本文主要是介绍利用python实现对GS1-128条码的识别以及对部分应用标识符(AI)的识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
条形码课程实验
任务需求:根据所学的知识,设计一个针对GS1-128条码的计算机自动识别软件系统技术方案,并编程实现之。
功能要求:
1:可自动识别SSCC条码;
2:可自动识别包含表6-88(P183)1的Al标识符;
3:可自动识别含有401,402,403,410,413,420,421,310n,330n等Al标识符
4:可自动识别具有链接功能GS-128条码
5:可双向自动识别GS1-128条码
6:具有友善的人机接口,能读取印制有GS1-128条码的图像文件(jmp,or JPEG任选一种即可,可不必考虑图像的旋转)识读出其对应代码在屏幕上显示出来。
7:每次只在水平方向上测试一个符合GS1-128条码长度尺寸及字符数量要求的条码;
在做这个实验设计的时候,我还没有了解到pyQt,所以是队员使用tkinter编写的界面,不过本次实验也确实是我学习pyQt的契机,为我打开了一扇简易图形化程序设计的大门,也让我更加深入地体会了Python的美妙。
考虑到需要图像识别等等操作,为了简便,我和组员选择了相对较为简单的Python语言,不再多言,直接进入正题。
提取图像信息
我们应该知道条形码的条空排列记载了信息,就如同英文字幕的排列构成不同的单词,不够条形码的规则更严格,要识别条形码,就必须要得到条形码的条空排列,条空宽度,那么如何从一张条形码图像中得到我们需要的条空组合的信息呢?

第一感觉是图像识别,但是此前我们完全没有类似的开发经验,所幸,我们在简书上找到了一篇译文《怎样用Python识别条形码?[译]》2,里面也对条形码的编码规则作了一个大致介绍,我们采用了上面的方式获取图像中的信息。
大体思想就是:使用python的crop截图操作,从图片中间截取高度为1像素,宽度等于原图的图,这个图等同于一条线,转化成灰度图,再使用np.asarray()得到每个像素的颜色值,0为黑色,255为白色,为了方便条为1,白为0,我们对黑白进行倒转。
img = Image.open(image_path) #载入图片width, height = img.size #获取图片宽高basewidth = 3*width #拉伸三倍宽度以使得数据图更直观,对解码没影响 img = img.resize((basewidth, height), Image.ANTIALIAS) #设置图片宽高 hor_line_bw = img.crop((0, int(height/2), basewidth, int(height/2) + 1)).convert('L') #从正中间切割一条像素宽度为1的线 hor_data = np.asarray(hor_line_bw, dtype="int32")[0] #获取线的像素颜色值,黑色为0,白色为255 hor_data = 255 - hor_data #倒转数据使得大数代表(黑)条 avg = np.average(hor_data) #求平均值作为分界线
到这一步,可以将获得的像素值进行绘图,看看情况
plt.plot(hor_data)plt.show()
此为绘制手机拍书上的条形码得到的数据图,虽然十分不整齐,但是依然可以识别出正确数据,证明采用平均值作为判断条空的依据是很合理的

此为条形码生成网站生成的标准条形码图

求取单位宽度
得到条码图像信息之后,就要开始对其解码,GS1-128条码除了终止符,其它的都由11个单位条空单元组成,例如数字“01”,就可以被编码成“11001101100”,可是不同图像有不同的大小,随之条空的宽度也会不同,那么我们如何知道一个条或空是几个单位构成的呢?一个条到底是“11”,还是“111”?
所幸虽然绝对宽度在变化,但是一个正确的条码,宽度比例应当是不变的,所以我们要通过一些方式,算出每一张图片中一个单位的宽度,结合GS1-128条码的起始符是“1101”,于是就有了如下方法
pos1, pos2 = -1, -1 #初始化bits = "" for p in range(basewidth - 2): if hor_data[p] < avg and hor_data[p + 1] > avg: #如果从空到条bits += "1"if pos1 == -1: #如果还没有对pos1赋值,也就是还没有遇到过条pos1 = p #记录此时p的指向,指向第一个条的前一个位置if bits == "101": #如果已经遍历完了起始符“1101”pos2 = p #记录此时p的指向,指向“1101”中的“0”breakif hor_data[p] > avg and hor_data[p + 1] < avg: #由条入空bits += "0"bit_width = int((pos2 - pos1)/3) #完成上诉操作后(pos2 - pos1)应该就是“110”,因此除以3即可得到单位宽度
得到条码的数字信息
得到单位宽度后,获得数字信息就变得非常容易,将每一个的条或空长度除以单位宽度,就可以得到该条(空)的数字编码信息
for p in range(basewidth - 2):if hor_data[p] > avg and hor_data[p + 1] < avg:interval = p - pos1cnt = interval/bit_widthbits += "1"*int(round(cnt))pos1 = pif hor_data[p] < avg and hor_data[p + 1] > avg:interval = p - pos1cnt = interval/bit_widthbits += "0"*int(round(cnt))pos1 = p
对一个GS1-128条码,应该能得到类似“11010010000111101011101011101111011001101100101111010001100110110011101101110101110110001000010110011011011110100100110001101100011011001100110110110011001001000110011011001100101110001101100011101011”的信息
以上就是《怎样用Python识别条形码?[译]》中的方法,确实很厉害。
开始解码
现在开始,我们需要自己针对GS1-128进行解码,首先,我们导入想应的字符集
CODE128_CHART = """_ _ 00 212222 11011001100 ! ! 01 222122 11001101100 " " 02 222221 11001100110 # # 03 121223 10010011000 $ $ 04 121322 10010001100 % % 05 131222 10001001100 & & 06 122213 10011001000 ' ' 07 122312 10011000100 ( ( 08 132212 10001100100 ) ) 09 221213 11001001000 * * 10 221312 11001000100 .......(略)RS ~ 94 131141 10001011110 US DEL 95 114113 10111101000 FNC3 FNC3 96 114311 10111100010 FNC2 FNC2 97 411113 11110101000 SHIFT SHIFT 98 411311 11110100010 CODEC CODEC 99 113141 10111011110 CODEB FNC4 CODEB 114131 10111101110 FNC4 CODEA CODEA 311141 11101011110 FNC1 FNC1 FNC1 411131 11110101110 StartA StartA StartA 211412 11010000100 StartB StartB StartB 211214 11010010000 StartC StartC StartC 211232 11010011100 Stop Stop Stop 2331112 11000111010 """.split()
再将字符集按照A、B、C三个子集进行划分,并采用字典完成条空编码与其对应意义字符的映射(吹爆python的字典)
SYMBOLS = [value for value in CODE128_CHART[4::5]]VALUESA = [value for value in CODE128_CHART[0::5]]VALUESB = [value for value in CODE128_CHART[1::5]] VALUESC = [value for value in CODE128_CHART[2::5]]CODE128A = dict(zip(SYMBOLS, VALUESA))CODE128B = dict(zip(SYMBOLS, VALUESB))CODE128C = dict(zip(SYMBOLS, VALUESC))
然后我们将之前得到的数字编码先每11个分一组,以便我们进行映射解码,我们设置flag来识别具体使用ABC哪个字符集进行解码,flag_num判断这个条形码是否可读
sym_len = 11flag=0flag_num=0while flag==0:symbols = [bits[i:i+sym_len] for i in range(0, len(bits), sym_len)] #将字符每11位分组sum = len(symbols)mark=0str_out = ""if symbols[0] == "11010000100": #start A flag = 1;elif symbols[0] == "11010010000": #start Bflag = 2;elif symbols[0] == "11010011100": #start Cflag = 3;else: #此时条码应该是从右往左读bits=bits[::-1] #倒置实现双向识别flag_num+=1if flag_num==2:self.result_data_Text.insert(END,"非正确条码,请注意条码图片中心线是否被污染")break
开始解码
if flag_num<2:#开始解码for sym in symbols:mark+=1Aif sym in CODE128A or sym in CODE128B or sym in CODE128C: #判断字符词典中是否有此标识if mark==sum-2: #扫描至结束符之前breakif flag==1:str_out += CODE128A[sym]print(" ", sym, CODE128A[sym])self.result_data_Text.insert(END," "+sym+" "+CODE128A[sym]+"\n")if CODE128A[sym]=="CODEB":flag=2elif CODE128A[sym]=="CODEC":flag=3elif flag==2:str_out += CODE128B[sym]print(" ", sym, CODE128B[sym])self.result_data_Text.insert(END," "+sym+" "+CODE128B[sym]+"\n")if CODE128B[sym]=="CODEA":flag=1elif CODE128B[sym]=="CODEC":flag=3elif flag==3:str_out += CODE128C[sym]print(" ", sym, CODE128C[sym])self.result_data_Text.insert(END," "+sym+" "+CODE128C[sym]+"\n")if CODE128C[sym]=="CODEA":flag=1elif CODE128C[sym]=="CODEB":flag=2else:self.result_data_Text.insert(END,"非正确条码,请注意条码图片中心线是否被污染")flag_num=2break
然后我们应该可以得到类似下图的信息
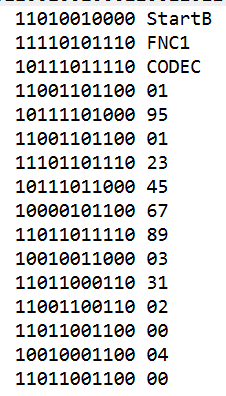
去掉一些非数据符号
str_out=str_out.replace('StartA','')str_out=str_out.replace('StartB','')str_out=str_out.replace('StartC','')str_out=str_out.replace('CODEA','')str_out=str_out.replace('CODEB','')str_out=str_out.replace('CODEC','')#str_out=str_out.replace('FNC1','') 为了识别可变长字符串,只能去掉开头的FNC1if str_out[0:4]=="FNC1":str_out=str_out[4:]str_out=str_out.replace('FNC2','')str_out=str_out.replace('FNC3','')if flag_num<2:print("Str:", str_out)self.result_data_Text.insert(END,"Str:"+str_out+"\n"+"\n")
如此便可得到类似“01950123456789033102000400”的条码数据,此数据除了没有括号标出应用标识符,以及部分情况存在的数据中断符(FNC1),应当与条码的供人识读字符一样
应用标识符识别
这一部分尤为繁琐,主要是类型较多,故仅举例说明
例一:0开头
p=0 #标识符指针,专门指向应用标识符,从一个跳到下一个标识符num=len(str_out)while p<num: #指针是否遍历完字符串if str_out[p]=="0": #应用标识符的第一位a=list(str_out) #列表化方便插入括号a.insert(p,"(")a.insert(p+3,")")str_out="".join(a) #转化回字符串if str_out[p+2]=="0": #sscc 00 print("SSCC"+str_out[p+4:p+22]) #SSCC替代字符的00输出self.result_data_Text.insert(END,"SSCC"+str_out[p+4:p+22]+"\n"+"\n")p=p+22 #移动指针,到下一个标识符所在位置num=num+2 #长度加上新增的括号elif str_out[p+2]=="1": #GTIN 01print("GTIN"+str_out[p+4:p+18])self.result_data_Text.insert(END,"GTIN"+str_out[p+4:p+18]+"\n"+"\n")p=p+18num=num+2elif str_out[p+2]=="2": # 02print("CONTENT"+str_out[p+4:p+18])self.result_data_Text.insert(END,"CONTENT"+str_out[p+4:p+18]+"\n"+"\n")p=p+18num=num+2
应用标识符的难点主要在于指针位置的变化,以及需求字符串的起止位置的问题
例二:变长字符
elif str_out[p]=="4": #应用标识符的第一位a=list(str_out) a.insert(p,"(")a.insert(p+4,")")str_out="".join(a) if str_out[p+2]=="0": #可变长度字符串 应用标识符的第二位j=0 for i in range(num+2-p+1): #num+2-p为此应用标识符后端长度,多加1使得当无分隔符时仍可完整输出全部码值if str_out[i]=="F": #遇到FNC1j=i #记录指针p到FNC1数据分割符的距离breakif str_out[p+3]=="1": #应用标识符的第三位print("CONSIGNMENT"+str_out[p+5:p+j])self.result_data_Text.insert(END,"CONSIGNMENT"+str_out[p+5:p+j]+"\n"+"\n")elif str_out[p+3]=="2": #应用标识符的第三位print("SHIPMENT NO."+str_out[p+5:p+j])self.result_data_Text.insert(END,"SHIPMENT NO."+str_out[p+5:p+j]+"\n"+"\n")elif str_out[p+3]=="3": #应用标识符的第三位print("ROUTE"+str_out[p+5:p+j])self.result_data_Text.insert(END,"ROUTE"+str_out[p+5:p+j]+"\n"+"\n")p=p+j+4 #"+j"跳过此段数据,“+4”跳过FNC1,抵达下一个AInum=num+2elif str_out[p+2]=="1": #应用标识符的第二位if str_out[p+3]=="0": #应用标识符的第三位print("SHIP TO LOC"+str_out[p+5:p+18])self.result_data_Text.insert(END,"SHIP TO LOC"+str_out[p+5:p+18]+"\n"+"\n")elif str_out[p+3]=="3": #应用标识符的第三位print("SHIP FOR LOC"+str_out[p+5:p+18])self.result_data_Text.insert(END,"SHIP FOR LOC"+str_out[p+5:p+18]+"\n"+"\n")p=p+18num=num+2elif str_out[p+2]=="2": #可变长度字符串 应用标识符的第二位j=0 #到FNC1数据分割符的距离for i in range(num+2-p+1):if str_out[i]=="F":j=ibreakif str_out[p+3]=="0":print("SHIP TO POST"+str_out[p+5:p+j])self.result_data_Text.insert(END,"SHIP TO POST"+str_out[p+5:p+j]+"\n"+"\n")elif str_out[p+3]=="1":print("SHIP TO POST"+str_out[p+5:p+j])self.result_data_Text.insert(END,"SHIP TO POST"+str_out[p+5:p+j]+"\n"+"\n")p=p+j+4 #"+j"跳过此段数据,“+4”跳过FNC1,抵达下一个AInum=num+2print(str_out.replace('FNC1','')) #输出不带FNC1的信息(标识符带括号) self.result_data_Text.insert(END,str_out.replace('FNC1','')+"\n"+"\n")
这一部分注释较为丰富,就不作过多阐述。
总结
以上便是利用python实现对GS1-128条码的识别以及对部分应用标识符(AI)的识别的整个流程。
通过此次实验,我深入了解了GS1-128条码的编码规则和译码流程,对其结构有了更加直观的认识,更重要的是,这次实验让我对python编程有了第一次的深入实战操作,体会到了python编程的乐趣,并以此为契机,通过pyQt让我打开了可视化编程的大门,从此不再是小黑框程序员😂,成功晋级大二上学期平均水准。
定长字符前缀表 ↩︎
原文《How does a barcode work?》 ↩︎
这篇关于利用python实现对GS1-128条码的识别以及对部分应用标识符(AI)的识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



