本文主要是介绍【08-JVM面试专题-JVM运行时数据区堆的结构是怎么划分?为什么分代设计呢?为什么要Survivor区?只有Eden不行吗?为什么要两个Survivor区?为什么Eden:s0:s1是8:1:1】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
JVM运行时数据区堆的结构是怎么划分?为什么分代设计呢?为什么要Survivor区?只有Eden不行吗?为什么要两个Survivor区?为什么Eden:s0:s1是8:1:1?分配担保机制?堆内存分配过程详细的讲讲?

JVM运行时数据区堆的结构是怎么划分?为什么分代设计呢?为什么要Survivor区?只有Eden不行吗?为什么要两个Survivor区?为什么Eden:s0:s1是8:1:1?分配担保机制?堆内存分配过程详细的讲讲?你掌握的怎么样呢?
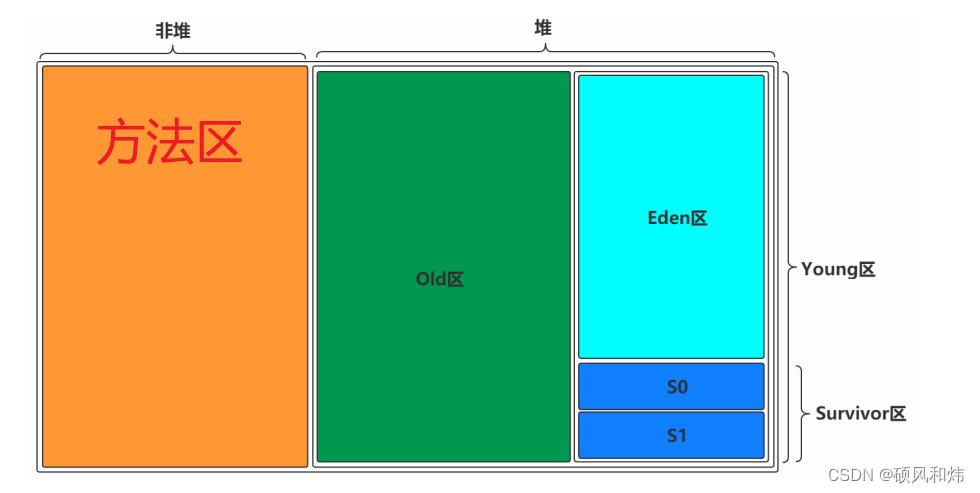
堆的内存布局?
一块是非堆区(方法区),一块是堆区
堆区分为两大块,一个是Old区,一个是Young区
Young区分为两大块,一个是Survivor区(S0+S1),一块是Eden区
S0和S1一样大,也可以叫From和To区
堆为什么会进行分代设计?
方法区在逻辑上又叫非堆
将内存按照对象的生命周期的长短分为Old区和Young区,
但90%+以上的对象都是朝生夕死的。
年轻代年龄为15后,去到Old区。
对象的分代年龄,存储在对象的对象头中的Markwork中。
如果细心的小伙伴就会问了,对象的结构是什么样的呢?
聪明的我早知道你要问这个问题了,所以我也早早的准备好了,我们下回分解,哈哈。。。
为什么需要Survivor区?只有Eden不行吗?
如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。这样一来,老年代很快被填满,触发Major GC(因为Major GC一般伴随着Minor GC,也可以看做触发了FullGC)。
老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长得多。
执行时间长有什么坏处?频发的Full GC消耗的时间很长,会影响大型程序的执行和响应速度。
所以Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代。
为什么需要两个Survivor区?
为了解决Young区内存空间的不连续性、空间碎片?
将Young区继续分为Eden区和Survivor区,Survivor区分为s0和s1,
Survivor区分为俩个主要是为了能够清空另外一个空间。
最大的好处就是解决了碎片化。也就是说为什么一个Survivor区不行?第一部分中,我们知道了必须设置Survivor区。假设现在只有一个Survivor区,我们来模拟一下流程:刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。永远有一个Survivor space是空的,另一个非空的Survivor space无碎片。
为什么Eden:s0:s1是8:1:1?
Eden区域越小,就会不停的触发我们的GC,GC是会不断的消耗我们的性能。
新生代中的可用内存:复制算法用来担保的内存为9:1
可用内存中Eden:S1区为8:1
即新生代中Eden:S1:S2 = 8:1:1
现代的商业虚拟机都采用这种收集算法来回收新生代,IBM公司的专门研究表明,新生代中的对象大概98%是“朝生夕死”的。
这个就是一个经验值,大量的实验得出的最佳结论。
什么是分配担保机制?
一些大对象的产生,在Eden区中是没有位置存放的,这个时候会有一个担保机制的出现,Old区作为这个大对象的担保,即使这个对象的年龄是没有达到15的,依旧可以被存储到Old区中,但是,这样的大对象的产生,是非常不好的,可能会随时出发Full GC,对我们的内存空间的产生可谓是灾难性的。
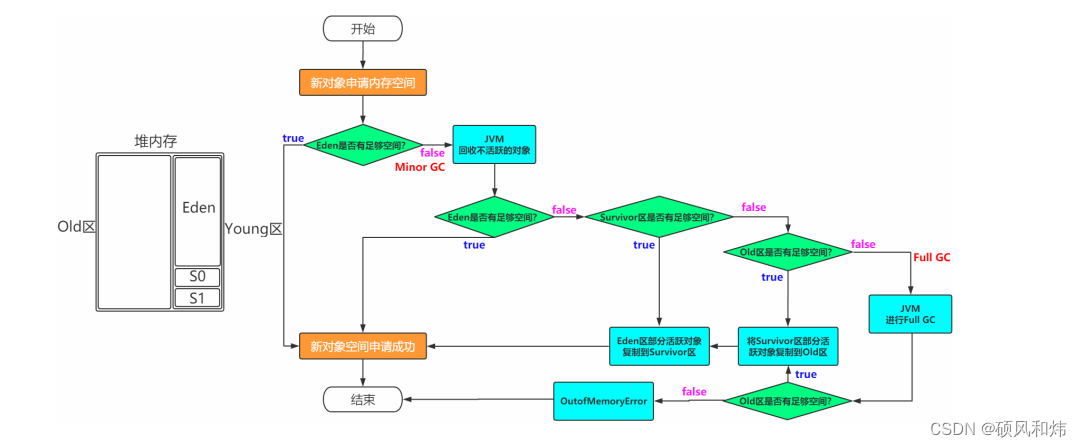
对象创建后在堆中分配内存的过程?
细心一点,看一下下面这个图就会非常清晰的知道对象创建后在堆中分配内存的过程。
总结:
JVM知识在面试过程中非常高频,大家一定要牢牢掌握,如果以上文章有帮助到你,希望可以点个关注,留下属于你的足迹,比心!我们下节再见哦。
这篇关于【08-JVM面试专题-JVM运行时数据区堆的结构是怎么划分?为什么分代设计呢?为什么要Survivor区?只有Eden不行吗?为什么要两个Survivor区?为什么Eden:s0:s1是8:1:1】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









