本文主要是介绍昇腾CANN 7.0 黑科技:DVPP硬件加速训练数据预处理,友好解决Host CPU预处理瓶颈,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在NPU/GPU上进行模型训练计算,为了充分使用计算资源,一般采用批量数据处理方式,因此一般情况下为提升整体吞吐率,batch值会设置的比较大,常见的batch数为256/512,这样一来,对数据预处理处理速度要求就会比较高。对于AI框架来说,常见的应对方式是采用多个CPU进程并发处理,比如PyTorch框架的torchvision就支持多进程并发,使用多个CPU进程来进行数据预处理,以满足与NPU/GPU的计算流水并行处理。
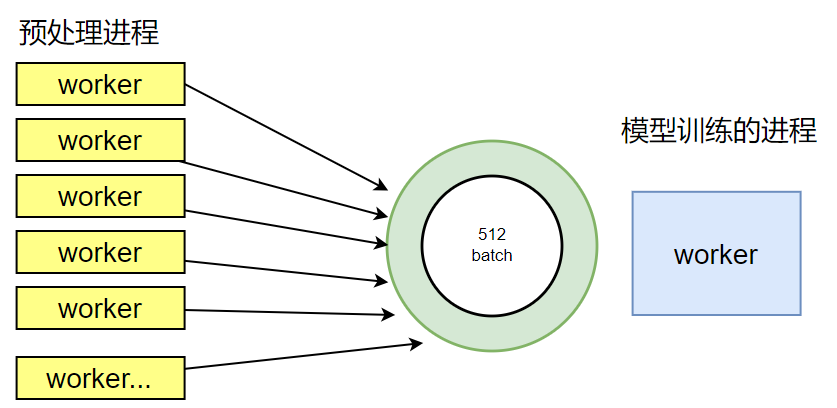
然而,随着NPU算力和性能的倍速提升,host CPU数据预处理过程逐渐成为性能瓶颈。模型端到端训练时间会因为数据预处理的瓶颈而拉长,这种情况下,如何解决性能瓶颈,提升端到端模型执行性能呢?
下面来看一个torchvision的预处理过程:
# Data loading codetraindir = os.path.join(args.data, 'train')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])train_dataset = datasets.ImageFolder(traindir,transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize,]))大家是不是对这些接口功能很熟悉?实际上,NPU上的DVPP也能进行类似处理,诸如图片解码、图片缩放、翻转处理等。DVPP是NPU上专门用于数据预处理的模块,跟NN计算是完全独立的。那么,如何让DVPP接管torchvision的预处理逻辑呢?很简单,两行代码轻松搞定:
import torchvision_npu # 导入torchvision_npu包# Data loading codetraindir = os.path.join(args.data, 'train')normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])torchvision_npu.set_image_backend('npu') # 设置图像处理后端为nputrain_dataset = datasets.ImageFolder(traindir,transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize,]))是不是很方便?AI算法工程师不需要修改torchvision的处理流程,不需要了解DVPP接口实现,也不需要去写C/C++代码,而这些全都是torchvision_npu的功劳。torchvision_npu中重新实现了functional.py,在每个预处理接口中,判断如果是npu类型的数据,则走npu的处理逻辑:
if img.device.type == 'npu':_assert_image_npu(img)return F_npu.resize(img, size=size, interpolation=interpolation.value)functional_npu.py内部调用npu的resize算子进行处理,接着通过AscendCL接口,调用DVPP硬件处理:
return torch.ops.torchvision.npu_resize(img, size=sizes, mode=mode)
return torch.ops.torchvision.npu_resize(img, size=sizes, mode=mode)
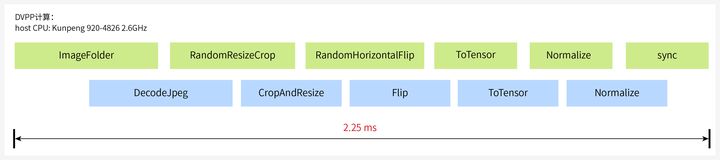
下面来看下替换之后的性能如何。以ImageNet中最常见的分辨率375*500的jpeg图片为例,CPU上执行预处理操作需要6.801ms:

使用DVPP不但能加速数据预处理,还能异步执行host下发任务和device任务,整个流程只需要2.25ms,单张图片处理节省了60%+的时间。
在ResNet50训练过程中,512batch数据处理只需要1.152 s,预处理多进程处理场景下性能优势更加明显。
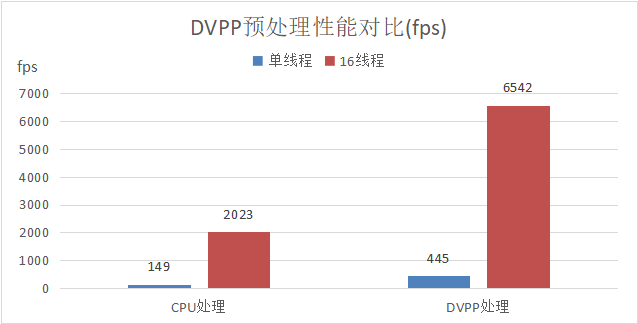
基于Atlas 800T A2 训练服务器,ResNet50使用DVPP加速数据预处理,单P只需要6个预处理进程即可把NPU的算力跑满;而使用CPU预处理,则需要12个预处理进程才能达到相应的效果,大大减少了对host CPU的性能依赖。
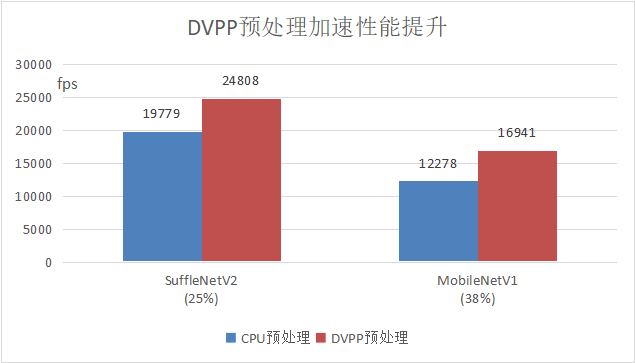
典型网络场景,基于Atlas 800T A2 训练服务器,在CPU预处理成为性能瓶颈的情况下,使用DVPP预处理加速即可获得整网训练速度显著提升,其中ShuffleNetV2整网性能提升25%,MobileNetV1提升38%。
预处理使用独立的硬件加速器DVPP加速,可以有效降低对Host CPU的依赖,避免CPU性能受限导致NPU性能无法发挥。同时使用NPU上独立的DVPP硬件加速器进行预处理,可以与NN并行处理互不影响,数据在device内可以自闭环。DVPP预处理加速是在训练场景下的第一次使能,补齐了NPU训练预处理性能短板。
昇腾CANN内置的预处理算子是比较丰富的,后续在继续丰富torchvision预处理算子库的同时,也会进一步提升预处理算子的下发和执行流程,让流水处理的更好,减少数据处理的时间,持续提升昇腾CANN的产品竞争力,满足更广泛的业务场景诉求。
这篇关于昇腾CANN 7.0 黑科技:DVPP硬件加速训练数据预处理,友好解决Host CPU预处理瓶颈的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







