本文主要是介绍容器化云原生大数据平台什么样?智领云KDP给你打个样儿,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

我们正徜徉在一个云、容器与Kubernetes交织的世界。虽然有100多种管理容器的工具,但大多数用户还是倾向于将Kubernetes作为首选。Gartner的数据显示,2022年超过75%的全球组织在其生产系统中采用了容器化应用程序。从这个意义上说,Kubernetes不再是单纯的容器编排工具,而是正在成为混合多云环境中的主干,甚至有人称其为“云的操作系统”。
如今,企业的IT基础架构正在快速且大规模地容器化、云原生化,那么诸如大数据、人工智能等新兴应用何时也能踏上容器化、云原生化的快车呢?
有一家备受关注的中国企业,凭借长期以来在云原生大数据领域的持续深耕,叫响“云原生”品牌,旗下推出的Kubernetes Data Platform(以下简称KDP),更让容器化云原生大数据平台从理想照进了现实。
Hadoop日渐式微
容器与大数据融为一体

“在美国的大数据平台圈,企业用户要不就直接采用类似于RedShift或者BigQuery的公有云数据库,要不就使用类似于Snowflake的云原生数据解决方案,基本上很少有人直接使用Hadoop了。”智领云CEO彭锋在谈到大数据平台的发展时,直言Hadoop已日渐式微。

智领云CEO 彭锋
但是国内则不同,很多企业的大数据平台依然构建在Hadoop之上。这对于像智领云这样希望引领大数据平台云原生化的创业企业来说,反而是一个难得的机会。KDP是智领云自主研发的、市场上首个可完全在Kubernetes上进行部署的容器化云原生大数据平台。它深度整合了云原生架构的优势,并将大数据组件及数据应用全部纳入Kubernetes管理体系,通过标准化的系统管理,持续提升系统运行效率,同时降低运维成本,消除应用孤岛和数据孤岛,从而突破了传统Hadoop大数据平台由于架构限制在部署、运维、运行效率方面带来的难点和痛点。
很多国内客户在见到彭锋时的第一反应通常是:“智领云能把我们现有的Hadoop上的工作负载迁移到KDP上吗?”“KDP可以直接在Kubernetes环境中运行所有工作负载,统一资源管理。换句话说,KDP作为中间管理层,可以简单方便地管理Hadoop等各种大数据相关组件。”彭锋十分肯定地表示。在云原生的大潮下,大数据平台或许将面临一次新的“大迁徙”。不过,智领云显然有更高的追求,那就是帮助客户真正地在Kubernetes上运行其所有的大数据组件,并把它们很好地管理起来。
以前,以Oracle为代表的传统的单体架构因为不能满足海量数据分析的需求,所以才出现了所谓的大数据的概念,这也是Hadoop、MapReduce等开始盛行的原因。但是现在有了Kubernetes这种分布式的操作系统,架构上实现了存算分离,计算、存储、数据库等无一不可容器化,海量数据的处理和分析不再是“特例”,所以区分数据与大数据似乎也就没有了实际意义。云原生化实际上降低了大数据应用的门槛。
2011年,时任Twitter大数据平台主任工程师的彭锋回忆道:“那时还没有Kubernetes,甚至也没有Docker,Twitter就干脆自己开发容器以及云平台Mesos,而且能将大数据平台以云原生的方式在Mesos上运行管理。”2016年,彭锋将这种先进理念与技术注入到智领云的大数据产品技术体系中,较早地开始了大数据组件容器化的改造工作。“2017年、2018年,我们还要苦口婆心地向用户解释什么是容器。”彭锋说,“而现在,我们遇到的大多数客户都已经在使用Kubernetes,其关心的重点集中在大数据应用运行在Kubernetes上可能会有什么问题,而不再是‘ 能不能’的质疑。”
对于大数据平台的容器化来说,2021年是转折之年,因为大数据的两个关键组件——Kafka与Spark官宣支持Kubernetes。当年5月,智领云在第一时间对产品进行了优化升级,加入了对Kubernetes的支持。无论是对于大数据平台的Kubernetes化,还是对于智领云的发展来说,这都是一个全新的开端。
众所周知,在Kubernetes还不支持大数据平台时,企业运行大数据应用时要单独搭建集群,主要的业务系统、各种微服务以及Web Service等都需要独立管理。现在,KDP就相当于在用户现有的Kubernetes内部建了一个大数据平台,将业务系统与数据平台打通使用,不再像以前那样需要在Kubernetes之外另建一个独立的大数据平台,更无须独立管理,而是与用户现有的管理系统紧密地融为一体。
总结来看,KDP更符合云原生、容器融合统一管理这一趋势。“下一代IT基础架构一定是云原生的。”彭锋说,“市场上的头部客户已经开始涌现出明确的在Kubernetes上运行大数据的需求。”
都拿KDP与CDP比
其实KDP是学不来的

商业市场从来就少不了竞争。智领云KDP初来乍到,难免会遇到像Cloudera这样的强手,产品PK也在所难免。Cloudera CDP(Cloudera Data Platform)是很多用户耳熟能详的一款企业数据云平台,它是Cloudera和Hortonworks合并后,将原CDH与HDP中的精华组件合并而成的数据平台,能够支持从边缘计算到人工智能的多功能数据分析。
CDP就是将大数据组件的安装、发布、运营、开发、使用都管理起来。智领云的KDP与其最大的区别在于,所有标准化的大数据组件在KDP的支持下,都能无缝地运行在Kubernetes之上。而且,据彭锋介绍,KDP几乎与业内所有主流的Kubernetes发行版都能完美适配,具备良好的兼容性。
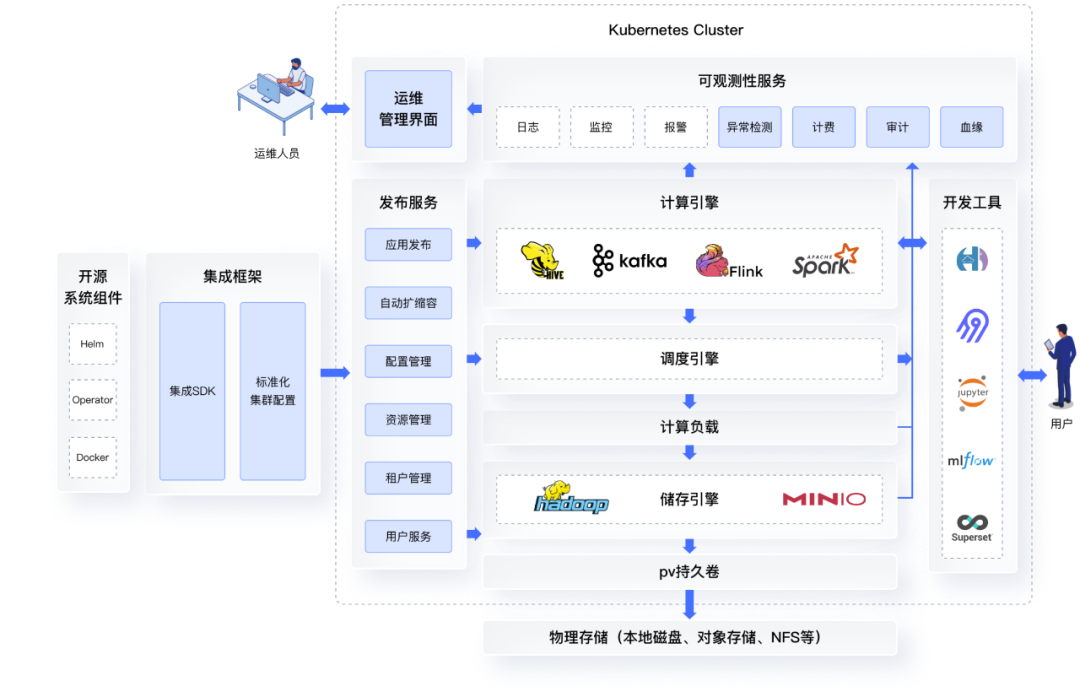
KDP产品架构图
“KDP实际上是一个中间的管理层,它管理的各种大数据组件都是不同公司开发的。”彭锋解释说,“以前极少有厂商涉足管理层面,再加上无论是Hive还是Spark都有自己的发布方式,没有统一的标准,管理起来更是难上加难。直到云原生技术出现之后,加速了发布管理方式的标准化,通过中间管理层进行统一管理才真正成为可能。那么,用户在完成Kubernetes改造后,自然而然地就会想将所有的数据应用运行在Kubernetes上。”
正是因为这种先发优势,许多金融机构、运营商等行业头部客户才主动找上了智领云。虽然这些客户所属行业不同、具体的业务需求千差万别,但相同的是,他们都已经广泛地使用了大数据平台,而且业务系统基本都运行在Kubernetes之上,对于大数据与Kubernetes的融合有迫切的需求。
归纳来说,在Kubernetes上运行大数据平台有以下四个好处:第一,统一管理,复用Kubernetes基础架构,复杂度大大降低;第二,资源混排,高效利用共享资源池,各个组件及整个集群都很容易弹性伸缩;第三,整个系统能够快速支持新应用的集成,快速迭代;第四,系统稳定性得到极大提高,运维效率高。“KDP聚焦于各个大数据组件的安装,以及统一的资源管理。”彭锋打比方说,“类比Windows资源管理器,KDP就像大数据平台的资源管理器。”
智领云先行迈出云原生这一步,KDP率先将大数据组件及数据应用纳入Kubernetes管理体系,让社区或其他大数据应用厂商做各种各样的大数据组件,而智领云只做好一件事——中间层的管理,其下的组件客户可以任意选择,而组件的运行和管理方式是统一的。
“未来,我们可能会将KDP开源。”彭锋透露了心中的一个小目标,“虽然每家企业都需要一个像KDP这样的中间管理层,但又不必每家都自己来做。我们将KDP技术架构开源出来,将给企业客户带来更大的效益。在KDP之上,我们还有DataOps组件,在云原生平台上能够为客户、为我们自己带来更大的增值空间。”
基础平台免费
为用户提供更深层次的增值服务

如果非要找对标的企业,智领云的产品形态类似Cloudera,而商业模式则与Databricks更相像。Databricks致力于提供基于Spark的云服务,但Spark也是开源的,那Databricks靠什么赚钱呢?“我们也在研究Databricks的商业模式。”彭锋坦言,“未来,我们可以将基于Kubernetes的大数据平台(基础版)免费提供给企业用户使用。在此基础之上,如何为客户提供更好、更深层次的增值服务则是需要我们认真思考的问题,比如提供更好的安全性、更多企业级的特性和功能,以及解决方案层面的价值等。”
云原生、数字化无疑是发展的大方向,而起到支撑作用的算力、算法、数据以及基础架构则是刚需。“企业走云原生的道路,最终都会需要一个数据管理平台。这就是今天KDP要做的事。通过KDP,企业可以先把数据迁到Kubernetes平台上;我们通过提供企业级的安全性、运营管理和开发工具等支持,让企业用户能够更快地将云原生大数据平台用起来。当用户的使用规模达到一定程度时,就会购买更多开发管理的服务,需要更多企业级的安全、性能和运维工具。这就是我们的机会。”彭锋如是说。
Kubernetes让业务应用的发布和管理趋于标准化。而智领云的终极目标则是让数据应用的发布和使用也变得标准化。从容器化云原生大数据平台开始做起,智领云正一步一个脚印前行。
这篇关于容器化云原生大数据平台什么样?智领云KDP给你打个样儿的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






