本文主要是介绍python_寻找N字型下跌,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
写在前面:
思路拆解:
代码:
验证:
写在前面:
1 由于日线骗线多,本文寻找N字型下跌形态在周线级别操作
2 N字型下跌形态,技术辅助寻找的点:
1)左连阴 + 连阳 + 右连阴
2)连阴 和 连阳 的K线个数要大于等于3
3)在连阴里面有一字或十字或T或倒T,可以,但不能有红
4)在连阳里面有一字或十字或T或倒T,可以,但不能有绿
思路拆解:
1 从优矿中下载前复权日数据,以“湖南投资 000548” 为例
2 从日数据中提取周数据
def m_000():columns_list = ['tradeDate', 'openPrice', 'highestPrice', 'lowestPrice', 'closePrice']pre_dir = r'E:/temp011/'file_path = pre_dir + '000548.xlsx'df = pd.read_excel(file_path,engine='openpyxl')df = df.loc[df['openPrice']>0].copy()df['o_date'] = pd.to_datetime(df['tradeDate'])week_group = df.resample('W-FRI', on='o_date')week_df = week_group.last()week_df['openPrice'] = week_group.first()['openPrice']week_df['lowestPrice'] = week_group.min()['lowestPrice']week_df['highestPrice'] = week_group.max()['highestPrice']week_df = week_df.loc[:, columns_list].copy()week_df.dropna(axis=0, how='any', subset=['closePrice'], inplace=True)week_df.to_excel(pre_dir + 'week.xlsx',engine='openpyxl')pass3 思路
1)新增字段 row_i , 填充整型数列
2)新增字段 ext_1,标识阳线,阳线和收盘价开盘价一样的K线,记为1
3)新增字段 ext_2,标识阴线,阴线和收盘价开盘价一样的K线,记为1
4)将 ext_2 列每个数值与它的后一个数值相加,如果得数为2,说明相邻两个都为阴线

观察上图蓝色框、红色框、黄色框,都是连阴线,
ext_3 如果是 1 2 2,那这个1所在就是连阴线起始位置的前一个位置;
ext_3 如果是 2 2 1,那这个1所在就是连阴线结束位置
综上,
新增 yin_s,标识连阴线开始位置,连阴线开始位置,记为1
新增 yin_e,标识连阴线结束位置,连阴线结束位置,记为1
5) 为了方便说明,增加两个临时列,yin_s0,yin_e0, yin_s0=yin_s列的累加,yin_e0=yin_e列的累加,yin_s0和yin_e0的值正好是对应出现1的次数,也就是出现第几次的序号
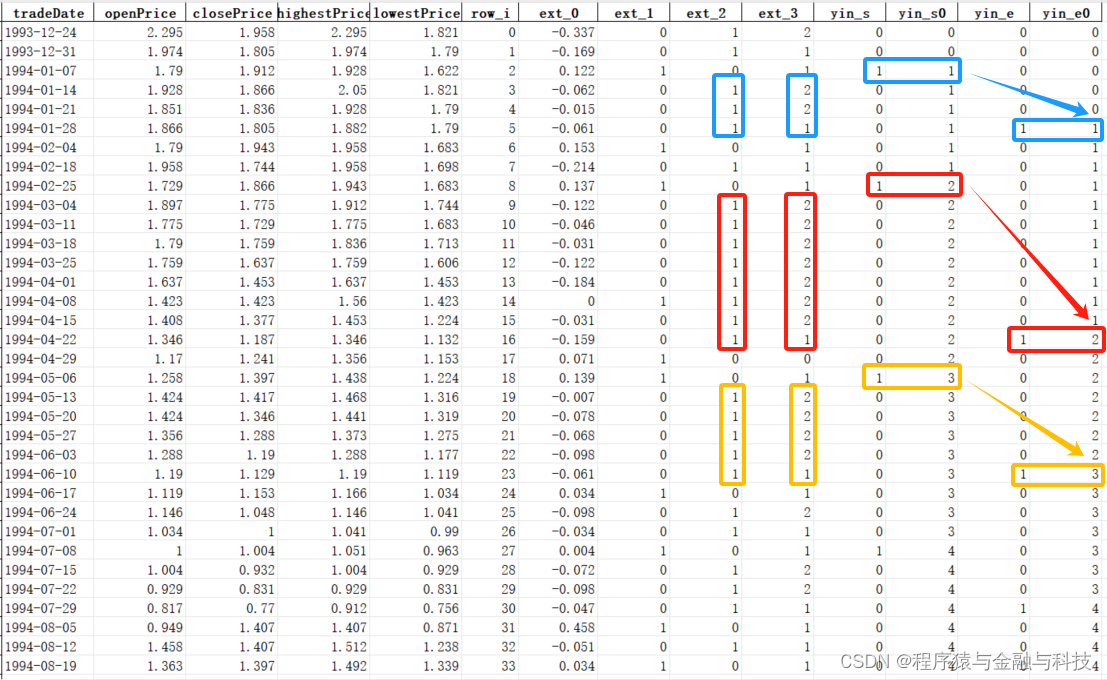
蓝色框是第一次出现连阴,yin_s0和yin_e0的值为1;
红色框是第二次出现连阴,yin_s0和yin_e0的值为2;
黄色框是第三次出现连阴,yin_s0和yin_e0的值为3;
综上,
yin_s和yin_e 序号一样的对应位置,正好是一个连阴的起点位置和终点位置,由此,可以获得每个连阴线的位置
6)N字型下跌,为连阴+连阳+连阴,已经找出所有连阴的位置,因此,只要校验两两连阴之间是否为连阳即可

ext_1 ==1 则为阳,那在两个连阴之间的间隔K线对应的 ext_1都为1的话,那就是连阳,对应到panda就是 两个连阴之间 ext_1的累加和等于间隔数据个数,那就是连阳
代码:
# 周线N字下跌
def m_001():file_path = r'E:/temp011/week.xlsx'df = pd.read_excel(file_path,engine='openpyxl')df = df.loc[:,['tradeDate','openPrice','closePrice','highestPrice','lowestPrice']].copy()df['row_i'] = [i for i in range(len(df))]df['ext_0'] = df['closePrice']-df['openPrice']df['ext_1'] = 0 # 阳线df.loc[df['ext_0']>=0,'ext_1'] = 1df['ext_2'] = 0 # 阴线df.loc[df['ext_0']<=0,'ext_2'] = 1# 寻找连阴df['ext_3'] = df['ext_2'] + df['ext_2'].shift(-1)df['yin_s'] = 0 # 连阴开始位置df.loc[(df['ext_3']==1) & (df['ext_3'].shift(-1)==2) & (df['ext_3'].shift(-2)==2),'yin_s'] = 1df['yin_e'] = 0 # 连阴结束位置df.loc[(df['ext_3']==1) & (df['ext_3'].shift(1)==2) & (df['ext_3'].shift(2)==2),'yin_e'] = 1# temp sdf['yin_s0'] = df['yin_s'].cumsum()df['yin_e0'] = df['yin_e'].cumsum()# temp edf_s = df.loc[df['yin_s']==1].copy()df_e = df.loc[df['yin_e']==1].copy()df_s['row_i0'] = [i for i in range(len(df_s))]df_e['row_i0'] = [i for i in range(len(df_e))]df_s.reset_index(inplace=True)df_e.reset_index(inplace=True)s_max = len(df_s)-1e_max = len(df_e)-1res_list = []for i in range(len(df_e)):if (i+1)>s_max or i>e_max:breake_one = df_e.loc[df_e['row_i0']==i].copy()s_one = df_s.loc[df_s['row_i0']==(i+1)].copy()e_row = e_one.iloc[0]['row_i']s_row = s_one.iloc[0]['row_i']if s_row-e_row<4:continuedf_one = df.loc[(df['row_i']>e_row) & (df['row_i']<s_row)].copy()df_one.reset_index()df_one['sum'] = df_one['ext_1'].cumsum()if df_one.iloc[-1]['sum'] == len(df_one):# 连阳s_p = df_s.loc[df_s['row_i0']==i].iloc[0]['row_i']e_p = df_e.loc[df_e['row_i0']==(i+1)].iloc[0]['row_i']res_list.append([s_p,e_p])passpassprint(res_list)pass结果:[[828, 842], [888, 908]]
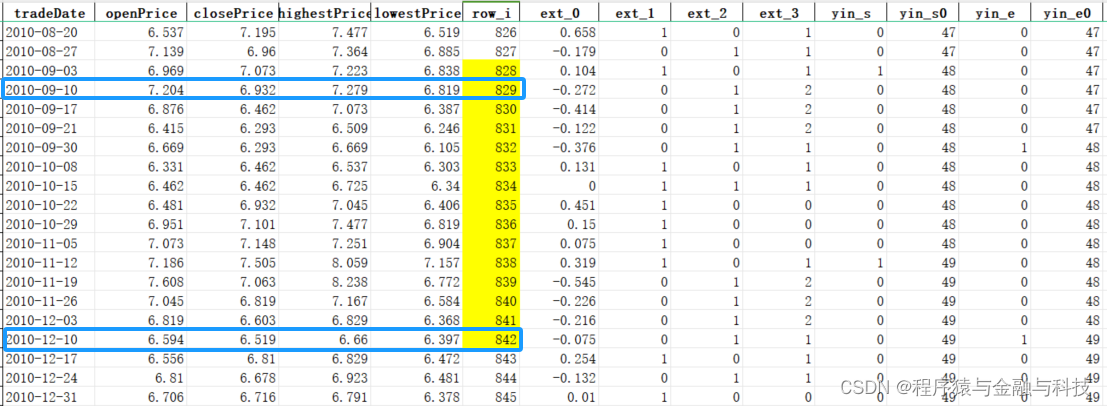
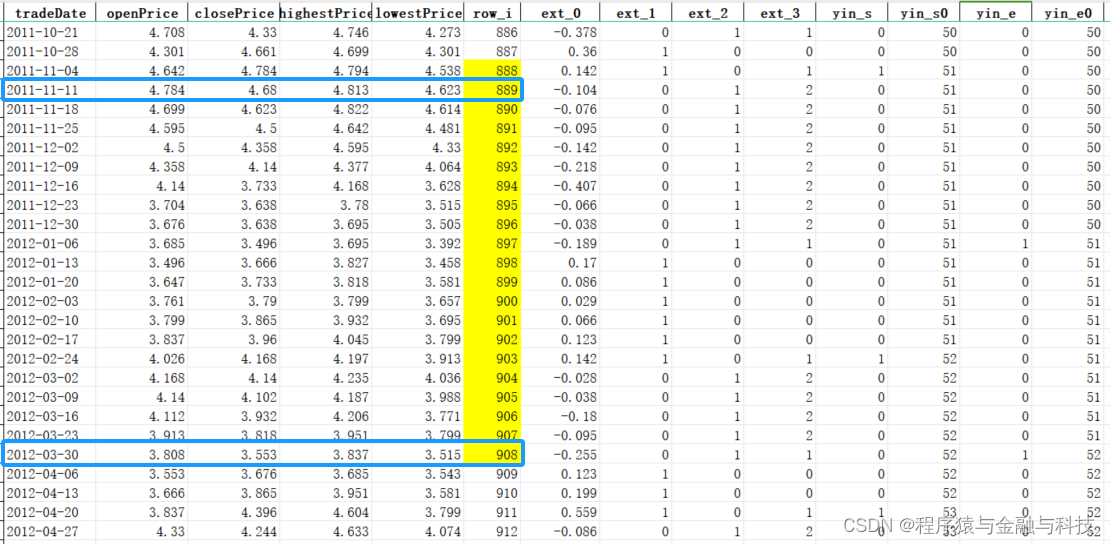
即,有两个N字型下跌,第一个起点row_i=828,结束row_i=842;第二个起点row_i=888,结束row_i=908
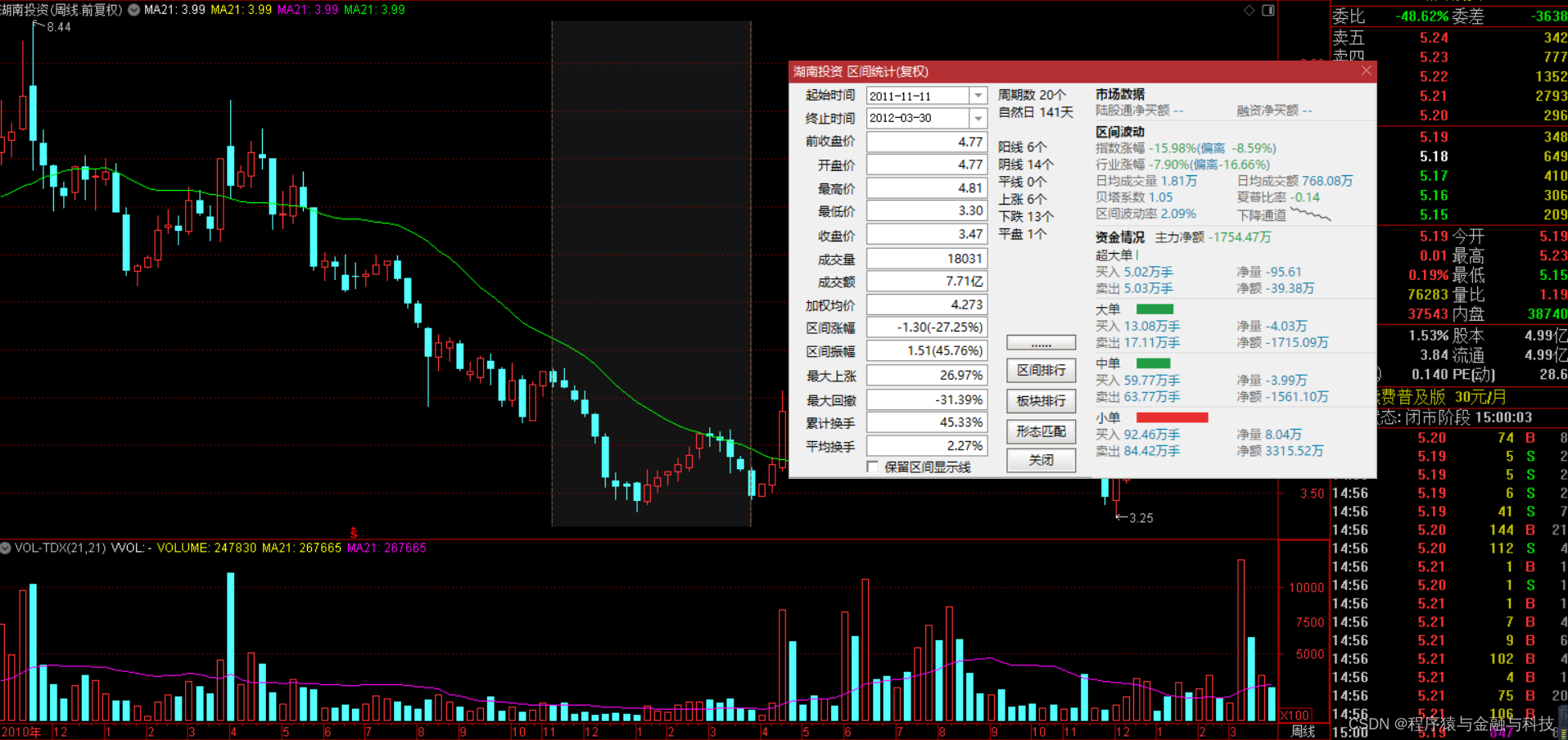
验证:
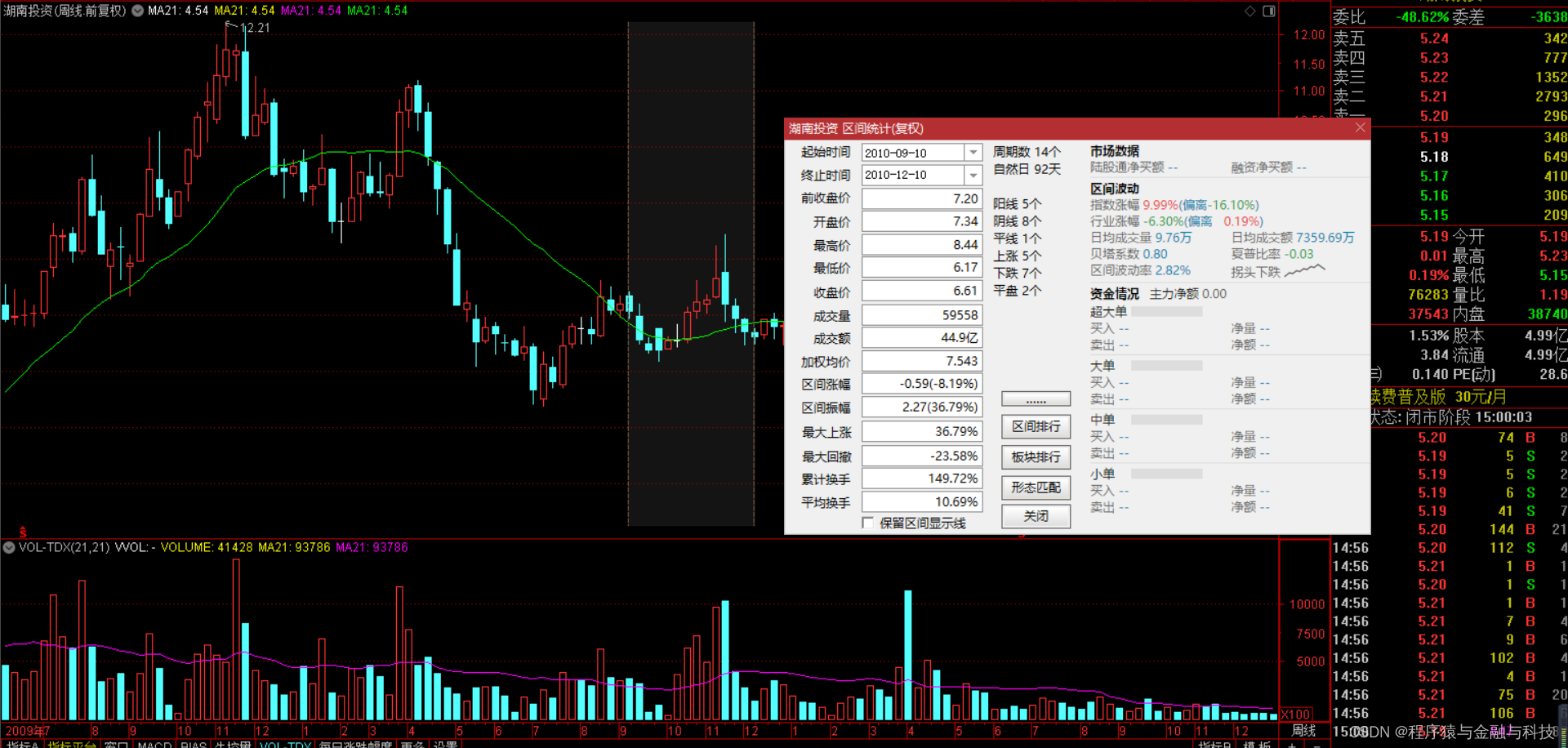
第一个 2010年9月10日 到 2010年12月10日
第二个 2011年11月11日 到 2012年3月30日
这篇关于python_寻找N字型下跌的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








