本文主要是介绍【Hadoop】8.MapReduce框架原理-MapTask和ReduceTask的工作机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MapTask工作机制
MapTask工作机制一共分为:Read阶段,Map阶段,Collect阶段,溢写阶段,Combine阶段
ps: 来自尚学堂ppt
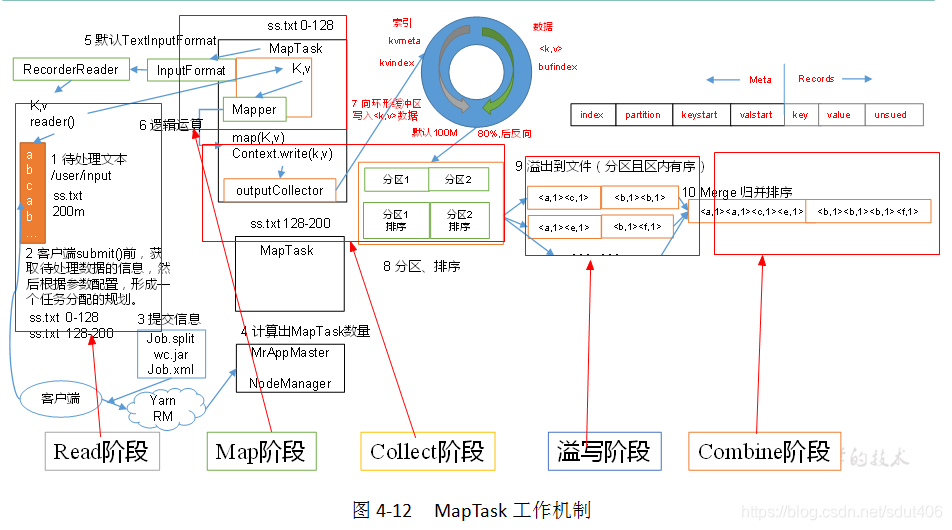
- Read阶段: MapTask通过用户编写的ReacordReader,从输入Insplit中解析出一个个key/value。
- Map阶段: 该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value
- Collect收集阶段: 在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它将会生成key/value分区(调用Patittioner),并写入一个环形内存缓冲区
- Spill阶段: 即溢写阶段,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要将数据进行一次本地排序(快速排序),并在必要时对数据进行压缩,合并等操作
- Combine阶段: 当所有数据处理完成后,MapTask对所有临时文件进行一次合并(归并合并),以确保最终只会生成 一个数据。
当所有的数据处理完,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
当进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
Spill阶段详情:
- 利用快速排序算法对缓存区内的数据进行排序,排序方式为先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集一起,且同一个分区所有数据按照key有序。
- 按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果 用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
- 将分区数据的元信息写到内存索引数据结构SplillRecord中,其中每个分区的元信息包括在临时文件中的偏移量,压缩前数据大小和压缩后的数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
ReduceTask的工作机制
ReduceTask工作机制分为:Copy阶段,Merge阶段,Sort阶段,Reduce阶段。
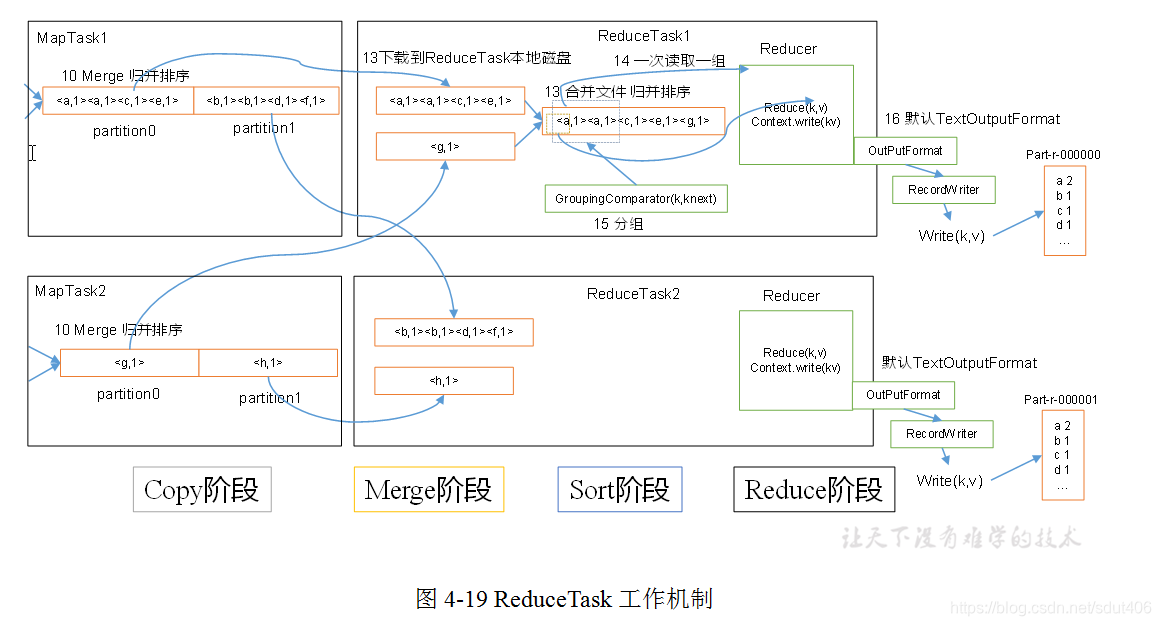
- Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
- Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
- Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
- Reduce阶段:reduce()函数将计算结果写到HDFS上。
设置ReduceTask并行度
MapTask并行度由切片决定,ReduceTask并行度可以直接指定个数
job.setNumReduceTasks(4);
注意事项:

这篇关于【Hadoop】8.MapReduce框架原理-MapTask和ReduceTask的工作机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









