本文主要是介绍两种Ncode多轴随机振动疲劳分析流程建立,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
产品结构在随机载荷下的疲劳寿命评估,一直是工程上关心的重点,通常是对垂向、横向及纵向三个方向进行检测试验,本文主要介绍如何在Ncode中建立两种多轴随机振动疲劳分析流程。
1、本次示例是根据标准IEC61373-2010设置随机振动疲劳功率谱密度,检验某一设备长寿命情况。
2、通过有限元计算得到Ncode所识别的输入文件,如Hypermesh的计算文件需是.op2格式(本文使用的格式),ABAQUS的计算文件是.odb。
3、第一种设置的完整多轴随机振动疲劳分析需要至少四个模块:FEinput、VibrationAnalysis、MultiColumn及FEOutput(个人操作习惯,在Ncode里查看结果不是很方便,导出到HyperView中查看结果)。
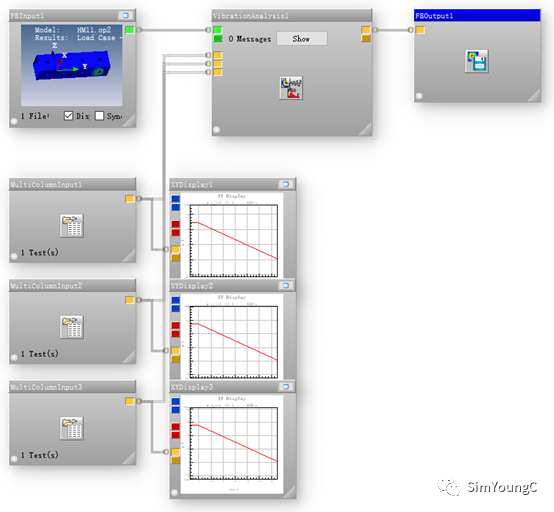
这里着重介绍VibrationAnalysis中如何设置多通道。
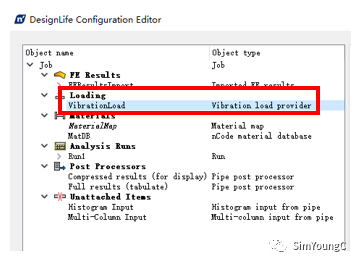
① 右击VibrationAnalysis模块选择Advanced Edit.选择面板中的Loading,此时仅有一个VibrationLoad。
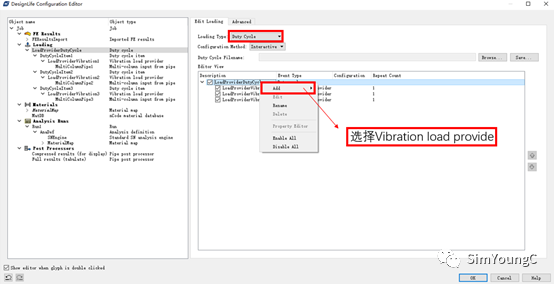
② 将Loading Type中的Vibration换成Duty Cycle,在下方窗口中右击LoadProviderDutyCycle增加3个Vibration Load Provide。
③ 右击左边导航栏的LoadProviderDutyCycle增加列表通道,这是为外部导入的列表拓展接口,其余两个相同操作。退出编辑窗口会发现VibrationAnalysis的黄色输入接口变成4个,第一个是默认接口可以删掉,其他接口是刚才新创建的,为了不混淆接口输入的内容建议从第二个黄色接口按顺序与导入的数据相连,方便载荷步与振动输入相对应。
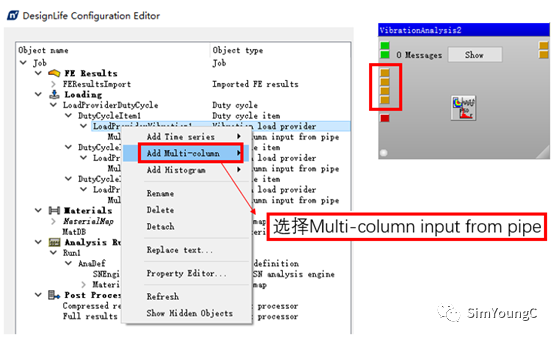
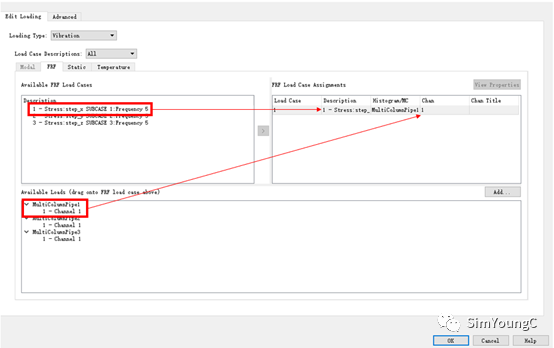
④ 再次进入VibrationAnalysis的Advanced Edit.组合载荷步与振动输入,需注意对应情况,否则可能得到不合理的结果。
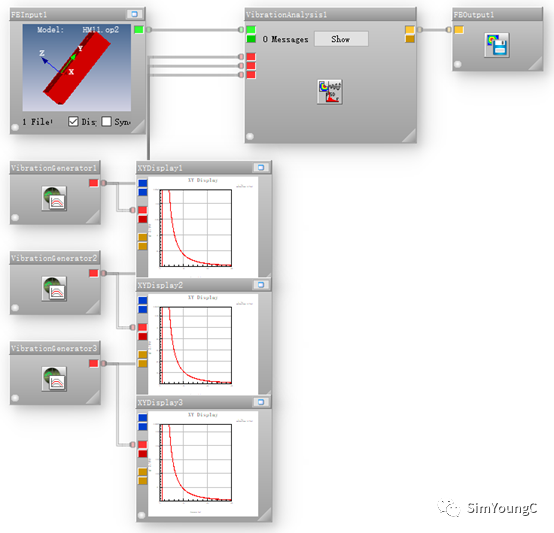
4、第二种设置的完整多轴随机振动疲劳分析需要至少四个模块:FEinput、VibrationAnalysis、VibrationGenerator及FEOutput。
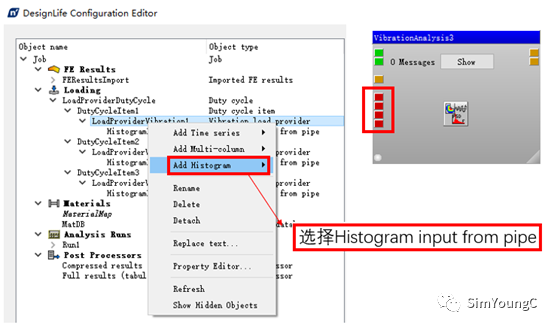
与第一种设置不同点在于③步,将添加Multi-Column换成Histogram。
5、再次回到VibrationAnalysis的Advanced Edit.编辑重复次数与持续时间。根据标准里的规定,三个方向的持续时间都必须满足5h,因此重复次数默认设为1,持续时间换算成秒为18000s。

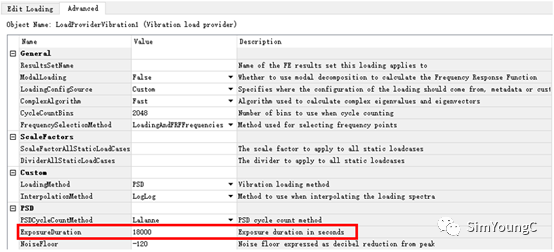
这里也可以设置重复次数为18000,时间设为1s,两种方式是等价的,得到的结果是相同的,如果都采用默认的方式即都为1,那么在结果数据处理上需除以18000。
6、眼尖的小伙伴可能在两种设置流程里会发现PSD谱有很大不同,那这会不会导致结果不同呢?答案是结果一致的,可能会存在少许差异,是因为外部列表输入的数据与Ncode软件自身生成的PSD谱存在数据精度不一致导致的。
原文链接,更多仿真学习资源可以关注公众号 SimYoungChttps://mp.weixin.qq.com/s?__biz=Mzg4MTY3MzkxOQ==&mid=2247483679&idx=1&sn=06317794cf495bcf8fe0249d048c8b2c&chksm=cf6312cff8149bd9c1432d64d474c95ea75b67b219f8d825fbdd0482426cb9f2677e80104362&token=1398480349&lang=zh_CN#rd
这篇关于两种Ncode多轴随机振动疲劳分析流程建立的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








