本文主要是介绍从安装软件开始教你爬取微博上万条评论数据!这都还学不会吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 前言
最近有同学问我有没有试过用scrapy爬东西,说想爬一条微博下面的评论,恰好几年前用scrapy爬过电影票房做作业,于是心血来潮,再次使用scrapy进行了这次微博评论的爬取,弥补了一下当年想爬微博但是没有进行的遗憾,(看到是动态加载,难度太高,知难而退)
这次选择scrapy的理由是当时被问就是有没有用过scrapy,其次是因为几年前用过,觉得编码量小、也不难,不太需要懂底层实现原理,十分适合初学python或者爬虫的同学来使用
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
1. 前期准备
1.1 安装python
安装python就没什么技术含量了,网上有很多教程,我在装这些东西的时候也是跟着教程做的避免出错,所以没什么好班门弄斧的了,要特别注意的是要配置环境变量,如果没有正确配置环境变量,有些命令可能要切换到相应文件夹下面才能使用
在系统变量-环境变量-Path中加入你的Python安装路径的Scripts路径
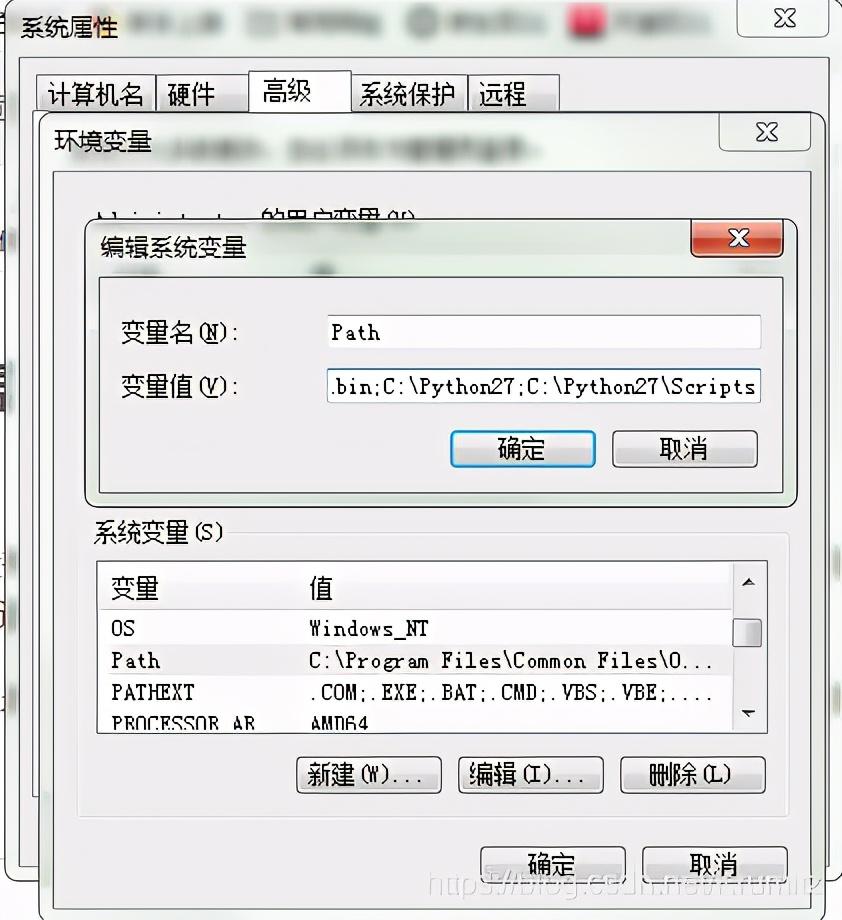
我的是C:\Python27\和C:\Python27\Scripts
1.2 安装scrapy
这一步在安装的时候没有详细记录,引用文章https://www.cnblogs.com/txw1958/archive/2012/07/12/scrapy_installation_introduce.html
有报错的话跟着报错解决就行了
1.3 创建scrapy项目
在安装好scrapy之后,在控制台输入
scrapy startproject 项目名
我是在pycharm下面的控制台输入
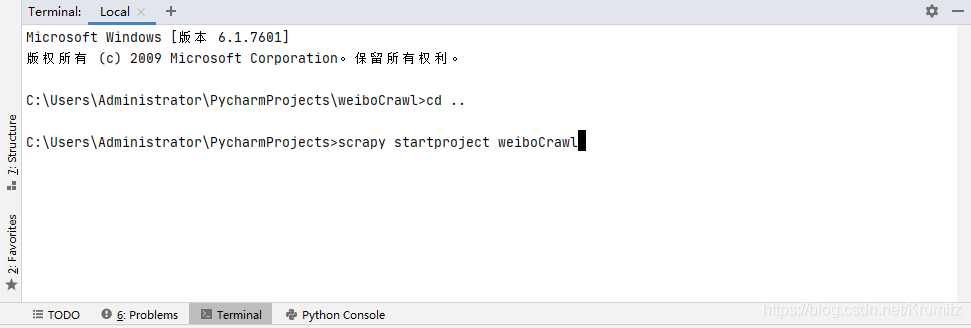
创建了一个名为weiboCrawl的Project,然后在pycharm中打开就行了
2. 对象选择
本来选择的对象是weibo.cn

因为这个站点的爬虫肯定是最好做的,不涉及复杂的加载,只有简单的翻页,递归的请求就好了,但是不知为何,在第50页之后的评论显示不出来

然后在思考的过程中点到了手机微博触屏版m.weibo.cn的链接,他是这个样子的

按下 F12 debug ,在没有往下拖动的时候

这里加载的东西有点多,但是无所谓,先拖到最下面,然后将页面往下拖动加载评论,观察新加载的请求
往下拖动加载评论
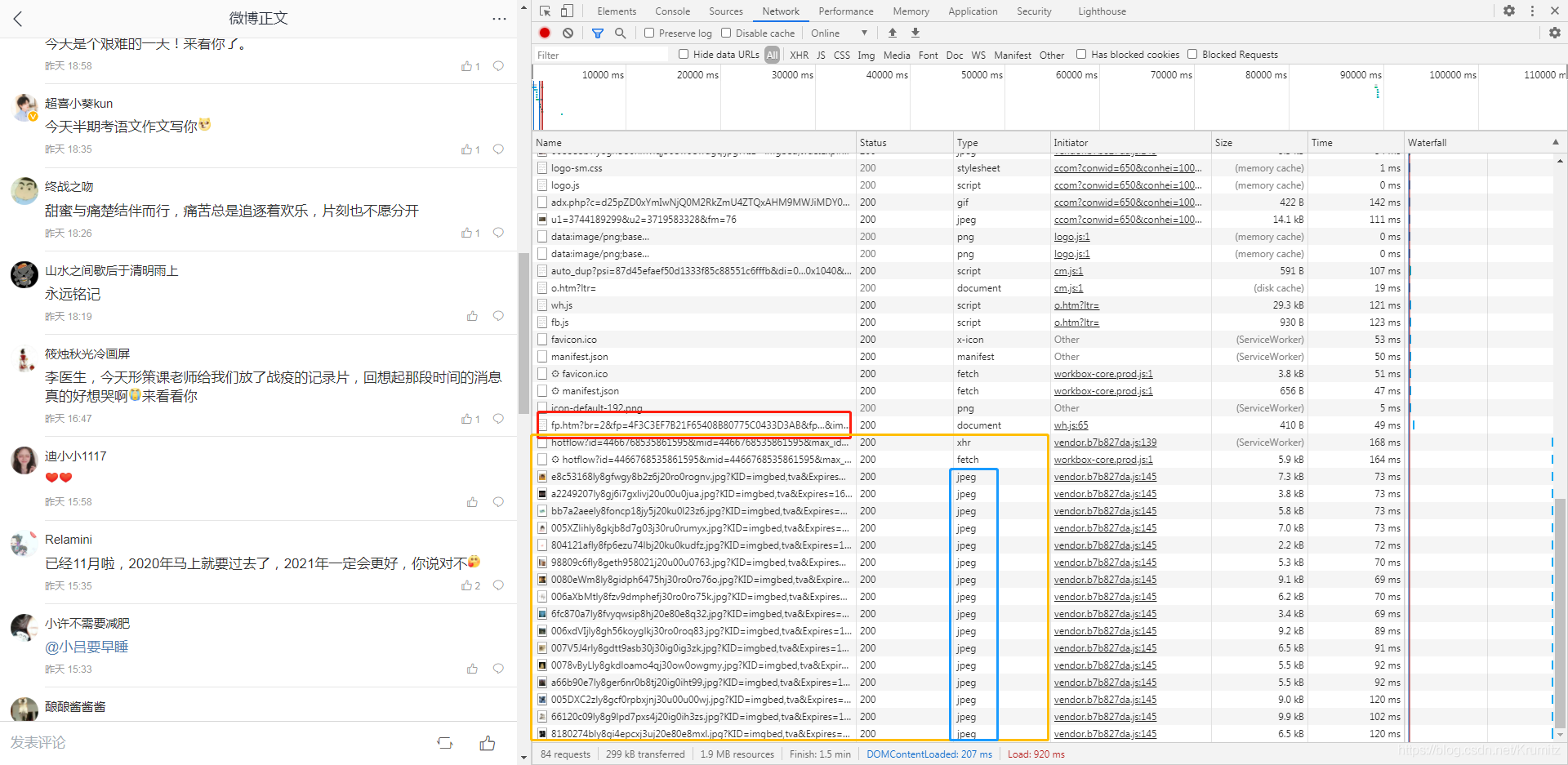
可以看到,红框是我们上一个截图的最后一个请求,黄色框就是我们向下拖动加载评论的时候新发出的请求,那么新加载的评论肯定也是返回在这些请求当中的
评论我想百分之99都不会返回在jpeg里面的吧,那肯定就是在最上面那两个请求获得了新加载的评论了,如果实在不行、返回的格式都是你不认识的格式,那一个一个点开来看看也是可以的
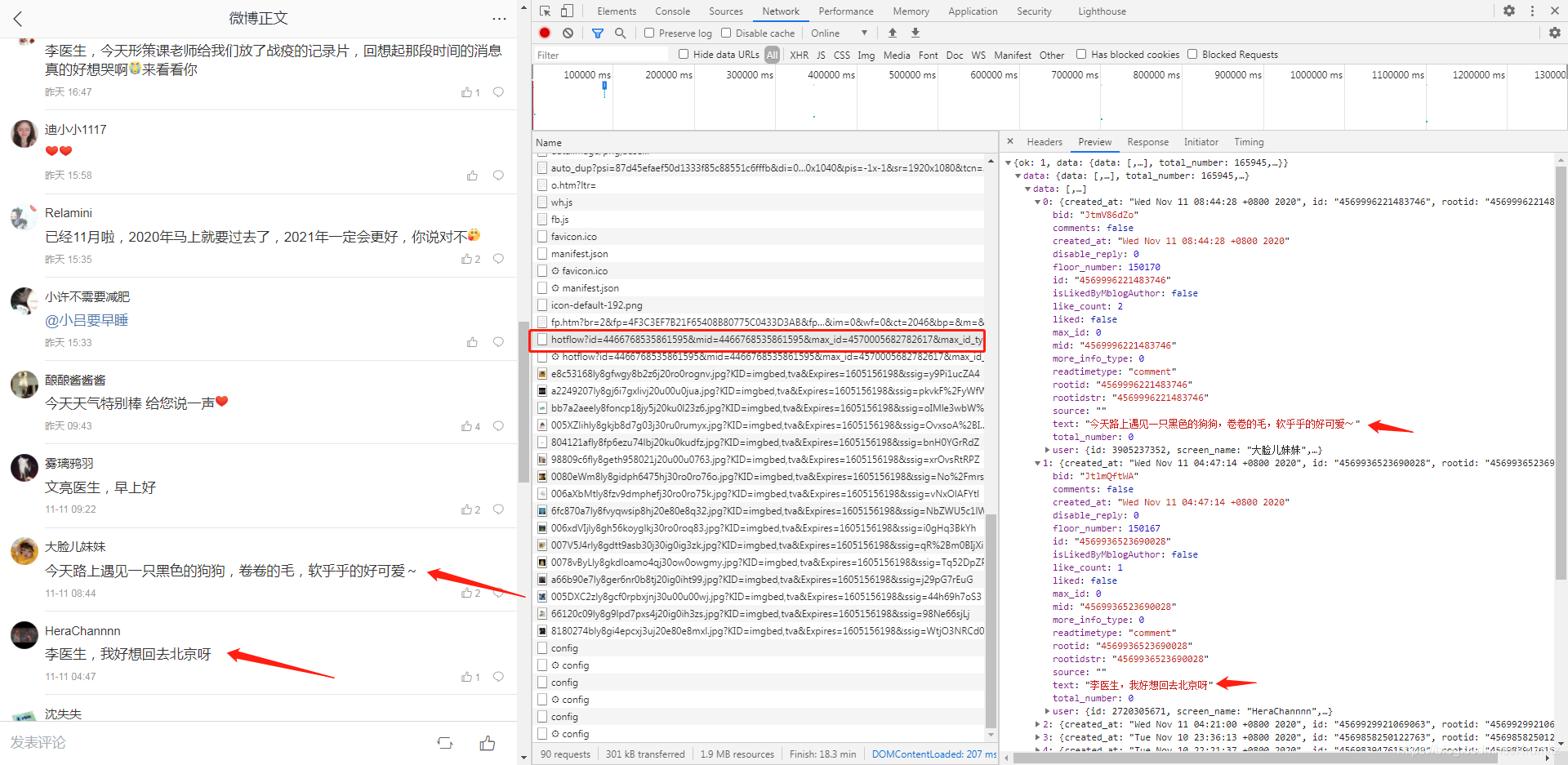
可以看到,新加载的评论确实在这个请求中返回
再往下拉多几次之后发现都是一样的,那么我们就可以通过这个移动版微博的这个请求来爬取我们想要的评论,接下来要做的只是找到他们之中的规律请求就好了
3. 对象分析
3.1 请求分析
第一个请求https://m.weibo.cn/comments/hotflow?id=4466768535861595&mid=4466768535861595&max_id_type=0
第二个请求https://m.weibo.cn/comments/hotflow?id=4466768535861595&mid=4466768535861595&max_id=4570005682782617&max_id_type=1
第三个请求https://m.weibo.cn/comments/hotflow?id=4466768535861595&mid=4466768535861595&max_id=4569624815600863&max_id_type=1
后续请求类似
请求中,有id、mid、max_id、max_id_type四个参数,其中id和mid通过观察发现在每个请求中都是一样的,因此无须分析,重点看另外两个
其中,max_id_type只有第一次为0,后面都为1,不难知道,max_id_type为0的时候表示不传max_id,为1时表示传max_id
也就是说我们第一次请求设置为0,后面这个参数都设置为1就好了
观察第一个请求的返回包
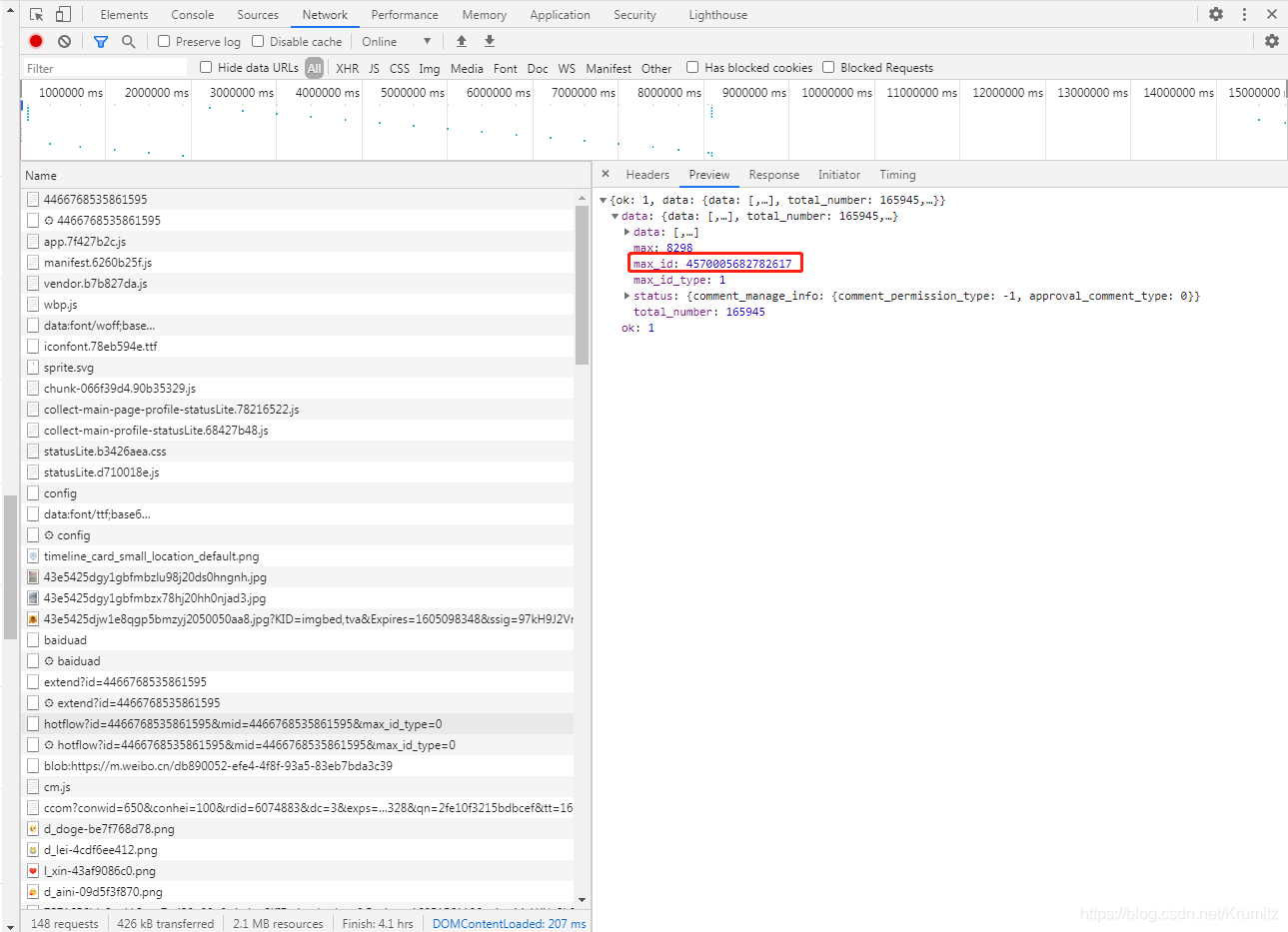
返回的max_id=4570005682782617
再看第二个请求中传递的参数max_id恰好就是第一个返回包中返回的max_id的值
后面的请求也是如此,下一个请求传递的max_id的值是上一个返回包中的max_id的值
得出结论:
1.发起请求,存储返回的max_id的值,
2.在JavaScript的控制下,浏览器拖动到一定位置,触发下一次查询请求
3.传递上次接收到的max_id,再在这个请求中获得下一个max_id值
4.到2
以此类推
当然,这里没有求证是否正确,因为要看他的JavaScript,没有必要,大概正确即可,功能完成就行
因此,我们的爬虫思路可以跟他的编码思路一样
1.发起第一次请求
2.提取评论内容
3.提取max_id
4.发起下一个请求
5.到2
以此类推
3.2 内容分析
刚刚的返回内容都是通过preview查看的,实际的response中以json串返回了一大堆数据,该串太长,就不贴上来了
通过preview可以知道
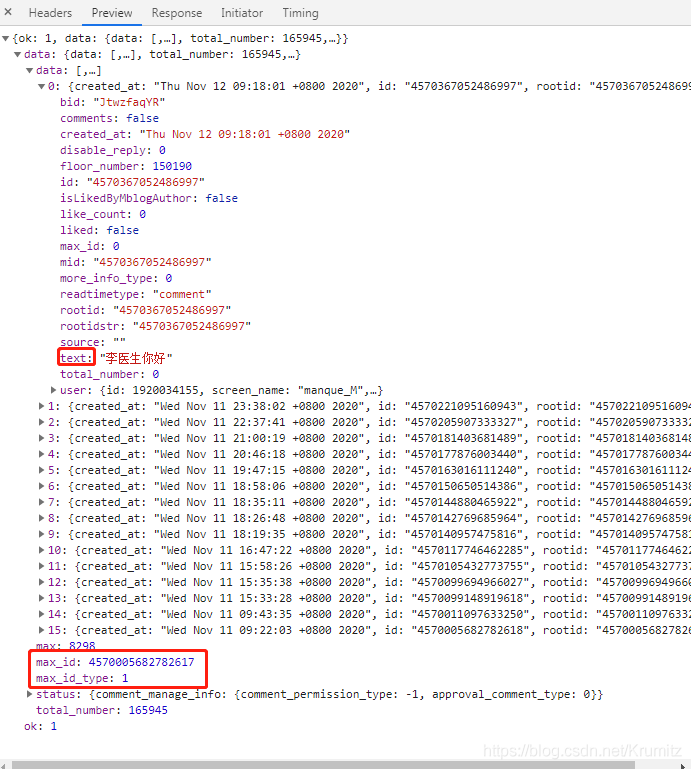
评论的内容对应“text”中的值
max_id和max_id_type对应max_id和max_id_type的值
值得一提的是,实际上评论的内容是以类似
"text":"\u674e\u533b\u751f\u4f60\u597d"
这样的unicode编码返回的,所以在提取出来存到本地使用时,要转码再写入,要不会不显示中文,在等等的编码环节会提到
因为返回的是json串,应该无法使用css选择器提取内容,因此目前只能想到使用正则表达式提取
而整个返回包中text只有评论时出现,所以我们可以简单的写一个匹配
"text":"(.*?)"
的内容就好了
其他需要提取的内容也是如此
4. 编码
4.1 spider.py 程序入口
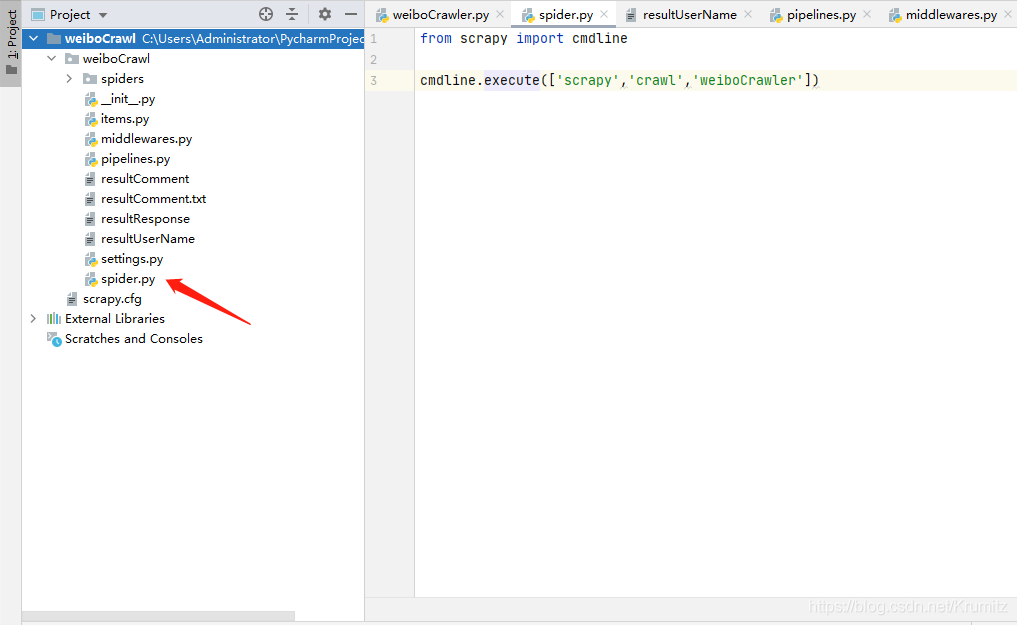
首先我新建了一个spider.py
from scrapy import cmdline cmdline.execute(['scrapy','crawl','weiboCrawler'])
这样我就可以直接使用pycharm的运行启动了,不需要在控制台输命令
如果有需要的话请根据上图的结构新建文件
第三个参数需要对应你的爬虫的名字
4.2 settings.py
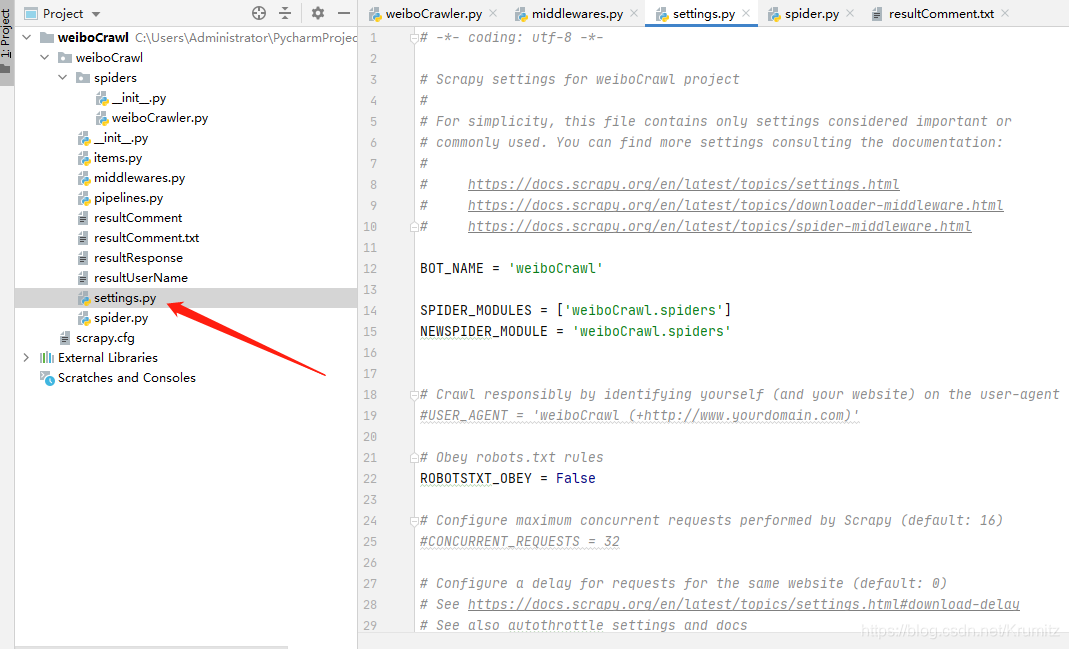
修改
ROBOTSTXT_OBEY = False
修改
COOKIES_ENABLED = True
去注释,将中间件启用
# Enable or disable downloader middlewares# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.htmlDOWNLOADER_MIDDLEWARES = { 'weiboCrawl.middlewares.WeibocrawlDownloaderMiddleware': 543,}
修改Headers
DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'}
4.3 middlewares.py
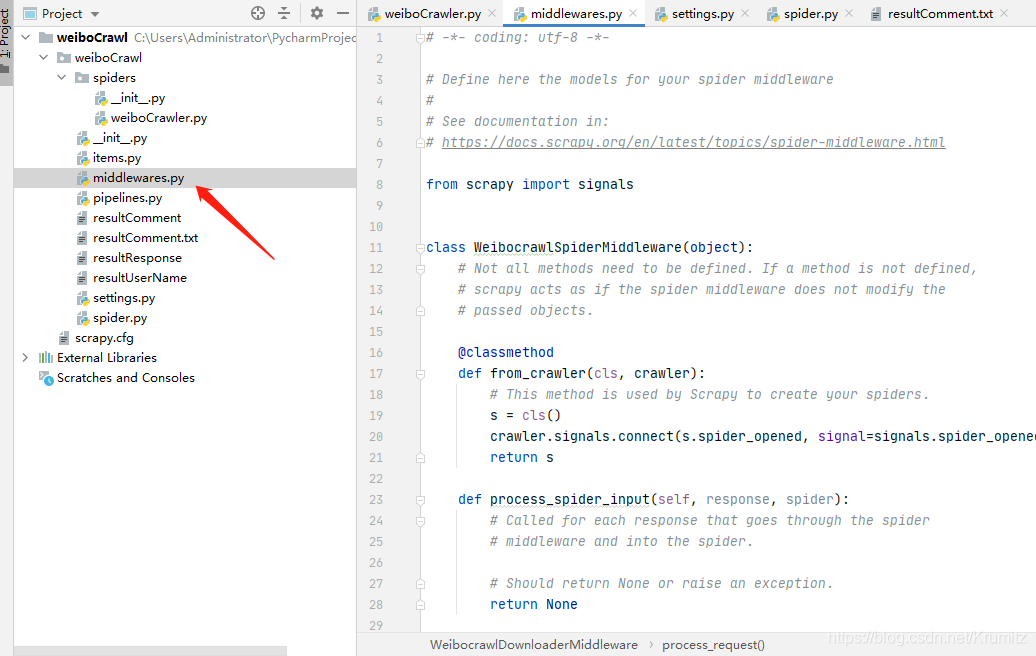
在process_request函数中增加你的cookies的值,如果没有cookie,微博可能会视为游客用户,无法正确加载评论
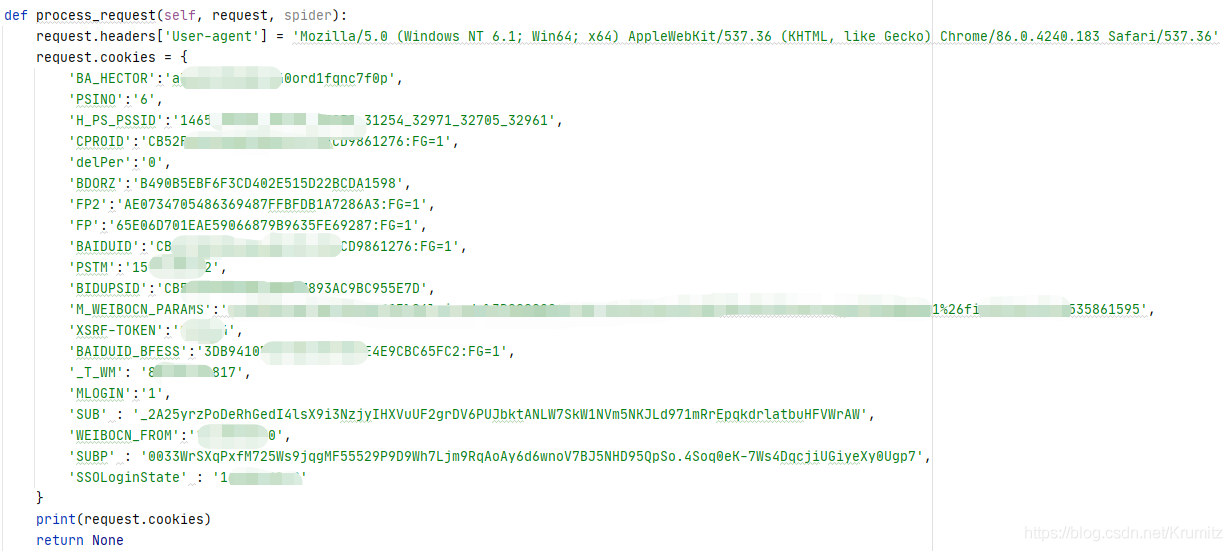
这里有些cookie应该是不需要的,但是为了保险起见,我还是全部加上了
你可以通过
浏览器F12-Application-Storage-Cookies-对应的网址
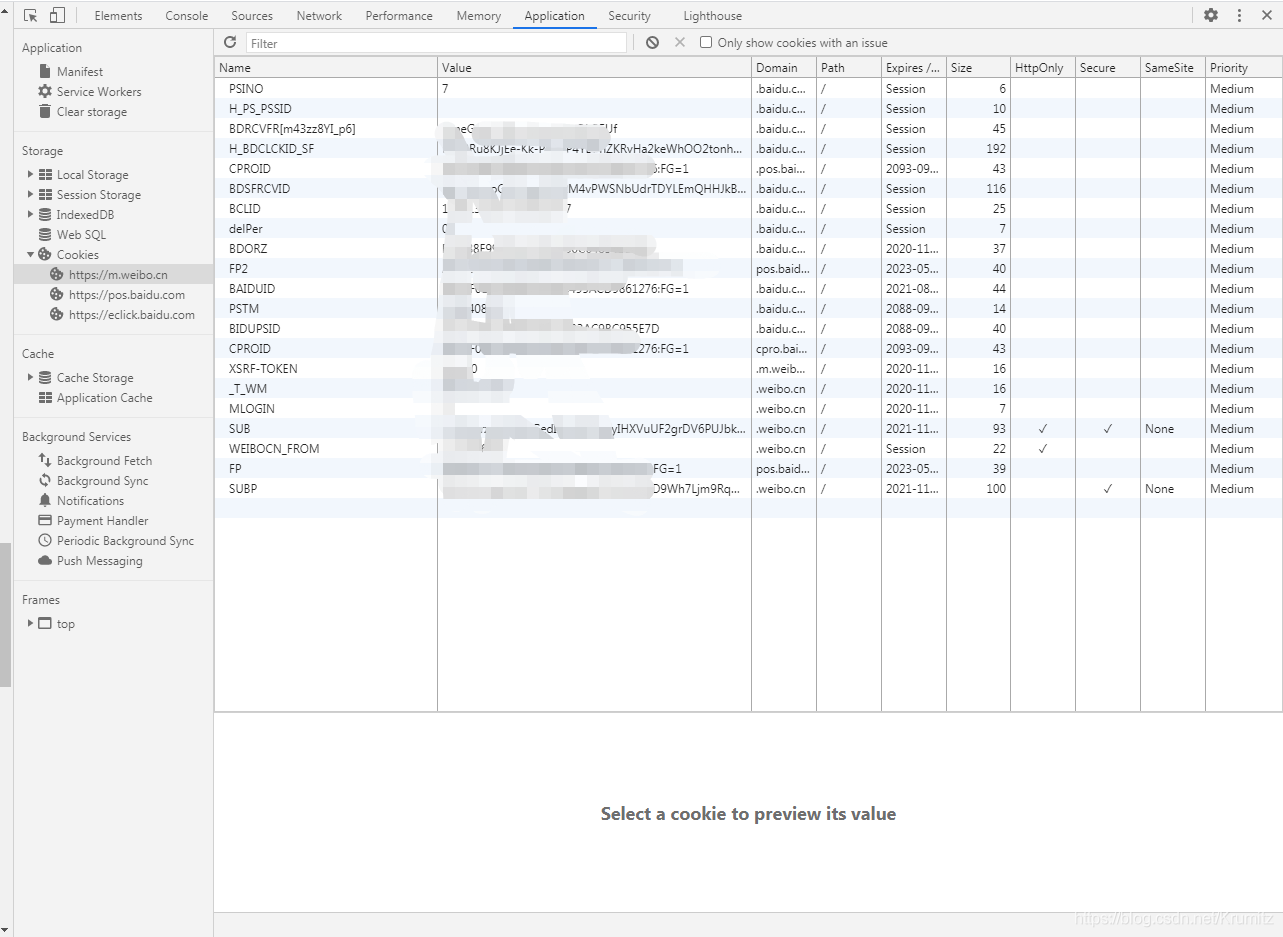
查看你的cookies并加入
最后,该函数要返回None,返回其他可能会出错,如果有其他的需求的话再考虑返回其他值,这次不需要
4.4 weiboCrawler.py
在这个文件中,我们只要完成分析得到的需求即可,即
请求-提取内容-请求
剩下的交给框架去做就好了
# -*- coding: utf-8 -*-import scrapyimport reimport sysimport timereload(sys)sys.setdefaultencoding('utf-8') class WeibocrawlerSpider(scrapy.Spider): name = 'weiboCrawler' allowed_domains = ['m.weibo.cn'] start_urls = ['https://m.weibo.cn/comments/hotflow?id=4466768535861595&mid=4466768535861595&max_id_type=0'] def parse(self, response): #正则表达式匹配评论 textList = re.findall(r"\"text\":\"(.*?)\",", response.body) #正则表达式匹配max_id,将用来查询下一页的评论 maxId = re.findall(r"\"max_id\":(.*?),", response.body) #正则表达式匹配max_id_type,初始为0,后面都是1 maxIdType = re.findall(r"\"max_id_type\":(.*?)}", response.body) #获取最后一个max_id max_id = maxId[len(maxId) - 1] #获取max_id_type max_id_type = maxIdType[len(maxIdType) - 1] #将评论写入文本 with open("resultComment.txt",'a') as f: for text in textList: text += '\n' #显示中文 f.write(text.encode().decode('unicode_escape')) #向下继续查询 if int(max_id_type) == 1 : #这里直接拼接就好了,不太需要搞什么高级的操作 new_url = 'https://m.weibo.cn/comments/hotflow?id=4466768535861595&mid=4466768535861595&max_id='+str(max_id)+'&max_id_type=1' print(new_url) #需要暂停一下,如果一直请求,微博可能会返回请求过于频繁403Forbidden time.sleep(3) #发起请求 yield scrapy.Request(url=new_url, callback=self.parse)
5. 结果

评论是成功提取出来了,对应网页上的内容也可以对应起来
但是一些@别人的啊,或者是一些微博表情变成了链接,看起来很乱
想去掉也是可以的,但是我觉得没有必要,先就这样了
6. 后记总结
因为只需要写一个例子出来,所以写的很简单,复用性不高
没有深入的了解Scrapy框架的原理
完成的功能也很简单,只提取了评论,如果需要提取用户名或者其他内容,按照分析中的思路来做即可
另外,由于数量过大,我没有爬取该微博全部的评论,只爬取了一部分,不确定设置了time.sleep后是否还会被服务器屏蔽
如果有被屏蔽的情况发生,可以考虑引入Cookie池,这一类的文章在我研究如何引入cookie时看到过,各位读者可以自己搜索一下
这篇关于从安装软件开始教你爬取微博上万条评论数据!这都还学不会吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





