本文主要是介绍kaggle Optiver - Trading at the Close Baseline模型分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
kaggle又又又办了个量化比赛。
这里先分享了一个baseline模型,
baseline链接地址
比赛介绍
这里optiver的模型主要是试图建模尾盘的集合竞价阶段(占10%全天成交量),属于高频的交易模型。预测的周期是未来一分钟(哪里有成交量哪里就有高频交易者?),收益率貌似挺低的,这个模型做成策略该怎么交易?
相关的有趣参考文献
https://www.blackrock.com/corporate/literature/whitepaper/viewpoint-a-global-perspective-on-market-on-close-activity-july-2020.pdf
黑石发布的报告,描述了尾盘竞价的占比逐步在提升。
数据描述
该数据集包含纳斯达克证券交易所每日十分钟收盘拍卖的历史数据。您的挑战是相对于由纳斯达克上市股票组成的综合指数的未来价格走势来预测股票的未来价格走势。
这是一个使用时间序列API的预测竞赛。私人排行榜将使用提交期结束后收集的真实市场数据来确定。
文件
[train/test].csv拍卖数据。测试数据将通过API传递。
stock_id- 股票的唯一标识符。并非所有股票 ID 都存在于每个时间桶中。
date_id- 日期的唯一标识符。所有股票的日期 ID 都是连续且一致的。
imbalance_size- 按当前参考价格(美元)计算的金额不匹配。
imbalance_buy_sell_flag- 反映拍卖失衡方向的指标。
买方失衡;1
卖方失衡;-1
无不平衡;0
reference_price- 配对股票的价格按顺序最大化、不平衡最小化以及与买卖中点的距离最小化。也可以被认为等于最佳买价和卖价之间的近期价格。
matched_size- 以当前参考价格(美元)可匹配的金额。
far_price- 仅根据拍卖兴趣最大化匹配股票数量的交叉价格。此计算不包括连续市价订单。
near_price- 交叉价格将最大化基于拍卖和连续市价订单匹配的股票数量。
[bid/ask]_price- 非拍卖簿中最具竞争力的买入/卖出水平的价格。
[bid/ask]_size- 非拍卖簿中最具竞争力的买入/卖出水平的美元名义金额。
wap- 非拍卖簿中的加权平均价格。
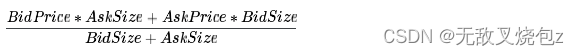
seconds_in_bucket- 自当天收盘竞价开始以来经过的秒数,始终从 0 开始。
target- 股票波动率的 60 秒未来走势,减去综合指数的 60 秒未来走势。仅适用于火车组。
综合指数是Optiver为本次大赛构建的纳斯达克上市股票定制加权指数。
目标的单位是基点,是金融市场的常用计量单位。1 个基点的价格变动相当于 0.01% 的价格变动。
其中 t 是当前观察的时间,我们可以定义目标:
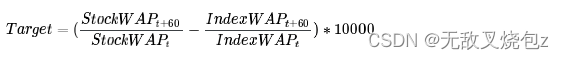
所有与尺寸相关的列均以美元计算。
所有与价格相关的列都会在拍卖期开始时转换为相对于股票 wap(加权平均价格)的价格变动。
Sample_submission由 API 提供的有效示例提交。请参阅此笔记本,了解如何使用示例提交的非常简单的示例。
Revealed_targets此文件中每个日期的第一个提供了整个前一个日期的time_id真实值。target所有其他行大多包含空值。
public_timeseries_testing_util.py一个可选文件,旨在使运行自定义离线 API 测试变得更容易。有关详细信息,请参阅脚本的文档字符串。
example_test_files/用于说明 API 如何运行的数据。包括 API 提供的相同文件和列。
optiver2023/启用 API 的文件。预计 API 将在五分钟内交付所有行并保留少于 0.5 GB 的内存。
baseline代码
特征工程
import pandas as pd
def generate_features(df):features = ['seconds_in_bucket', 'imbalance_buy_sell_flag','imbalance_size', 'matched_size', 'bid_size', 'ask_size','reference_price','far_price', 'near_price', 'ask_price', 'bid_price', 'wap','imb_s1', 'imb_s2']df['imb_s1'] = df.eval('(bid_size-ask_size)/(bid_size+ask_size)')df['imb_s2'] = df.eval('(imbalance_size-matched_size)/(matched_size+imbalance_size)')prices = ['reference_price','far_price', 'near_price', 'ask_price', 'bid_price', 'wap']for i,a in enumerate(prices):for j,b in enumerate(prices):if i>j:df[f'{a}_{b}_imb'] = df.eval(f'({a}-{b})/({a}+{b})')features.append(f'{a}_{b}_imb') for i,a in enumerate(prices):for j,b in enumerate(prices):for k,c in enumerate(prices):if i>j and j>k:max_ = df[[a,b,c]].max(axis=1)min_ = df[[a,b,c]].min(axis=1)mid_ = df[[a,b,c]].sum(axis=1)-min_-max_df[f'{a}_{b}_{c}_imb2'] = (max_-mid_)/(mid_-min_)features.append(f'{a}_{b}_{c}_imb2')return df[features]TRAINING = False
if TRAINING:df_train = pd.read_csv('/kaggle/input/optiver-trading-at-the-close/train.csv')df_ = generate_features(df_train)
模型训练
import lightgbm as lgb
import xgboost as xgb
import catboost as cbt
import numpy as np
import joblib
import os os.system('mkdir models')model_path ='/kaggle/input/optiverbaselinezyz'N_fold = 5if TRAINING:X = df_.valuesY = df_train['target'].valuesX = X[np.isfinite(Y)]Y = Y[np.isfinite(Y)]index = np.arange(len(X))models = []def train(model_dict, modelname='lgb'):if TRAINING:model = model_dict[modelname]model.fit(X[index%N_fold!=i], Y[index%N_fold!=i], eval_set=[(X[index%N_fold==i], Y[index%N_fold==i])], verbose=10, early_stopping_rounds=100)models.append(model)joblib.dump(model, './models/{modelname}_{i}.model')else:models.append(joblib.load(f'{model_path}/{modelname}_{i}.model'))return model_dict = {'lgb': lgb.LGBMRegressor(objective='regression_l1', n_estimators=500),'xgb': xgb.XGBRegressor(tree_method='hist', objective='reg:absoluteerror', n_estimators=500),'cbt': cbt.CatBoostRegressor(objective='MAE', iterations=3000),}for i in range(N_fold):train(model_dict, 'lgb')
# train(model_dict, 'xgb')train(model_dict, 'cbt')
模型提交
import optiver2023
env = optiver2023.make_env()
iter_test = env.iter_test()
counter = 0
for (test, revealed_targets, sample_prediction) in iter_test:feat = generate_features(test)sample_prediction['target'] = np.mean([model.predict(feat) for model in models], 0)env.predict(sample_prediction)counter += 1对于选择了关注的人,送一个简单的特征
由于auction分为两个阶段,把这两个阶段分别用01代表的话,也可以对模型有一定提升。
这篇关于kaggle Optiver - Trading at the Close Baseline模型分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






