本文主要是介绍为什么python如此火爆_用Python来分析一波周董新曲《说好不哭》为何如此火爆!...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

9 月 16 日晚间,周董在朋友圈发布了最新单曲《说好不哭》
发布后,真的让一波人哭了
一群想抢鲜听的小伙伴直接泪奔
因为 QQ 音乐直接被搞崩了
没想到干翻 QQ 音乐的不是网易云音乐
也不是虾米音乐
而是周董!
周董成成功地凭一己之力干翻了 QQ 音乐
那么听过周董新歌后的小伙伴都是怎么评价的呢?
这里,我们获取了 QQ 音乐的近 20W 条评论数据进行分析
看看其中有哪些有趣的东西
一、数据获取
1、请求分析
在 QQ 网页版直接搜索『说好不哭』
很容易就能找到单曲页面
说好不哭
拉到页面最下方
可以看到评论的分页查看按钮

分页查看
按下 F12 点击第二页
在请求流中就可以看到对应的请求
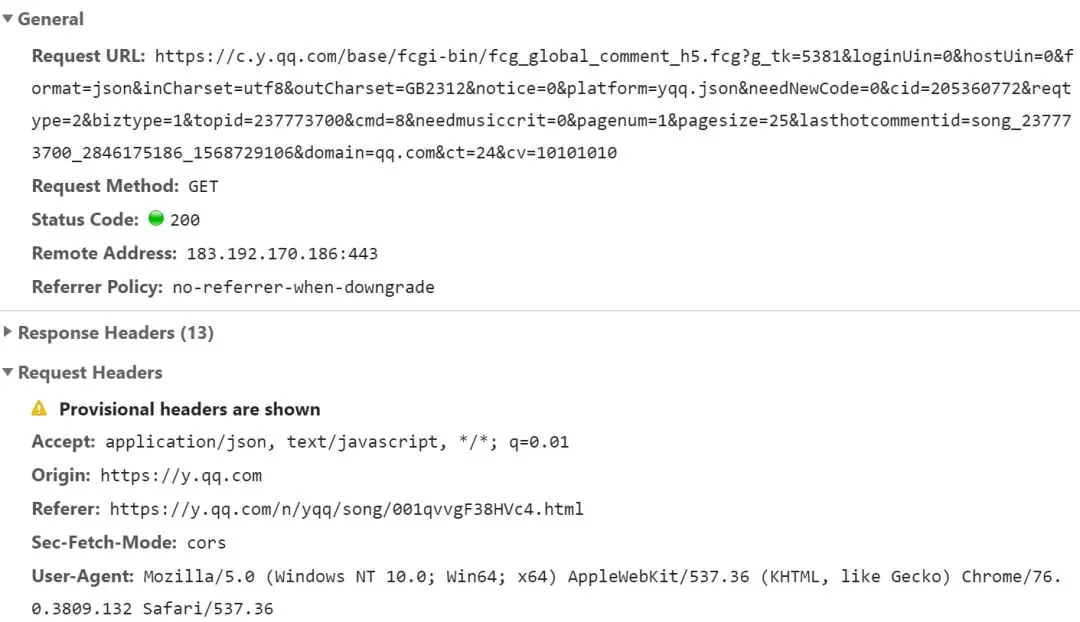
评论请求
其中可以看到两个重要参数:pagenum 和 pagesize
将请求 copy 到 Postman 中进行测试
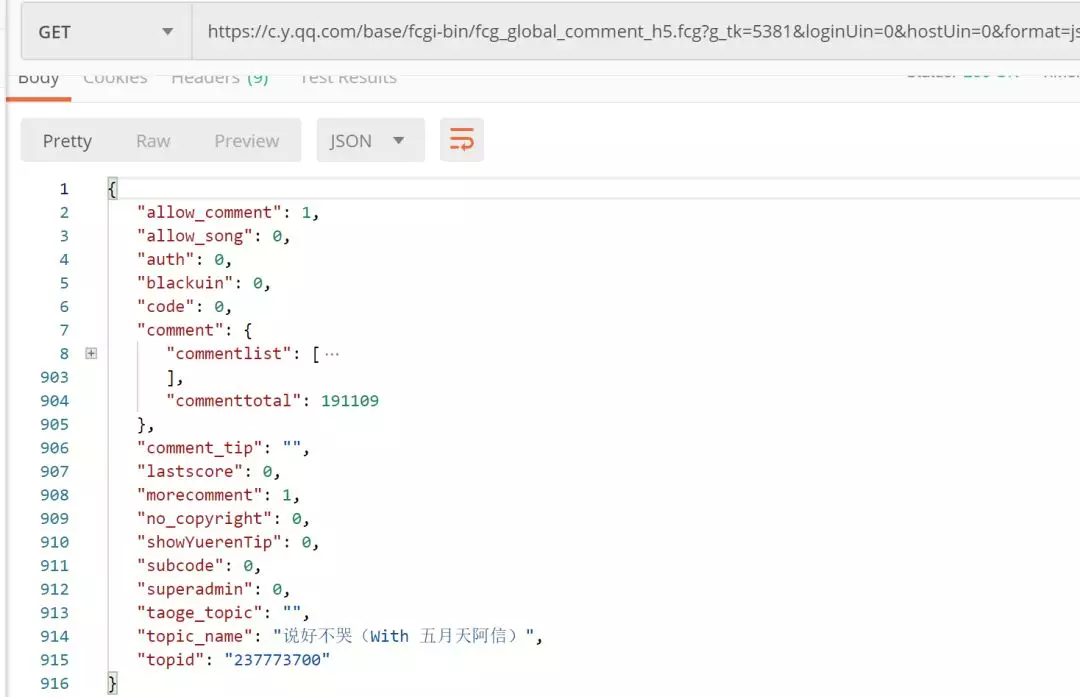
Postman测试
发现可以直接获取到数据
连 Header 都不需要添加
这里尝试对请求参数进行了精简
最终只需要如下几个参数即可
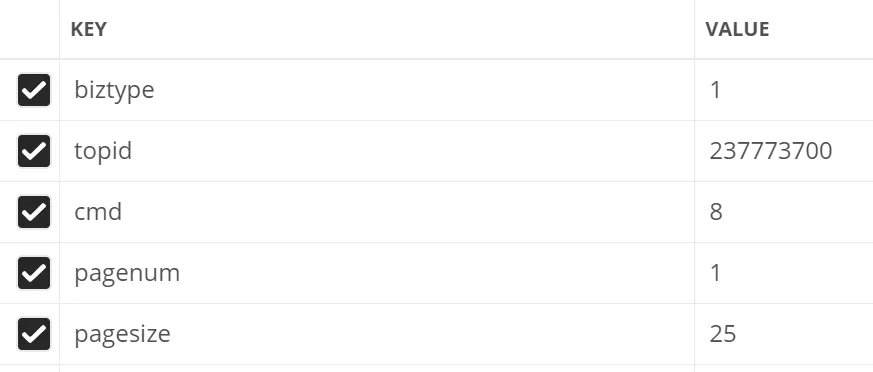
参数精简
从 Postman 中可以直接获取到对应的代码
import requests
url = "https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg"
querystring = {"biztype":"1","topid":"237773700","cmd":"8","pagenum":"1","pagesize":"25"}
response = requests.request("GET", url, params=querystring)
print(response.text)
这里是单页评论的获取
所有评论的获取只需递增 pagenum 即可
2、数据解析
返回数据中有很多暂时不需要的字段
这里我们只取其中的用户名、评论时间、评论内容、点赞数
对应如下字段
{
"nick": "丨那壹刻永遠消失\"\"",
"praisenum": 1,
"rootcommentcontent": "越听越好听怎么回事!",
"time": 1568729836,
}
由于数据量较大 这里我们暂时将数据存放在 Excel 中
一来无须依赖外部数据库
二来可以使用 Excel 对数据进行二次处理
数据存储代码如下:
def file_do(list_info, file_name):
# 获取文件大小
if not os.path.exists(file_name):
wb = openpyxl.Workbook()
page = wb.active
page.title = 'jay'
page.append(['昵称','时间','点赞数','评论'])
else:
wb = openpyxl.load_workbook(file_name)
page = wb.active
for info in list_info:
try:
page.append(info)
except Exception:
print(info)
wb.save(filename=file_name)
二、数据可视化
1、各时段的评论数
首先我们对评论按小时区间进行汇总
由于时间粒度比较小,这里对时间粒度进行了一些处理
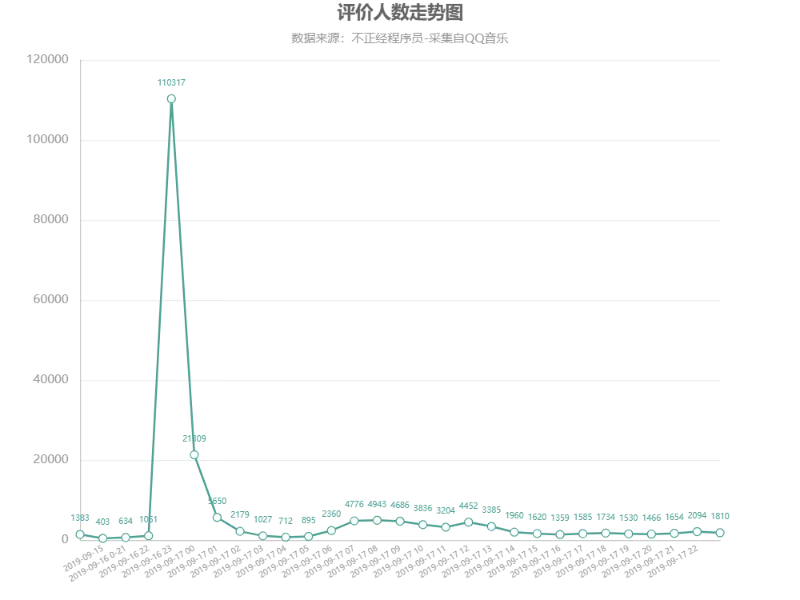
评价人数走势图
周董的新曲是在 9.16 号 23 点准时发布的
可以看出在发布后的一个小时内(23:00-24:00)
评论数量达到了高峰
占了总评论数的一半以上
另外看了一眼 9.16 23 点之前的评论也很有意思
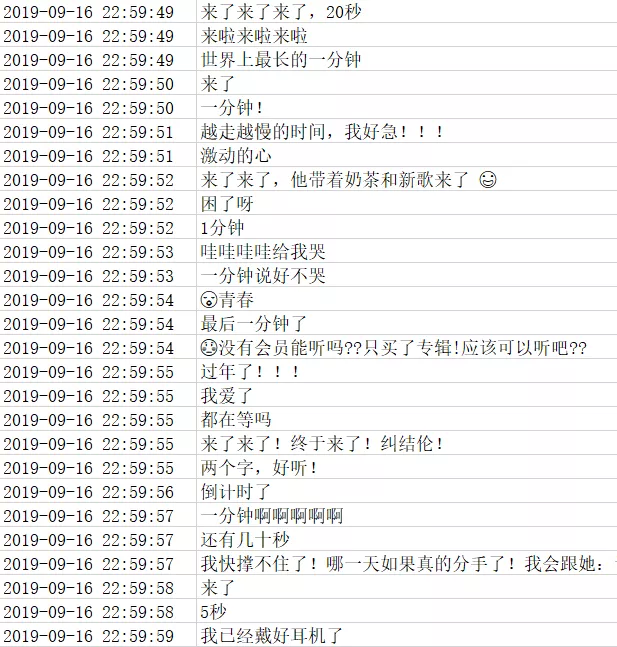
一种搬好小板凳嗑着瓜子坐等的既视感
2、大家都在说什么
词云生成的方法有很多
可以用代码生成
也可以用一些在线工具
这里我就使用了在线词云工具:wordart
后续可以给大家单独再普及一下
生成效果如下

词云
周杰伦、杰伦字眼很明显
还有大量跑来『打卡』的
『好听』、『来了』、『哭了』、『爱了』
其中少不了的还有『青春』
另外『阿信』的出现估计给了很多人惊喜
3、大家都点赞了哪些评论
我们以点赞数对评论进行了排序
排名靠前的评论是如下一些
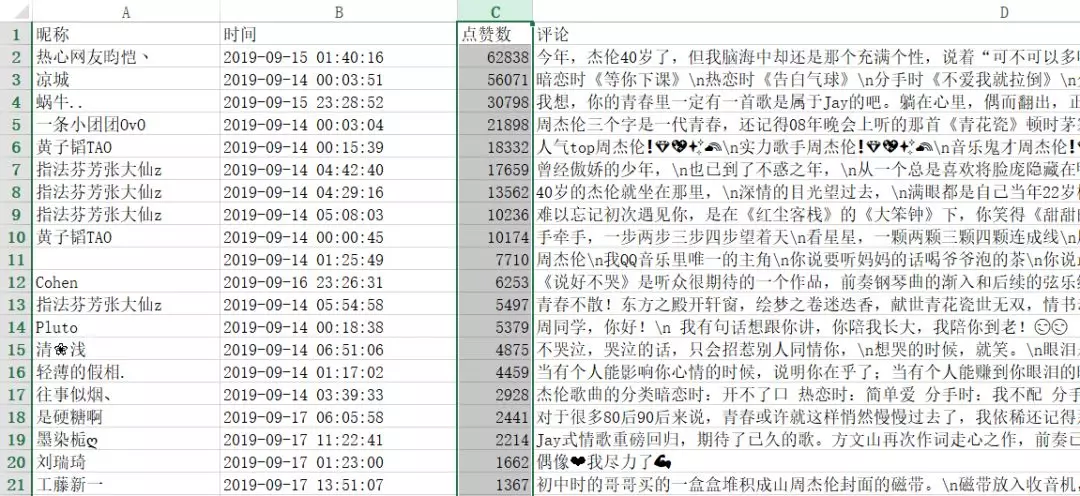
评论排名
另外,QQ 音乐官方也会放出精彩评论

热心网友昀恺丶

凉城

蜗牛..
对比下可以看出和我们获取到的数据是比较一致的
只不过官方并不是按点赞个数进行排名的
看得出来这些排名靠前的大都是在回忆青春
这些评论之所以能够得到大家的共鸣
也许他们的青春里都有一个周杰伦吧
三、附件
四、源码
1、评论爬取源码
import requests,json,time,uuid,os,openpyxl
import re
from openpyxl.cell.cell import ILLEGAL_CHARACTERS_RE
info_list = []
def get_comment_info():
global info_list
pagenum = 1
while(True):
print(pagenum)
url = "https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg"
querystring = {"biztype":"1","topid":"237773700","cmd":"8","pagenum":pagenum,"pagesize":"25"}
response = requests.request("GET", url, params=querystring)
resp = json.loads(response.text)
commentlist = resp.get('comment').get('commentlist')
if not commentlist or len(commentlist) == 0:
return
for comment in commentlist:
info = []
one_name = comment.get('nick')
# 将 UNIX 时间戳转化为普通时间格式
if comment.get('time') < 1568735760:
return
time_local = time.localtime(comment.get('time'))
one_time = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
one_praisenum = comment.get('praisenum')
one_comment = comment.get('rootcommentcontent')
ILLEGAL_CHARACTERS_RE.sub(r'', one_comment)
ILLEGAL_CHARACTERS_RE.sub(r'', one_name)
info = [one_name, one_time, one_praisenum, one_comment]
# print(info)
info_list.append(info)
pagenum += 1
# print(comment.get('nick'))
# print(comment.get('rootcommentcontent'))
# print(comment.get('time'))
# print(comment.get('praisenum'))
def file_do(file_name):
# 获取文件大小
if not os.path.exists(file_name):
wb = openpyxl.Workbook()
page = wb.active
page.title = 'jay'
page.append(['昵称','时间','点赞数','评论'])
else:
wb = openpyxl.load_workbook(file_name)
page = wb.active
for info in info_list:
try:
page.append(info)
except Exception:
print(info)
pass
continue
wb.save(filename=file_name)
if __name__ == "__main__":
file_name = str(uuid.uuid1()) + '.xlsx'
get_comment_info()
file_do(file_name)
print('data has saved in {}'.format(file_name))
2、生成HTML图表源码
# 导入Style类,用于定义样式风格
from pyecharts import Style
import json
# 导入Geo组件,用于生成柱状图
from pyecharts import Bar
# 导入Counter类,用于统计值出现的次数
from collections import Counter
import fileinput,re
# 设置全局主题风格
from pyecharts import configure
configure(global_theme='wonderland')
# 数据可视化
dates = []
comment_text = ""
def render():
global comment_text
with open('jay.csv', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows[1:]:
if row.count(',') != 3:
continue
elements = row.split(',')
user = elements[0]
date = elements[1]
if '2019' not in date:
continue
like = elements[2]
comment = elements[3]
if '2019-09-14' in date:
dates.append('2019-09-14')
elif '2019-09-15' in date:
dates.append('2019-09-15')
elif '2019-09-16 0' in date or '2019-09-16 1' in date or '2019-09-16 20' in date or '2019-09-16 21' in date:
dates.append('2019-09-16 0-21')
elif '2019-09-18' in date:
continue
else:
dates.append(date)
comment_text += comment
with open("comment_text.txt","w", encoding='utf-8') as f:
f.write(comment_text)
date_data = Counter(dates).most_common()
# 按日期进行排序
date_data = sorted(date_data)
# print(data)
# 根据评分数据生成柱状图
bar = Bar('评价人数走势图', '数据来源:QQ音乐网页版',
title_pos='center', width=800, height=600)
attr, value = bar.cast(date_data)
bar.add('', attr, value, is_visualmap=False, visual_range=[0, 3500], visual_text_color='#fff', is_more_utils=True,
xaxis_interval=0, xaxis_rotate=30,is_label_show=True,xaxis_label_textsize=8, label_text_size=8)
bar.render(
'picture\评价人数走势图.html')
render()
最后,一起来听一下这首歌吧~
这篇关于为什么python如此火爆_用Python来分析一波周董新曲《说好不哭》为何如此火爆!...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








