本文主要是介绍Gitlab Merge Request “commits” “changes”分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近处理开发人员Merge request 问题时候碰到一个问题:开发人员实际做了一个提交,编辑了三个文件,但是在gitlab merge request中显示的是12个文件差异。今天分析了一下原因,以此记录:
1 分析gitlab mq(merge request)的commits
例如有两个feature,develop和张三的创建的fea1,fea1提交 mq到develop时候gitlab是如何计算commits?
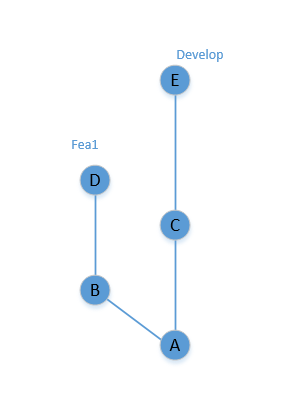
如果把fea1提交到develop那么只需要计算出来 在fea1上不在develop分支上的commit就可以了,用git 命令是 git log develop..fea1 展示的就是gitlab显示commits 即 B D
2 Gitlab mq的changes
先看一个简单情况:
例子还是上面的例子如何计算变更文件的呢?
合并两个分支的时候Git会首先找到两个分支的公共父提交从图上可以看出他们的父提交为A(如果拓扑图复杂可通过命令寻找 git merge-base fea1 develop)那么fea1修改的代码文件即fea1 在提交A基础上修改的文件内容直接展示即可,gitlab展示的changes为 git diff A fea1
复杂情况:
基于以上拓扑图张三提交mq 到develop分支(F) 测试人员测试认为不通过
张三在原来fea1基础上修改bug提交(G)
与此同时开发李四从提交C拉出fea2分支开发提交(H),提交后正常走mq到develop(I)
张三需要fea2的功能于是就把fea2 merge到了fea1 形成了新的提交J
在这种情况下如果 张三发起mq会怎样呢?
分析如下:
首先git会找fea1和develop的公共父提交,这种情况下公共父提交有两个H和D(A也是公共父提交但不是最优公共父提交,因为A是D的父提交,这个git官网所述可以参考git merge-base命令) 父提交可以通过 git merge-base fea1 develop -a 显示
commits: 通过 git log develop..fea1 可以查询到G J gitlab显示正确
changes该如何选择呢?如果公共父提交选择D 应该显示 git diff D J,这样的话可可以理解的 本次mq显示张三最近的修改。如果选择H 就会显示 git diff H J,会把fea1 的历史修改全部显示即 B D G所有修改,这样就有歧义了, 1、Merge Request commits展示的死活G J二changes展示的是B D G的修改,2、张三这次本来至修改了G 他认为changes只展示G是合理的。
做了个实验:结果是gitlab确实选择的是H,个人猜测gitlab 是通过 git merge-base fea1 develop直接得到的(加 -a参数会显示全部的)

综上所述个人认为gitlab的Merge Request还是有些歧义的 本人用的gitlab版本是8.17
看到此博客如果有自己的观点请留言
这篇关于Gitlab Merge Request “commits” “changes”分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







