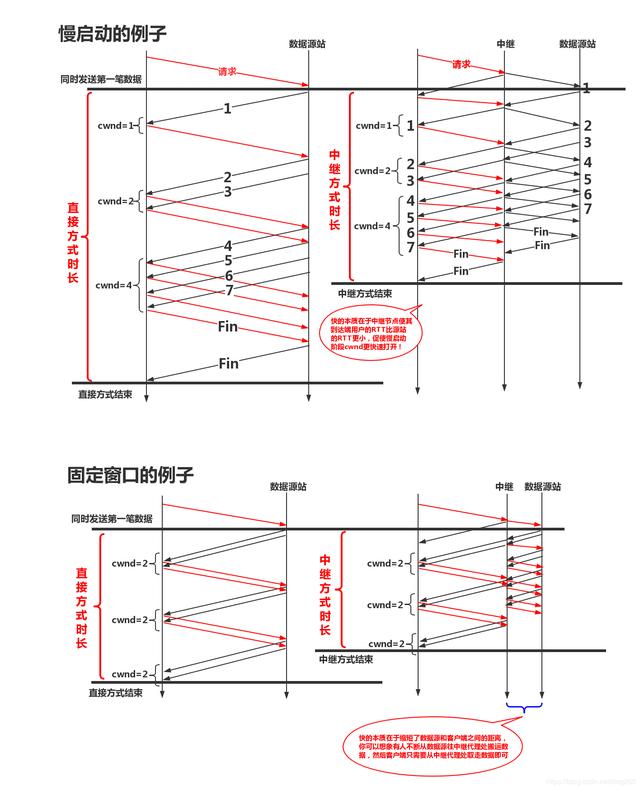
这就是一种流水线的工作方式,它在TCP传输中之所以能工作地如此有效,是因为TCP的RTT对传输吞吐影响远远大于多增加一个中继代理而增加的额外处理时间对性能的影响,也就是说在下面的公式中:
TCP时延 = 传播时延 + 排队时延 + 处理时延
和传播时延相比,处理时延可以忽略!
因此在增加了TCP中继代理之后,虽然增加了单个数据包的处理时延,但是由于流水线操作对传播时延的优化,这样做依然是值得的!上图中仅仅以两个流水线级作为例子,流水线级数,即TCP中继代理越多,吞吐就会越高。
至于说为了流水线可以提高吞吐,我想了解CPU流水线处理的都应该明白吧。其本质就是 让系统的不同组成部分可以同时处理一件事情的不同阶段, 这样整个系统便没有空闲的部件,所有都在忙,当然效能最高!效能我们可以理解为吞吐。
值得强调的是,流水线并不会提高单程处理( 未使用流水线前 )的性能,相反由于增加了流水线逻辑,它会降低单程处理性能,流水线只是能提高吞吐而已,即可以让系统的输出按照流水线级数的频率来进行,比如说如果有10级流水线,那么系统吞吐理论上将会比不使用流水线时多出10倍。
当然,虽然理论上设计无穷级的流水线会让系统吞吐无穷大,但是每增加一级的流水线都会平添 单程处理时延, 最终流水线带来的好处不足以弥补平添的时延,就得不偿失了,Intel的Pentium 4处理器就是这样下课的。
- 【流水线级数越来越多时,吞吐率的增加是一个挤的过程,越来越慢越来越困难】
- 【流水线级数越来越多时,处理延时的增加是线性递增的过程,越来越大】
现在说回TCP和流水线的关系。
TCP在设计的时候,就是一个流水线协议。
我们从最简单的 停/等协议 说起。停等协议的时序图是下面这样的:
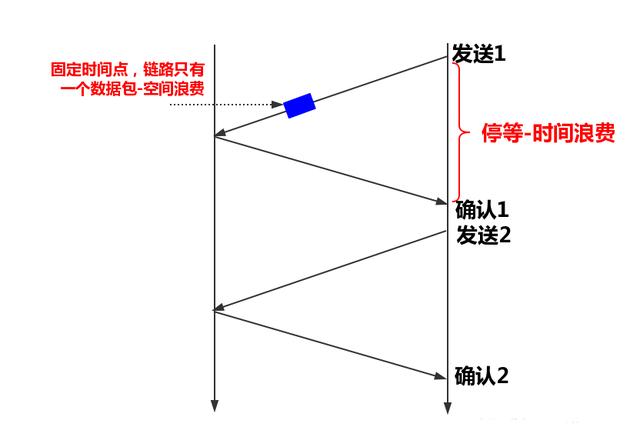
我们可以看到,这是一个典型的单程操作,在一个数据包的ACK未返回期间,链路是静默的,显然这在吞吐效率上是非常低的。整个RTT只能传输一个数据包,时间和空间均造成了巨大的浪费。TCP的设计者当然不会采用这种方式来设计协议。
不管是最初的端到端滑动窗口协议,还是后来引入的拥塞控制机制,均采用了一种流水线的思想来设计协议(参考一下GBN协议和SR协议,以及TCP和QUIC的类比)。
为了避免时间(数据包传输的时间)和空间(数据包在单位时间内通过的距离)的静默浪费,可以把时间和空间切割成背靠背的小段,流水线的意思是说, 前面一秒发出一个数据包到达前面一个位置,那么后面一秒就可以发出另一个数据包占据前面数据包后面的位置。 最终效果就是,在端到端数据传输路径上,每一个位置都有数据包在向前传输,它们在时间轴上依次向前推进:
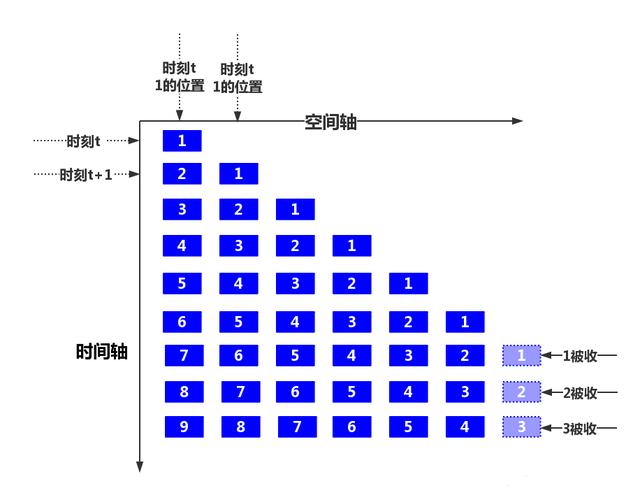
换句话说,在数据的接收端看来,数据包的到达是 源源不断的 !
这个过程在经典的《TCP/IP详解 卷1:协议》的 “20.7 成块数据的吞吐量” 章节有非常详细的描述!画出其时序图就是下面的样子:
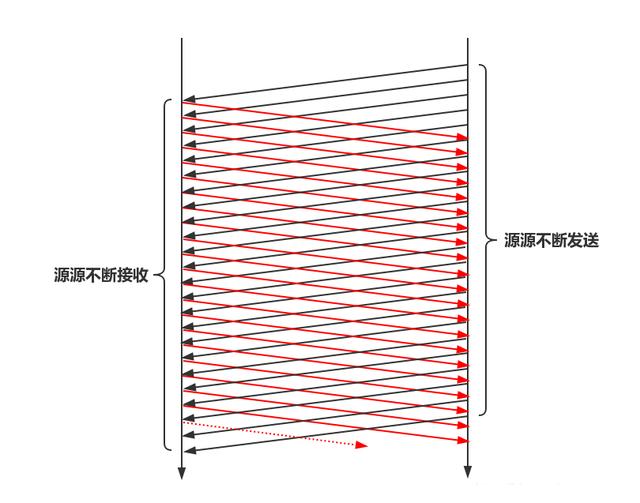
可见,不管端到端的距离多远,只要管道达到这种满载的状态,假设全世界的网络数据包传输速率都一样为光速且发送数据包的间隔都一样,即带宽一致的情况下,那么在接收端看来,数据包到达的频率均是一样的,这意味着,我们无法通过增加TCP中继代理的方式来提高吞吐率。看样子是否定我在本文最初给出的结论。怎么办?
这非常容易解释,因为理论上看来,TCP本来就被设计成了流水线协议,既然它本来就是流水线的,再基于同样的思想引入TCP中继,造同样效果的流水线,当然是无济于事了。
真的是这样吗?
理论上是一回事,现状是另一回事。我们还得回到TCP实现的现状来看问题。事实上,直到现在,在现实中,TCP从来没有按照理想中的流水线方式工作过。也就是说,TCP真正跑起来时其行为并不像理论上的推论所描述的那般。因此,流水线当然不能好好的工作了。
我们看看到底是哪里出了问题。
首先,我们从《TCP/IP详解 卷1:协议》的20.7小节里看到,TCP数据包是以相同的时间间隔发送的,即它是Pacing发送的,然而现实中,在BBR之前,大多数的TCP实现均是以主机延时在一个while循环中把一窗口的数据包突发出去的。我们将其归为:
- Burst行为
其次,由于上述第1点的Burst行为,中间节点的排队将会加剧,于是产生了大量AQM算法,产生了TCP发送端和AQM之间的博弈。此后的TCP传输的难题就是 能发送多少数据 的难题,即计算拥塞控制窗口cwnd的难题。网络传输行为是一个动态的行为,这意味着cwnd是无法准确预估的,我们归纳为:
- cwnd测不准
最终,TCP传输的流水线特征就不可能呈现了。我们知道,在TCP中,由于带宽的无法预估,初始cwnd不得不从一个非常小的值开始试探,而慢启动期间cwnd增长的速度和RTT是相关的,所以就为增加TCP中继代理提供了优化的空间。
另外,我们知道TCP大多数的拥塞控制算法对丢包是非常敏感的,丢包会造成cwnd的急剧降低,而长距离的TCP端点之间丢包更容易发生,所以增加TCP中继代理可以缩短每一段子链路的RTT进而减少丢包的影响。
通过以上的篇幅,我想下面的疑问应该是解开了:
即便是TCP的cwnd从1开始慢启动,它的cwnd早晚增长到数据包会填满整个BDP的,RTT越大,cwnd就越大,cwnd的值就是BDP,所以为什么增加TCP中继代理依然是可以提高吞吐率呢???
答案似乎很明显:
- TCP理论上的流水线行为依赖于固定的Pacing发送,然而现实中的实现多数是Burst发送;
- 复杂且动态的链路数据包收敛汇聚行为使得TCP传输并不稳定,排队,丢包造成巨大的影响。
以下是实际中TCP传输的时序图的样子:

所以说,既然TCP的流水线模型工作的并不好,那么我们就有必要去显式地通过增加中间代理节点让数据包流水线化,这就是本文最开始说明的。
说了这么多流水线以及TCP的历史上的一些的事情,其实这是在为TCP中继代理为什么能提高系统吞吐率作一个理论上的保证。有了这个理论上的保证或者说依据,我们就可以采用多级代理的方式来重构TCP连接了。这其中有很多值得深思的好玩的东西。
采用中继会减少排队和丢包
我们知道TCP是端到端协议,其对中间链路是无感知的,拥塞控制机制中的cwnd如何能相对精确预知,一直是一个世界级难题。可以肯定的是,TCP两端相距越远,RTT越大,链路状况越是难以获取,误判越是会增多,而误判的后果就是排队或者丢包。
采用TCP中继代理后,原本长距离的链路被切分成了多个段, 每一个小段的可控性会更高些,且RTT的减少本身就会提高吞吐。我们关注下面两点即可:
- 越短的链路越不容易丢包,越不容易拥塞,RTT越小超时带来的cwnd陡降的影响越容易恢复。
- 可以针对每一个小段进行定向优化,比如提高初始cwnd等。
采用中继可以让选路策略更加灵活
这个无需多说,TCP/IP协议栈越往上层走,可以利用的策略就越丰富,见下图:
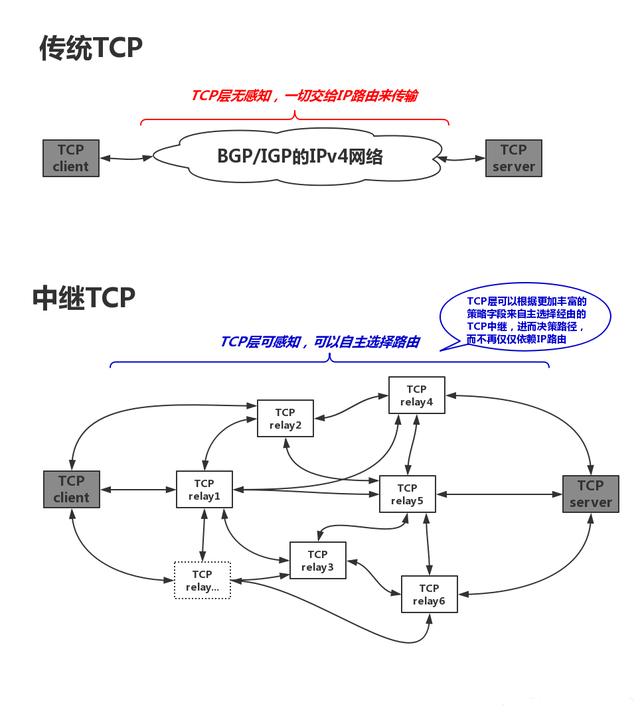
可以说,在TCP连接之间加中继TCP代理,好处多多,使得TCP更加可控,更不容易跑飞(TCP在长RTT情况下,是非常不可控的一个协议),然而这也许违背了TCP最初设计者的初衷,不过这又能怎样呢?难道设计者就一定是正确的吗?当初的范.雅格布森的TCP pacing管道不是从来都没有践行过吗?人类理解不了上帝,不然人不就成了上帝了吗?
TCP中继代理是一个非常非常通用的架构,事实上当我写完这篇文章后,我发现其实CDN静态加速,CDN动态加速,SDWAN等当代互联网传输技术中,大量采用了这种方式,不管你把它们叫什么,它的本质永远都是这个,即 TCP中继代理技术可以为TCP引入良好的短距离端到端传输控制!换句话说,多级TCP中继代理为CDN提供了可以优化内容传输的依据!
- 对于静态内容,良好的短距离传输控制 侧重在最后一公里这最后一段;
- 对于动态内容,良好的短距离传输控制 侧重在从第一段到最后一段的所有环节的流水线配合。
如果我们把TCP设计之初的流水线理念看作是一种乌托邦式的流水线(竟然相信毫无传输保证的IP网络!)的话,那么TCP中继代理流水线就是一个真实的流水线。
需要C/C++ Linux服务器架构师学习资料私信“资料”(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
这篇关于linux下 tcp接受数据不全_Linux下流水线式的TCP中继代理是如何提高吞吐的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



