本文主要是介绍HashData携手XSKY 助力企业构建数据智能底座,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近日,酷克数据联合XSKY星辰天合共同推出了云原生数据平台解决方案(以下简称“解决方案”)。基于双方核心产品技术特性和优势,该解决方案采用湖仓一体、存算分离架构,融合数据仓库、数据湖、对象存储的优势,能够高效管理海量规模数据,满足企业多样化的大数据应用需求。
经过双方产品的适配、测试和针对性优化,部署于XSKY XEOS 对象存储的HashData云数仓,完美满足OLAP场景中的数据访问性能与稳定性要求,并且在可靠性、持久性、灵活性具有比HDFS开源存储系统更优异的性能表现,实现了计算节点与存储节点分别部署,各自独立扩缩容以及平滑升级演进等能力,充分体现出存算分离架构的强大性能及高扩展性。
为方便广大用户了解该联合解决方案优势,双方技术专家通过线上研讨会的形式对方案特性进行了详细讲解。
架构升级 让数据分析更高效更智能
随着内外部异源数据的指数级增加,如何建设能力全面、稳定可靠、成本合适的大数据平台,始终是企业数字化和智能化发展过程中的关注点。
传统大数据平台普遍采用存算紧耦合的架构,存在数据孤岛、数据冗余、建设成本高、后期运维繁琐等诸多不足,难以满足当前数字化转型需求。

图1:HashData云数仓架构图
为了帮助企业应对数据爆炸式增长带来的挑战,更高效、灵活地管理和利用各类数据,酷克数据和XSKY星辰天合推出了基于云原生架构的数据平台解决方案。依托HashData云数仓领先的技术优势和XSKY对象存储产品特性,解决方案面向用户提供了云原生的消费方式,利用“一份数据”的做法,消除了不必要的数据冗余,构建了统一的数据空间,可以显著地降低企业数据分析的成本,同时极大地增加了数据分享的便利性。
- 归集全域数据:所有用户数据集中存储,逻辑上只保存一份数据,数据的高可用由存储层进行保障,消除业务层面的数据冗余,确保数据的一致性,真正意义上消除了数据孤岛。
- 降低数据治理复杂度:数据平台融合,大幅降低次生数据质量问题;同时便于元数据、主数据和数据标准的管理;可以集中化进行数据安全管理,减少安全漏洞产生的环节。
- 强大的数据存储能力:对象存储具备高效的小文件处理能力,更适合结构化、非结构化数据处理和存储。解决方案支持单桶千亿,满足超大规模数据平台容量需求。
- 便捷数据共享:除了共享脱敏数据外,还可以通过无状态的计算集群共享计算资源,或者整合PaaS和SaaS直接共享数据服务,实现数据协同与融合共创。
- 高可用云基础架构:基于云原生带来跨区域的高可用能力,保障了数据平台的弹性扩展,秒级故障自愈的能力,确保了数据平台的高可用与稳定性能保障,提升业务连续性。
- 增强数据服务能力:通过云原生的PaaS服务,提供弹性的数据计算和加工资源,便于业务人员快速获取与使用数据,以应对市场的快速变化,支持业务更加敏捷地面向市场。
针对蓬勃发展的人工智能技术,HashData基于in-database AI的理念,设计了两种计算引擎:针对SQL查询分析任务的MPP计算引擎,以及针对机器学习和深度学习任务的ML/DL计算引擎。同时,HashData内置了自研的AI开发工具箱HashML,支持ML、DL、LLM的训练、微调和推理任务。
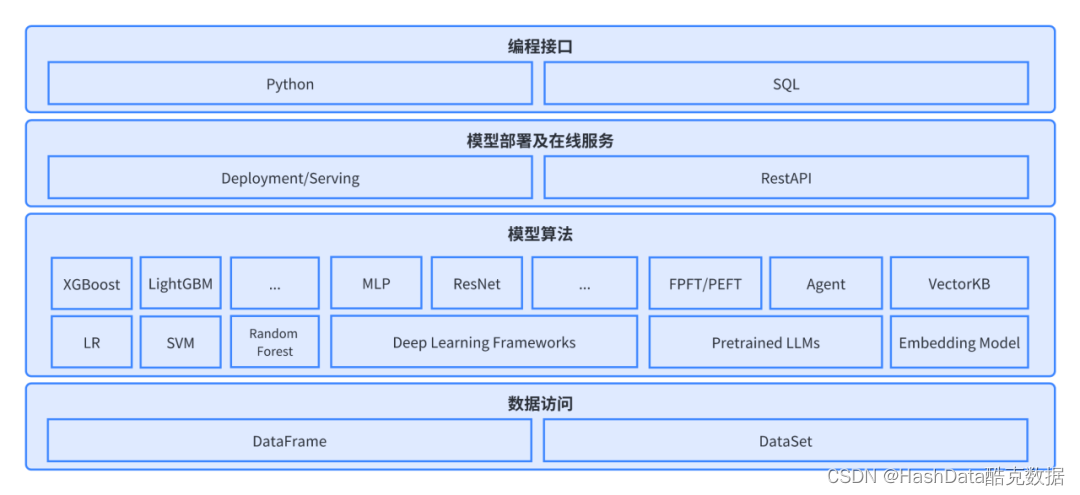 图2:HashML主要功能概览
图2:HashML主要功能概览
HashData还实现了对大规模向量数据的高效存储和检索,使得基于知识增强的LLM智能应用搭建变得更加简单,帮助企业以极低的成本、极高的效率微调定制若干个领域模型,轻松搭建包括智能问答、自然语言转SQL、辅助写作、辅助分析等智能应用。
携手共赢 打造自主可控数据库生态
作为国内最早专注于云原生数仓研发推广的企业,酷克数据从成立之初就致力于打造世界一流云数仓产品,并努力打造自主可控数据库生态。
HashData和XSKY的合作可以追溯到2018年,是国内企业级市场中最早利用对象存储管理海量结构化数据的落地方案之一,双方合作的技术方案已在金融、电信、科研等领域实现大规模商用,并稳定运行多年。
此外,HashData积极与芯片、中间件、应用软件、硬件等生态上下游厂商保持紧密的协同合作,构建完善的数据库生态体系。目前,HashData已经与华为云鲲鹏体系、飞腾芯片、海光芯片、麒麟操作系统(鲲鹏版+飞腾版)、统信操作系统(飞腾、腾云、鲲鹏916、鲲鹏920)等完成兼容性认证。
未来,HashData将继往开来发挥在数据库领域的核心技术优势,更好地满足客户在数智化时代对数据驱动业务发展的需求。
附:直播问答节选
1、HashData 主要应用的行业有哪些?
专家解答:HashData 数据平台是通用型数据底座,目前客户广泛分布在金融、电信、政府、能源、交通、科研、互联网等领域。
2、HashData 大模型托管服务需要什么样的显卡?
专家解答:HashData 支持常见的商业和开源大模型。基础设施的配置有很多影响因素,如业务场景要求、模型规模等。在私有化环境部署十亿级或百亿级参数语言模型的推理和模型微调的起步配置要求并不高。
3、满足各种权限要求同时如何保证数据的绝对安全呢?
专家解答:数据安全是一个很大的话题,对于存储来说,可以从以下几个方面考虑:
■ 底层架构,如:分布式存储底层算法的一致性,缓存算法等;
■ 权限管理,包括:存储管理操作的权限、数据管理的权限;
■ 数据保护相关功能,如:加密、审计、回收站、备份、容灾等多个方面来保证数据的绝对安全。
这篇关于HashData携手XSKY 助力企业构建数据智能底座的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




