本文主要是介绍闪存误码根源分析及测试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Bit错误从Nand Flash物理机构上来说是不可避免的问题,Nand Flash受外界工作环境(如:温度、辐照等)和生产工艺、工作原理、存储材料本身的弊端等影响,总会在各种条件下产生错误。误码率是表明在一定条件下产生错误的比率,反映Nand Flash当前的可靠性状态。
产生误码的物理根源
Cell的本身是个浮栅(Floating Gate,以下缩写为FG)结构的MOS型晶体管,工作原理是通过对FG注入或者释放电荷改变存储单元的阈值电压来达到存储或释放数据的目的。Program“0”通过Control Gate施加电压将电荷注入FG、Erase的过程则是施压反向电压,通过隧道效应(以下简称FNT)将电荷拉出FG,隧道效应会因基板表面附近的单一氧化层能陷捕获或者泄露电子产生随机电信号噪音,这种噪音最终导致阈值电压发生偏移。
随着制程的进步,FG之间的半间距(HalfPitch)越来越小,从1995年的360纳米快速缩减到今天的16纳米,这种因制程进步而对CMOS进行不断压缩的工艺,会对Nand Flash的可靠性造成诸多方面的影响,例如,FG中存储的电荷数量减少,34纳米的FG中,大约存100个电子,电荷流失容限约为10个电子,而在19纳米,FG中大约只有10个电子,因此,每流失一个电子都会对阈值电压产生重要的影响。较近的距离也会让各个存储单元之间更容易产生影响,另外,FG在电压和电场的作用下会导致经时击穿(TDDB,与时间相关的电介质击穿)或者电介质老化,从而导致Bit发生错误。
Erase和Program的操作也会导致氧化层收集电荷,这样会影响到cell的阈值电压,当电荷脱井时,阈值漂移,Bit发生反转。
塑封工艺也是导致错误发生的隐患,Nand Flash采用的主要的塑封电路,塑封工艺会存在吸湿、分层、热传导、空洞等问题,因此,操作严格的工厂,在SMT之前都会预先对Nand Flash进行烘烤,目的就是避免芯片吸湿后受热导致芯片破裂或表面鼓泡,当然,芯片破裂是最严重的问题,即使表明没有破裂也会存在内部物理结构损坏的安全隐患。
误码产生的表现
Bit错误会在下面几种情况下产生:
1、 擦写操作(P/ECycle)
2、 读取干扰(ReadDisturb);
3、 编程干扰(ProgramDisturb);
4、 数据保持发生错误(DataRetention)。
读取/编程干扰主要是因为对目标Cell进行读写操作时对相邻Cell产生了影响(改变了临近Cell的阈值电压或电场),从而导致相邻Cell数据出现错误。
而数据保存错误则是由于氧化层带了越来越多的残留电荷或者由于漏电流引起cell阈值电压偏移所导致,详细解释请见下面Data Retention部分的介绍。
误码率的测试方法
误码率通常用原始误码率RBER(Raw Bit Error Rate)和不可纠错误码率UBER(Uncorrectable Bit Error Rate)来表达,RBER表示在未经ECC纠正之前的误码率,可以确切反应Nand Flash的初始可靠性状况;UBER则反应在一定长度(codeword)ECC之下的误码率,可以用于评估一定条件下需要使用的ECC强度,UBER的计算公式如下:
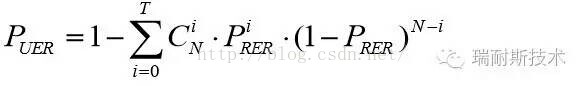
1、 写擦操作产生的误码可以通过RBER和UBER来测试,可以对NandFlash按“擦除>写入>对比”的顺序进行测试,通过原始误码率的变化可以判定Nand Flash真实的耐久度。
原始误码率(RBER)和不可纠错误码率(UBER)的具体测试如下:
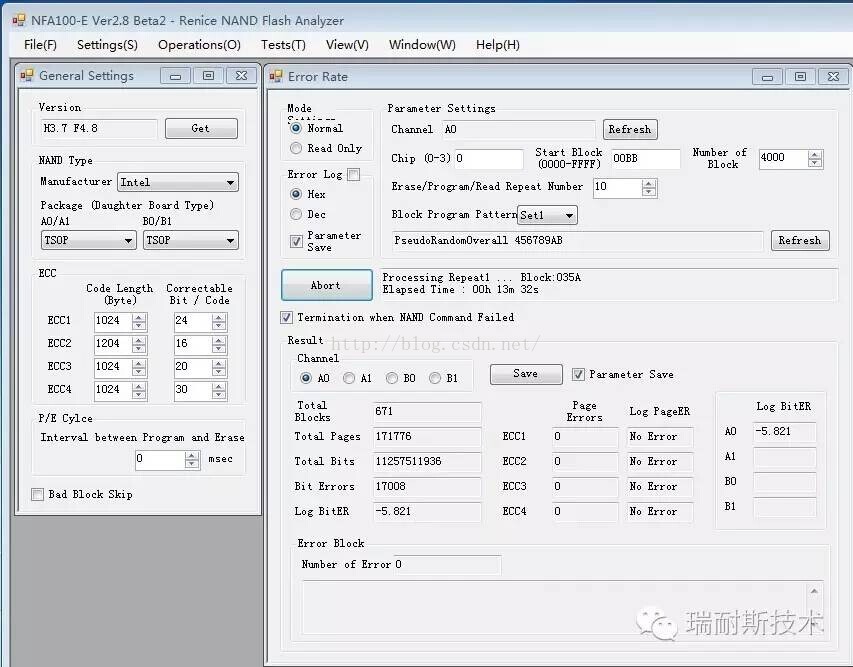
NFA100-E可以通过简单的设定(如设定4组不同codeword 长度的ECC做参考)来获取RBER和UBER的数据。
下图测试结果意思为:该Nand Flash(MLC)的原始误码率为:10^(-5.821),不可纠错的误码率为0(原因是做的P/E cycle太少),SSD一般会要求UBER要达到10^(-15),是否可以达到或者超过10^(-15)主要取决于ECC的能力和算法。
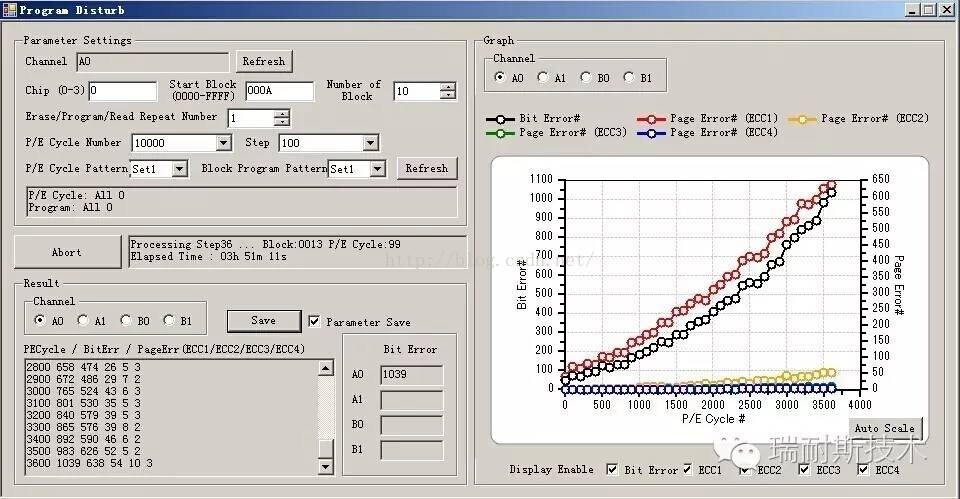
2、 编程干扰(ProgramDisturb)
编程干扰一般是由于:Vpass过高、Vpass过低、电容性耦合失效以及过量写入导致。
假设,将“11”编程为“10”,对Lower page进行编程需要16V电压,最终,相邻的Cell受到的可能是19V的影响,为什么会出现这种情况呢?
Program实际上是采用增量脉冲编程(Incremental step pulse programming,以下简称ISPP)方式,因为每个Cell的状态不同,对于状态非常良好的cell来说,也许只要一次加压就可以完成Program过程,但对于状态不好的cell来说,可能需要增加电压来完成Program,增加的电压值将被分解为多个子步骤,每次增加一点点电压,然后用Vread判定是否达到目标电压,例如,Vread 为20V,那么对“10”的upper page施压的电压最高不能超过19V(Vread>Vth),从正常需要的16V到19V假设每个step增加200mV,那么需要15次才能完成Program。如果以最坏的情况来看,这样的结果事实上是导致临近的cell受到19V影响,数据更容易出现错误,一些“坏”的cell会将邻居也带“坏”。
测试Program Disturb的方法就很简单了,只需要对指定Block进行基本的常规的Erase、Program和Read操作,NFA100-E就可以迅速得出结论。
3、 数据保持错误(DataRetention)
Data Retention是有两种原因造成:
1. Data Retention的错误根源是FG的经时击穿TDDB(timedependent dielectric breakdown )导致了低场漏电流变的越来越大,漏电流的变大又导致Cell保存阈值电压转移能力的变弱,从而产生Data Retention的出错。
2. Data Retention的另一种原因就是前文所述的,Erase和Program的操作也会导致氧化层收集电荷,这样会影响到cell的阈值电压,当电荷脱井时,阈值漂移,Bit发生反转。
原理上讲,如果Cell的电压完全失去(低于0V),那么DataRetention错误最终结果是这个cell数据会变成“11”,既:“10”,“01”,“00”最终变成“11”。
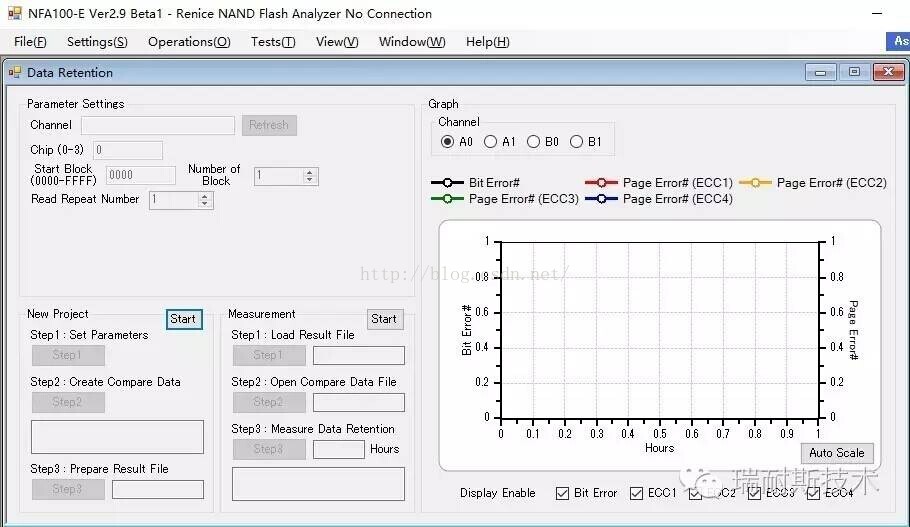
Data Retention的测试方法可以参考JEDEC标准,使用NFA100-E可以提供两种测试方法,1、直接使用DataRetention界面按步骤进行测试(如下图示);2、用Error Rate的测试方法,在室温下用NFA100-E对Nand Flash进行1000次P/E,然后写入一个伪随机数,将Nand Flash放入120°C温箱,34分13秒后取出,用NFA100-E Read Only模式验证Error Rate,依次做此类循环,没有Error Rate发生就表示数据可以保存一年。
4、 读取干扰(ReadDisturb)
读取操作同样会导致相邻cell的错误,原因是读取操作是通过对选定的page施压0V电压,而对非选定page施压5V电压,通过cell的源极到漏极之间是否有电流导通来判断cell中是“0”还是“1”,如果有电流导通说明cell阈值电压低于所施加电压,数据为“1”,如果没有电流导通,说明cell阈值电压高于所施加电压,数据为“0”。
因此,读取的操作会造成未被选取的cell形成某种意义上的编程操作,导致其阈值电压向增高,从而导致bit翻转。
温度对误码率的影响
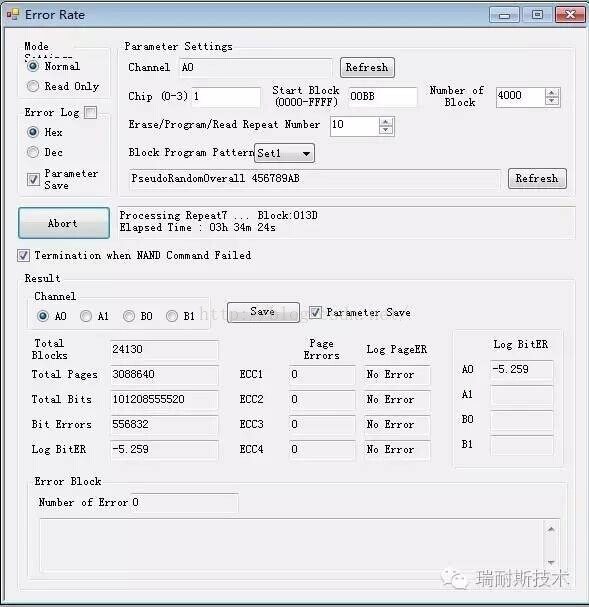
高温和低温对误码率的影响很大,根据本人测试,低温对误码率的影响要高于高温,下图为常温下(20°C)RBER为10^(-5.902)的MLC在-45°C条件的误码率为10^(-5.259):
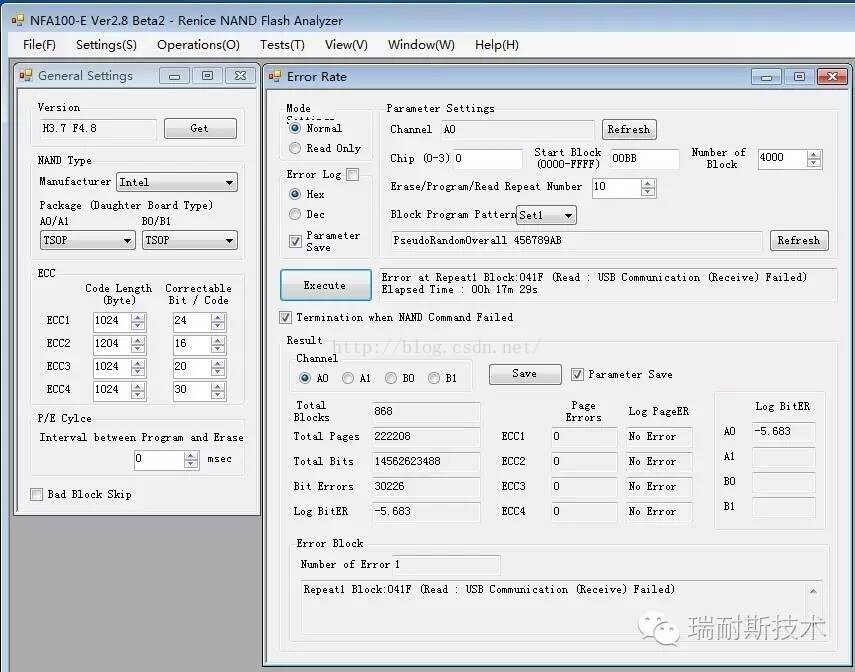
同样的MLC颗粒,在+120°C条件的误码率为10^(-5.683):
想了解更多闪存知识或闪存测试仪NFA100-E,请联系may@renice-tech.com.
这篇关于闪存误码根源分析及测试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




