本文主要是介绍国产系列 | Atlas 300I Pro 推理卡性能、应用场景、技术规格介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Atlas 300I Pro 推理卡是基于昇腾AI处理器的新一代高性能推理卡,融合“通用处理器、AI Core、编解码”于一体,提供超强AI推理、目标检索等功能,具有超强算力、超高能效、高性能特征检索、安全启动等优势,可广泛应用于OCR识别、语音分析、搜索推荐、内容审核等诸多AI应用场景。

性能特点
| 超强算力
单卡最大提供140 TOPS INT8算力,为数据中心推理提供更强大支持
支持 8 core * 1.9 GHz CPU计算能力
| 超高能效
提供 2 TOPS/W 超高能效比,达到业界2.1倍
高性能特征检索
支持特征检索硬件加速,亿级底库秒级查询(55亿次/秒),大幅提升检索比对性能
| 安全启动
设备启动链完整,启动初始状态确定,防止后端植入
可维护性特点
◆ 支持带内的在线升级,方便客户进行日常维护。
◆ 支持带内及带外获取温度、电压、功耗等设备状态信息,图形界面让管理更简单。
◆ 完备的命令行管理功能,用户可以通过各种命令进行日常的设备管理。
◆ 支持带内及带外资产管理功能,提供序列号等信息,方便资产管理。
典型应用场景
Atlas 300l Pro 推理卡典型应用场景为搜索推荐、内容审核和OCR系统。
搜索推荐系统主要根据用户输入( 用户画像、搜索词等),通过召回和排序算法,在内容池中筛选出最终推荐的素材(视频、文本等)。主要应用在互联网等领域。搜索推荐系统主要部件有推理服务器、客户端信息化系统软件组成,Atlas 300l Pro 推理卡部署在推理服务器中,主要实现用户数据类别召回、排序、重排序等推理功能。
内容审核系统主要采用了数据评级打分算法,实现了视频、图像、语音、文本等审核功能。主要应用在互联网等领域。内容审核系统主要部件有NLP服务器、中心管理服务器、信息化系统软件组成。Atlas 300I Pro 推理卡部署在NLP服务器中,主要实现视频、图像、语音、文本的审核校验等推理功能。
OCR系统主要采用了文本检测和文本识别算法,实现了身份证实名认证、票据识别、档案资料和信息录入、电子签名识别等功能。主要应用在智慧政务、智慧金融等领域。OCR系统架构主要部件有扫描仪、OCR服务器、中心管理服务器、信息化系统等软件组成。Atlas 300I Pro 推理卡部署在OCR服务器中,主要实现图片预处理、文本检测、文本识别、后处理校验等推理功能。
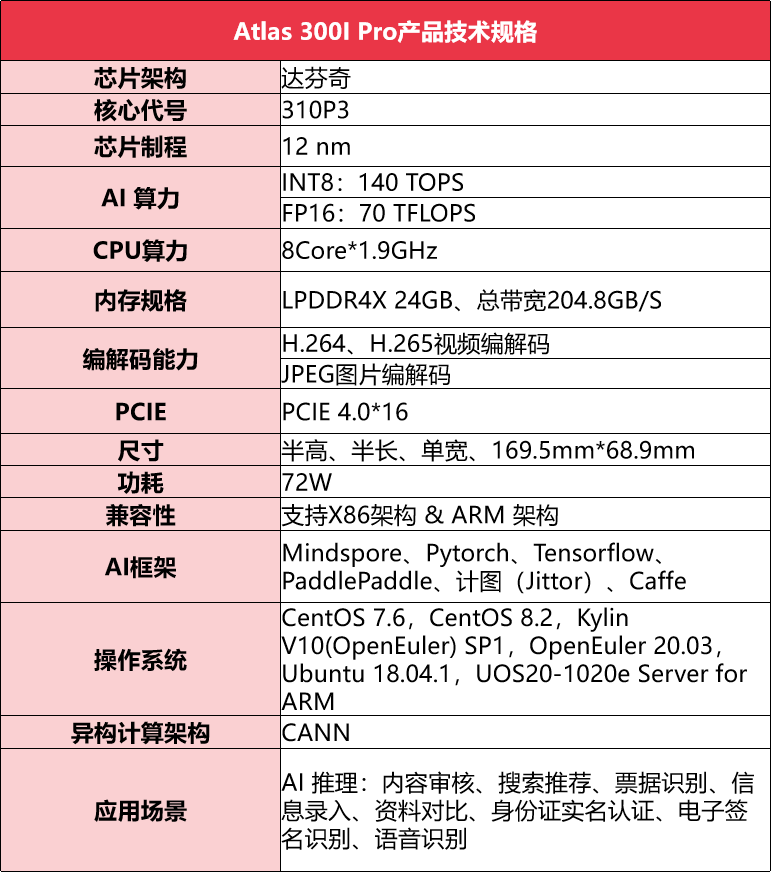
推理卡技术规格
这篇关于国产系列 | Atlas 300I Pro 推理卡性能、应用场景、技术规格介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




