本文主要是介绍BET数据处理中8大案例分析,教你看懂吸脱附曲线【内含干货】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Q:为什么得到的BET值为负?
A:正常情况下样品对吸附质有吸附的话比表面积值应该为正,出现负值的可能有三种原因:
1. 样品自身的原因,可以看等温吸脱附曲线,如果没有吸附的话吸附值应该在0附近,再加上仪器误差的现象,也可能跑到负值出现吸附点,所以该类样品的吸附几乎可以忽略。
2. 测试所加样品量过少,造成总的吸附值很低,则容易产生这个现象。
3. 脱气温度和时间不合理,脱气温度过高,造成孔结构的变化或坍塌,脱附温度太低或者脱气时间短,造成脱气不完全,也会产生这个问题。
Q:为什么等温吸脱附曲线是不闭合的?
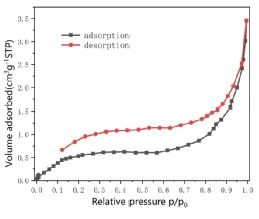
A:等温吸脱附曲线不闭合,这种情况比较常见,产生这种现象的原因也比较多,可能原因如下:
1. 材料表面存在特殊的基团和化学性能,导致吸附的气体分子无法完全脱离,即材料对吸附质有较强作用,导致吸脱附会存在一定的不闭合程度。
2. 材料自身的比表面较小,一般吸脱附闭合程度会较差。
3. 称样量问题,称样量太少,容易造成测量不准,也会出现此类情况。
4. 样品前处理问题,温度太高,测试的孔结构坍塌,气体脱附不出来会造成曲线不闭合。
5. 如果研究碳材料的话需要注意,碳材料的孔大多为柔性孔或者墨水瓶孔,气体吸附之后孔口直径收缩,导致吸附上的气体不易脱附,很容易导致吸脱附曲线不闭合。
Q:为什么等温吸脱附曲线是交叉的?
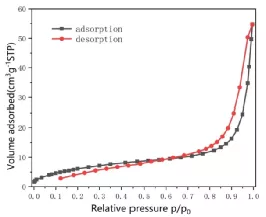
A:吸附曲线和脱附曲线发生交叉的主要原因是:
1. 样品吸附值本身就比较小,容易出现波动。
2. 脱气条件不合适,脱气温度低或者时间短,水分没有完全除去,在脱附过程中脱去了。
3. 样品量太少,容易造成测量不准,也会出现此类情况。
4. 样品脱气前处理条件不合适,造成脱气不完全,在脱附的过程中有东西脱附出来,造成等温吸附曲线和等温脱附曲线产生交叉的现象。
Q:BJH脱附孔径分布存在“假峰”
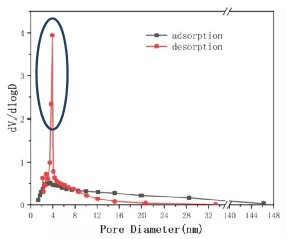
A:在气体脱附过程中大多数情况下都反映了一个滞后的过程。
所以在用BJH方法分析样品孔径时,脱附段很容易出现假峰,一般是在3.8nm处出现,出现假峰的原因与孔的类型有关系,内部孔道的连通性,孔型的多样性以及孔径的分散性等等原因都会导致在脱附过程中出现假峰。
Q:谱图中出现了S型微孔等温曲线
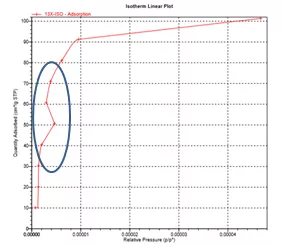
A:S型回线通常发生在低压区微孔材料测试过程中出现。出现S型回线主要有两点原因,一种是低压区吸附不完全,在没有达到吸附平衡时候就进入到了第二个吸附点,所以会产生S型回线。
如果想要改变这种情况,应该适当增加低压区的吸附时间,保证每一个压力点都可以达到吸附平衡。
第二个原因是氦污染,在用氦气测量死体积时,是基于氦气不吸附的假设,但事实上物理吸附是非特异性吸附,对任何气体都存在吸附,微孔材料会吸附较多的氦气,其影响无法忽略不计。因此在继续分析之前,应当至少将样品放在室温下使氦气溢出后再进行测量。
Q:是否可以增加或者减少一些压力点?
A:每台仪器上介孔或者全孔测试都有固定的测试文件,压力点都是设置好的,直接测试就可以。
如果有特殊需求,也可以增加或减少一些压力点的话,测试时间也会相应改变,如果低压区加密点,测试时间会变得更久,可能较正常时间要多一倍的测试时间,所以时间的成本和测试的成本会相应增加。
Q:样品的比表面积,是否和样品测试量有关?样品用量过少会造成哪些影响?
A:样品的比表面积只与样品本身有关,理论上测试量多少并不会改变比表面积的大小;但是如果样品量过少,吸附量低,会产生误差,得不到准确的比表面积值。
Q:从数据上哪个指标可以看出数据的好坏?
A:所有的信息,比表面积,孔容,平均孔径,孔径分布都是基于吸脱附曲线来计算得来的,因此判断结果好坏最直接的就是看吸脱附曲线。
吸附量是否随着分压增加而增加,吸脱附曲线是否闭合;但是吸脱附曲线也要结合样品性质来判断,比如样品加入量,脱气温度,样品孔结构等。
更多科研干货教程,可以点击下面链接获取哦~
BET测试
这篇关于BET数据处理中8大案例分析,教你看懂吸脱附曲线【内含干货】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






