本文主要是介绍SPASS-数据收集及预处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
统计数据的收集
问卷设计
问卷构成
(1)标题 (2)导语(前言) (3)正文 (4)结束语
问卷的问题类型
(1)封闭型问题 (2)开放型问题
问卷中量表的主要类型
(1)连续评分量表 (2)分项评分量表(Likert量表)
问卷设计的注意事项
(1)目的明确
(2)先易后难,先简后繁
(3)提出的问题要具体,避免提一般性问题
(4)单选问题的备选答案应完整划分答案空间
(5)多选题的备选答案必须分布在两个以上的维度上,并且至少有一部分不是互相排斥的
(6)问题的陈述及备选答案不能有多重含义
(7)问题设计的用语要含义明确,不能让应答者产生不同的理解
(8)在问题的陈述中,要对所询问行为的时间、方式、目的做必要的限定
(9)对于得不到诚实回答而又必须了解的数据,可以通过变换问题的提法来获得相应的数据,或者通过了解相对数据来判断总体的情况
(10)问卷不能太长,以20~30分钟为宜;商场拦截类的问卷,以3~5分钟为宜
问卷分析
信度分析 效度分析
SPASS数据文件的建立
统计数据的度量尺度
名义尺度
即定类尺度,它仅仅是一种标志,用于区分变量的不同值,类别数据之间没有次序关系。例如,人口的性别、商品的名称、身份证、商店类型等。
定序尺度
是对事物之间等级或顺序差别的一种测度。例如,考试成绩(优、良、中、差)、人的身高等级(高、中、矮)、学历等级(博士、硕士、学士)等。
间隔尺度
定距尺度
是对事物类别或次序之间间距的测度。例如,100分制考试的成绩、重量、温度等。
定比尺度
是指能够测度值之间比值的一种计量尺度。例如,员工的月收入、企业产值等
不同的度量尺度的统计数据在SPSS的数据文件中,对应不同的变量数据类型。
名义尺度----数值型、字符型 定序尺度----数值型、字符型 间隔尺度----数值型
数据的结构定义
命名规则:
高版本的SPSS的变量名长度可多达64位,但是由于老版本的SPSS变量名长度应在8位之内,为了避免与老版本及其他软件出现兼容问题,变量名一般仍控制在8位之内且尽量避免中文,必要的中文说明可以放在Label栏中加以说明。
首字符应以英文字母开头,后面可以跟除了!、?、*之外的字母或数字。下划线、圆点不能为变量名的最后一个字符。
变量名必须唯一且不区分大小写字母。允许汉字作为变量名,汉字总数一般不超过4个。 变量名不能与SPSS的保留字相同。SPSS的保留字包括:all、by、eq、ge、gt、leIt、ne、not、or、to、with。系统不区分变量名的大小写。
变量宽度
设置变量宽度。一般无需调整,直接采取默认值。它的大小可通过Width栏后边的微调按钮调整。
小数位数
若变量类型为数值型,则可设置变量的小数位数,其他类型的变量则不能设置。小数位数默认为两位。
变量名标签
考虑到与老版本的兼容问题,变量名最好限制为8位以内,并且尽量避免中文,这就有可能不能完全描述清楚变量的信息,此时就可在标签中对变量名做进一步的说明。 利用Label栏,不仅可以对变量详细说明,而且还可以采用中文,大大方便了用户对变量的理解。
变量值标签
变量值标签是对变量的可能取值附加的进一步说明,标签内容最多可以有120个字符,通常仅对类型或分类变量的取值指定值标签。
| 变量值 | 变量值标签 |
| 1 | 通信学院 |
| 2 | 计算机学院 |
| 3 | 管理学院 |
| 4 | 光电学院 |
| 5 | 外语学院 |

缺失值
SPSS统计软件的另一特点就是可以通过制定缺失值的方式来定义缺失数据,这样就可以更好地利用其他的有效数据。
列宽
定义变量在数据窗口中显示的宽度。
对齐
定义变量值显示的对齐方式,默认为左对齐。
度量标准
根据统计数据的类型定义度量尺度,度量尺度在数据分析中的作用不是很明显,但是如果用户要进行交互式绘图就必须定义好度量尺度。
缺失值
SPSS统计软件的另一特点就是可以通过制定缺失值的方式来定义缺失数据,这样就可以更好地利用其他的有效数据。
角色
输入:变量将用作输入(例如预测变量、自变量)。
目标:变量将用作输出或目标(例如因变量)。
两者:变量将同时用作输入和输出。 无:变量没有角色分配。
分区:变量用于将数据划分为单独的训练、检验和验证样本。
拆分:设定此角色是为与SPSS Modeler 相互兼容,具有此角色的变量不会在SPSS Statistics 中用作拆分文件变量。
数据录入
录入数据的一般方法
逐行录入 从Word或Excel中直接复制粘贴到数据文件中 连续粘贴相同值
录入带有变量值标签的数据
输入定义了变量值标签的数据时,可以直接输入变量值,也可以通过下拉列框的形式输入

从其他数据文件导入数据建立数据文件
直接打开
选择菜单“文件→打开→数据”,弹出“打开文件”对话框左键单击“文件类型”,即可看到SPSS所能打开的数据文件类型,如下表所示

其中用的最多的是直接打开Excel的数据文件。
在打开Excel格式的文件时,SPSS默认将Excel工作表中的全部数据读到SPSS数据编辑窗口中,但也可指定仅读取工作表某个区域内的数据。
如果Excel工作表文件第一行或指定读取区域内的第一行上存储了变量名信息,则应选择打开对话框上的复选框“Read variable names form the first row of data”,即以工作表第一行或指定读取区域内的第一行上的文字信息作为SPSS的变量名;如果不选此项,SPSS的变量名将自动取名为V1、V2等。
数据库查询方式
如果数据为数据库格式的文件,可以同用数据库查询的方式导入数据到SPSS中。其操作步骤如下:
第1步 选择菜单“文件→打开数据库→新建查询”,弹出数据库向导窗口。这里显示了所有可以打开的数据源类型。
第2步 用户根据打开文件的向导选择要打开的文件类型并逐步打开文件。
从文本文件导入
文本格式的数据文件是一种最通用格式的数据文件,SPSS提供了专门读取文本文件的功能。
选择菜单“文件→打开文本数据…”,弹出“打开文件”对话框,选择要导入的文本文件名后会出现文本数据的向导,该向导是一个分为6步的打开向导,根据文本文件的格式和导入数据的需求进行每一步的设置即可。
SPASS数据文件的编辑
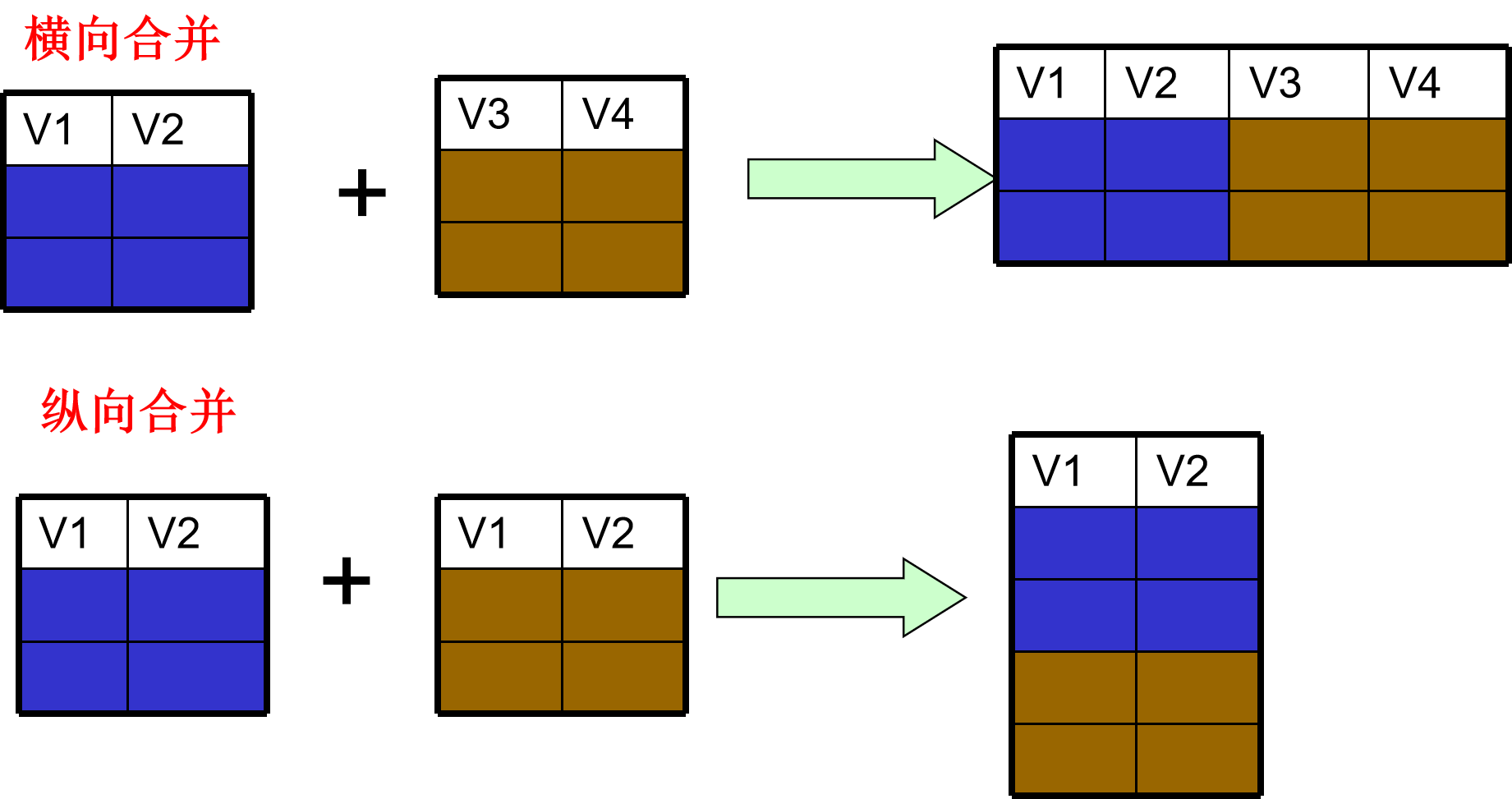
SPSS提供两种形式的合并:一是横向合并,从外部文件中增加变量到当前数据文件中;二是纵向合并,指从外部数据文件中增加观测量到当前数据文件中。
这篇关于SPASS-数据收集及预处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





