本文主要是介绍【原理】预训练模型之自然语言理解--RoBERTa,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RoBERTa: A Robustly Optimized BERT Pretraining Approach
从模型结构上讲,相比BERT,RoBERTa基本没有什么创新,它更像是关于BERT在预训练方面进一步的探索。其改进了BERT很多的预训练策略,其结果显示,原始BERT可能训练不足,并没有充分地学习到训练数据中的语言知识。
图1展示了RoBERTa主要探索的几个方面,并这些方面进行融合,最终训练得到的模型就是RoBERTa。
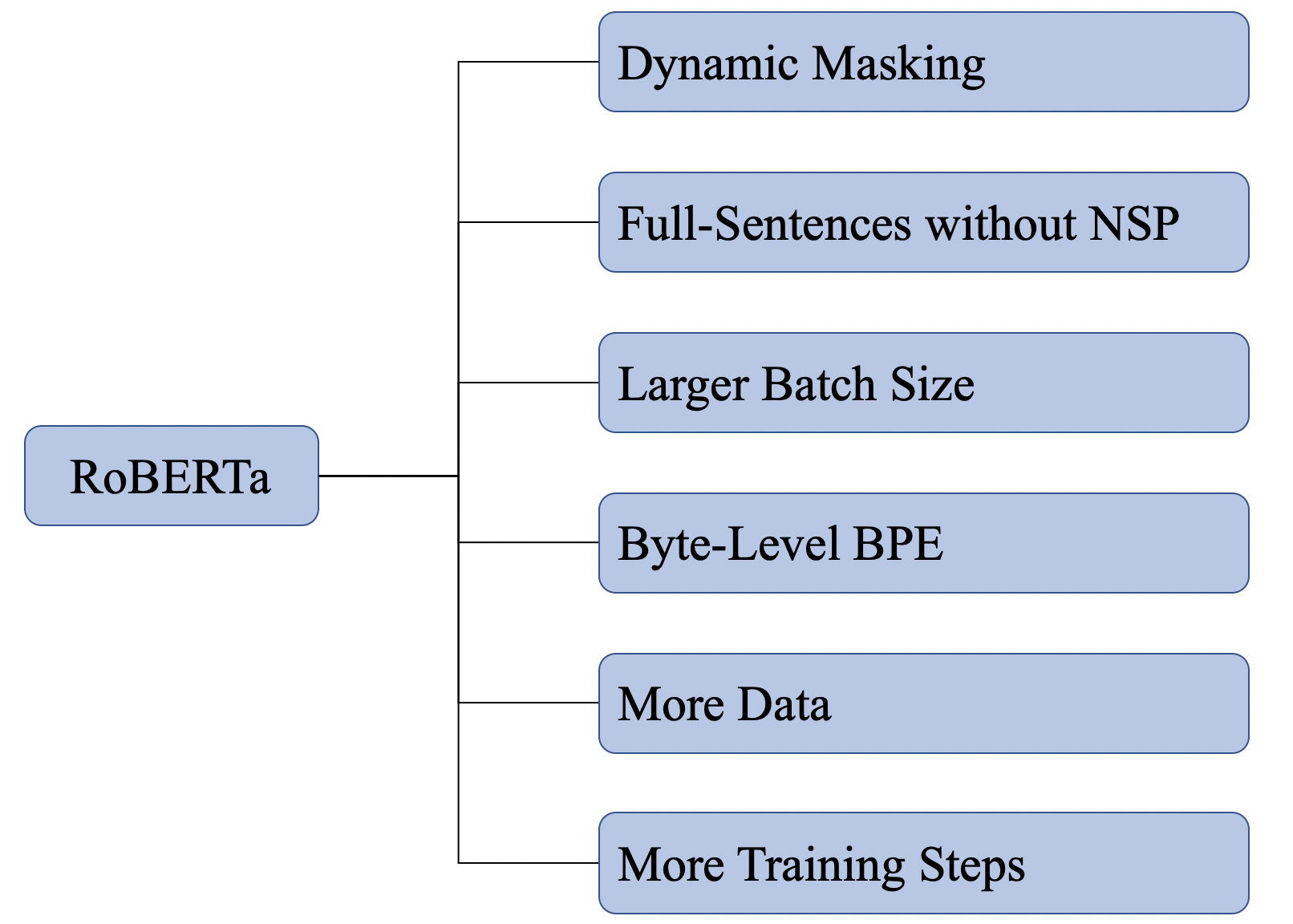
1. Dynamic Masking
BERT中有个**Masking Language Model(MLM)**预训练任务,在准备训练数据的时候,需要Mask掉一些token,训练过程中让模型去预测这些token,这里将数据Mask后,训练数据将不再变化,将使用这些数据一直训练直到结束,这种Mask方式被称为Static Masking。
如果在训练过程中,期望每轮的训练数据中,Mask的位置也相应地发生变化,这就是Dynamic Masking,RoBERTa使用的就是Dynamic Masking。
在RoBERTa中,它具体是这么实现的,将原始的训练数据复制多份,然后进行Masking。这样相同的数据被随机Masking的位置也就发生了变化,相当于实现了Dynamic Masking的目的。例如原始数据共计复制了10份数据,共计需要训练40轮,则每种mask的方式在训练中会被使用4次。
2. Full-Sentences without NSP
BERT中在构造数据进行NSP任务的时候是这么做的,将两个segment进行拼接作为一串序列输入模型,然后使用NSP任务去预测这两个segment是否具有上下文的关系,但序列整体的长度小于512。
然而,RoBERTa通过实验发现,去掉NSP任务将会提升down-stream任务的指标,如图2所示。
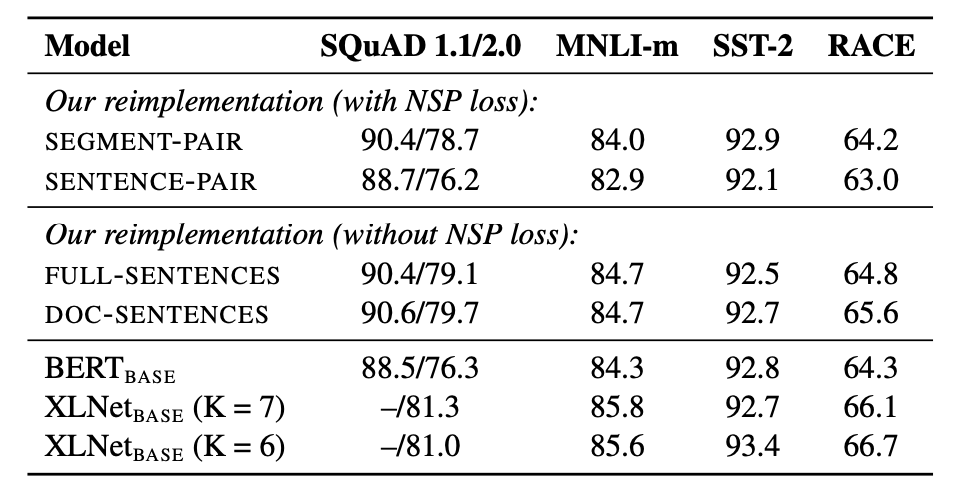
其中,SEGMENT-PAIR、SENTENCE-PAIR、FULL-SENTENCES、DOC-SENTENCE分别表示不同的构造输入数据的方式,RoBERTa使用了FULL-SENTENCES,并且去掉了NSP任务。这里我们重点讨论一下FULL-SENTENCES输入方式,更多详情请参考RoBERTa。
FULL-SENTENCES表示从一篇文章或者多篇文章中连续抽取句子,填充到模型输入序列中。也就是说,一个输入序列有可能是跨越多个文章边界的。具体来讲,它会从一篇文章中连续地抽取句子填充输入序列,但是如果到了文章结尾,那么将会从下一个文章中继续抽取句子填充到该序列中,不同文章中的内容还是按照SEP分隔符进行分割。
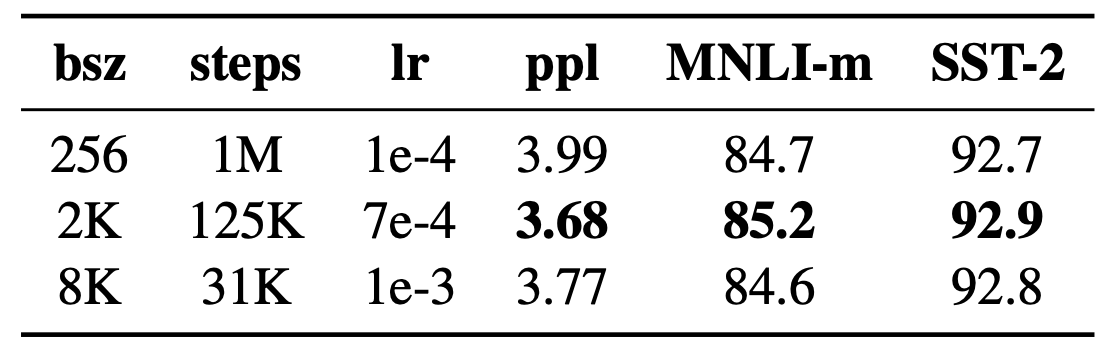
3. Larger Batch Size
RoBERTa通过增加训练过程中Batch Size的大小,来观看模型的在预训练任务和down-stream任务上的表现。发现增加Batch Size有利于降低保留的训练数据的Perplexity,提高down-stream的指标。
4. Byte-Level BPE
Byte-Pair Encodeing(BPE)是一种表示单词,生成词表的方式。BERT中的BPE算法是基于字符的BPE算法,由它构造的"单词"往往位于字符和单词之间,常见的形式就是单词中的片段作为一个独立的"单词",特别是对于那些比较长的单词。比如单词woderful有可能会被拆分成两个子单词"wonder"和"ful"。
不同于BERT,RoBERTa使用了基于Byte的BPE,词表中共计包含50K左右的单词,这种方式的不需要担心未登录词的出现,因为它会从Byte的层面去分解单词。
5. More Data and More Training Steps
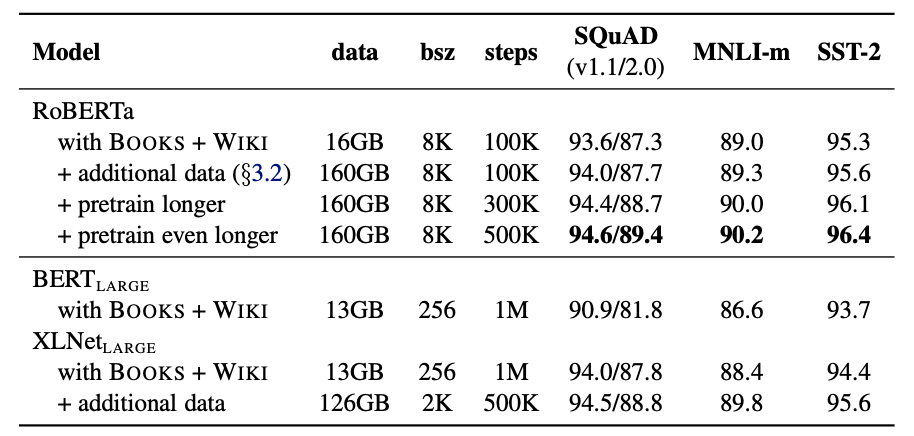
相比BERT, RoBERTa使用了更多的训练数据,详情如图4所示。

图5展示了RoBERTa随着训练数据增加和训练步数增加的实验效果,显然随着两者的增加,模型在down-stream的表现也不断提升。
6. 相关资料
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- RoBERTa Github
如果同学们对本课程感兴趣,想了解更多课程相关信息,或者查阅更多课程资料,请移步我们的官方github: awesome-DeepLearning,也欢迎各位同学点击Star,有大家的支持我们才会走得更远,提供更多优质资源以供学习。同时更多深度学习资料请参阅飞桨深度学习平台。

最后,也欢迎同学们加入我们的官方交流群。
这篇关于【原理】预训练模型之自然语言理解--RoBERTa的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





