本文主要是介绍深度学习论文: Rethinking “Batch” in BatchNorm及其PyTorch实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习论文: Rethinking “Batch” in BatchNorm及其PyTorch实现
Rethinking “Batch” in BatchNorm
PDF: https://arxiv.org/pdf/2105.07576.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
BatchNorm是现代卷积神经网络中的关键构建模块。它与大多数深度学习操作不同的独特属性是它对“批次”而不是单个样本进行操作,这导致了许多隐藏的问题,可能以微妙的方式对模型的性能产生负面影响。本文对视觉识别任务中的这些问题进行了全面的审查,并展示了解决这些问题的关键是重新思考BatchNorm中“批次”概念中的不同选择。通过介绍这些问题及其缓解方法,我们希望这篇综述能帮助研究人员更有效地使用BatchNorm。
2 A Review of BatchNorm
BatchNorm的计算过程如下:

其中训练过程中的 µ µ µ and σ 2 σ^{2} σ2 (使用来自同一batch数据)的计算如下:

但是,推理时 µ µ µ and σ 2 σ^{2} σ2 来自全部训练集的统计。
关于“批次”的选择有很多,即我们计算 µ µ µ and σ 2 σ^{2} σ2的数据是什么。批次的大小、批次的数据来源或计算统计量的算法在不同的情况下可能会有所不同,这会导致不一致性,最终影响模型的泛化能力。
3 Whole Population as a Batch
指数移动平均(EMA)可用于高效计算总体统计量。这种方法如今已成为深度学习库中的标准。

尽管广泛使用,但是EMA指数平均法可能会导致对总体统计数据进行次优估计,原因如下:
- 当λ较大时,统计量的收敛速度较慢。由于每次更新迭代只对指数平均法(EMA)贡献了一个较小的部分(1-λ),需要大量的更新才能使EMA收敛到稳定的估计值。随着模型的更新,情况会变得更糟,因为EMA主要受过时的过去输入特征的影响。
- 当较小时,EMA统计量主要由较少数量的最近小批量数据主导,无法代表整个总体。
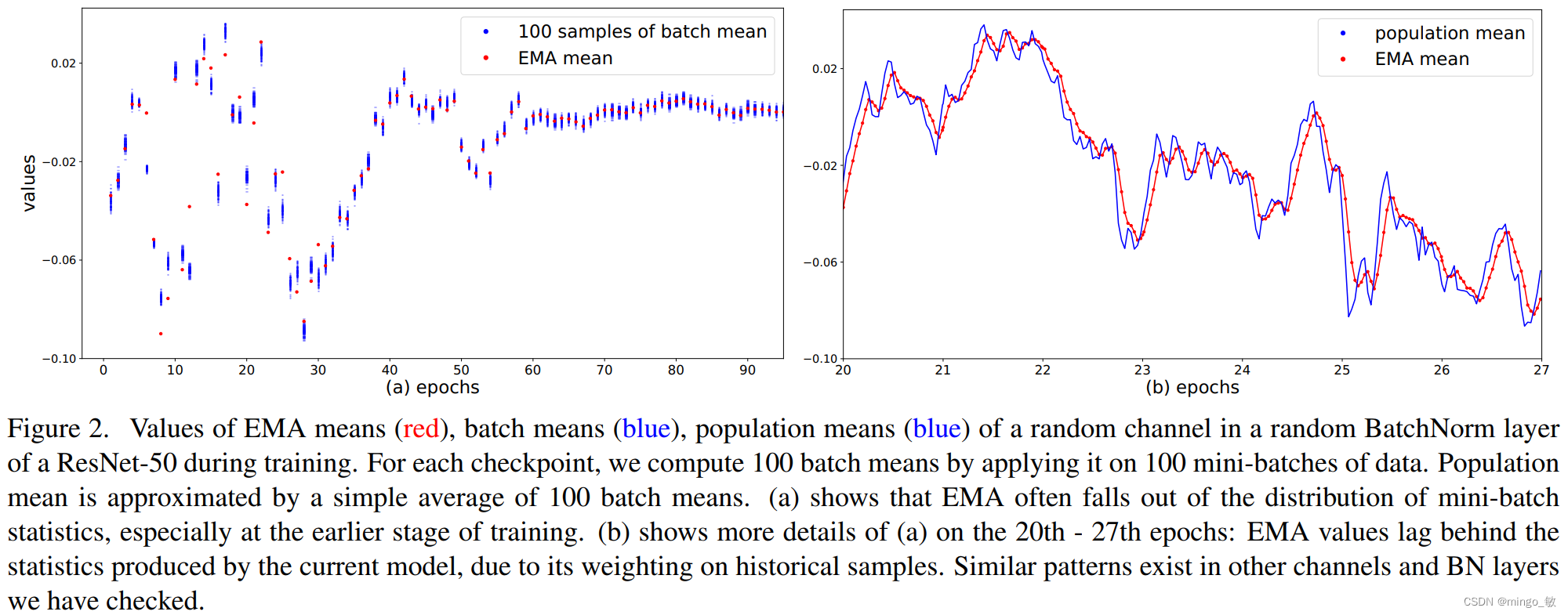
研究表明,在训练的早期阶段,指数平均法(EMA)无法准确表示小批量统计或总体统计, 因此推荐使用PreciseBN。
PreciseBN
为了得到整个训练集更加精确的统计量,PreciseBN采用了两点小技巧:
1.将相同模型用于多个mini-batches来收集batch统计量
2.将多个batch收集的统计量聚合成一个population统计量
比如有N个样本需要通过数量为的Bmini-batch进行PreciseBN统计量计算,那么需要计算 N/B 次,统计量聚合公式为:
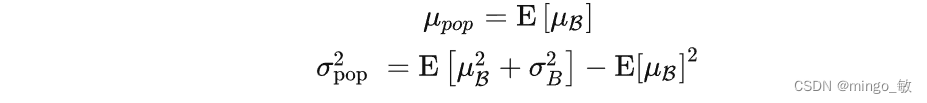
相比于EMA,PreciseBN有两点重要的属性:
1.PreciseBN的统计量是通过相同模型计算得到的,而EMA是通过多个历史模型计算得到的。
2.PreciseBN的所有样本的权重是相同的,而EMA不同样本的权重是不同的。
PreciseBN代码:
import torch
import torch.nn as nnclass PreciseBN(nn.Module):def __init__(self, num_features, eps=1e-5, momentum=0.1):super(PreciseBatchNorm, self).__init__()self.num_features = num_featuresself.eps = epsself.momentum = momentumself.register_buffer('running_mean', torch.zeros(num_features))self.register_buffer('running_var', torch.ones(num_features))def forward(self, x):if self.training:mean = x.mean(dim=0)var = x.var(dim=0, unbiased=False)self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * meanself.running_var = (1 - self.momentum) * self.running_var + self.momentum * varelse:mean = self.running_meanvar = self.running_varx = (x - mean) / (torch.sqrt(var + self.eps))return x
4 Batch in Training and Testing
BN在训练和测试中行为不一致:训练时,BN的统计量来自mini-batch;测试时,BN的统计量来自population。这部分主要探讨了BN行为不一致对模型性能的影响,并且提出消除不一致的方法提升模型性能。
4-1 Effect of Normalization Batch Size
normalization batch size 对 training noise 和 train-test inconsistency 有着直接影响;使用更大的batch,mini-batch统计量越接近population统计量,从而降低training noise和train-test inconsistency。

Training noise: 当normalization batch size非常小时,单个样本会受到同一个min-batch其他样本的严重影响,导致训练精度较差,优化困难。
Generalization gap: 随着normalization batch size的减少,mini-batch的验证集和训练集的之间的泛化误差单调递减,这可能是由于training noise和train-test inconsistency的正则化减弱。
Train-test inconsistency: 在小batch下,mini-batch统计量和population统计量的不一致是影响性能的主要因素。当normalization batch size增大时,细微的不一致可以提供正则化效果减少验证误差。在mini-batch为32~128之间时,正则化达到平衡,模型性能最优。
4-2 Use Mini-batch in Inference

作者在Mask R-CNN上进行实验,mini-batch的结果超过了population的结果,证明了在推理中使用mini-batch可以有效的缓解训练测试不一致。
4-3 Use Population Batch in Training
为了在训练阶段使用population统计量,作者采用FrozenBN的方法,FrozenBN使用population统计量。具体地,作者先选择第80个epoch模型,然后将所有BN替换成FrozenBN,然后训练20个epoch。

FrozenBN可以有效缓解训练测试不一致,即使在小normalization batch size,也能达到比较好的性能。但是随着normalization batch size增大,作者提出的两种缓解不一致的方法都不如常规BN的结果。
5 Batch from Different Domains
BN的训练过程可以看成是两个独立的阶段:1)是通过SGD学习features,2)由这些features获得population统计量。两个阶段分别称为SGD training和population statistics training。
由于BN多了一个population统计阶段,导致训练和测试之间的domain shift。当数据来自多个doman时,SGD training、population statistics training和testing三个步骤的domain gap都会对泛化性造成影响。
5-1 Domain to Compute Population Statistics

实验发现:当存在显著的domain shift时,模型使用target domain的population统计量会得到更好的结果,可以部分缓解训练测试的不一致
5-2 BatchNorm in Multi-Domain Training

实验表明,SGD training、population statistics training和testing保持一致是非常重要的,并且全部使用domain-specific能取得最好的效果。使用GN效果更好。
6 Information Leakage within a Batch
BN在使用中还存在一种information leakage现象,因为BN是对mini-batch的样本计算统计量的,导致在样本进行独立预测时,会利用mini-batch内其他样本的统计信息。
6-1 Exploit Patterns in Mini-batches

作者实验发现,当使用random采样的mini-batch统计量时,验证误差会增加,当使用population统计量时,验证误差会随着epoch的增加逐渐增大,验证了BN信息泄露问题的存在。

为了处理信息泄露问题,之前常见的作法是使用SyncBN,来弱化mini-batch内样本之间的相关性。另一种解决方法是在进入head之前在GPU之间随机打乱RoI features,这给每个GPU分配了一个随机的样本子集来进行归一化,同时也削弱了min-batch样本之间的相关性。
6-2 Cheating in Contrastive Learning
在对比学习和度量学习时,训练目标通常是在mini-batch下进行比较的,这种情况下BN也会造成信息泄露,导致模型在训练期间作弊,之前的研究提出了很多不同方法来针对性解决对比学习和度量学习的信息泄露问题。
比如有n个样本,对比学习产生2n个样本,两两一对,对其中一对进行对比学习时,因为mini-batch统计量是共享的,导致n次对比学习会互相引入其他样本的信息,n对就会有n次信息泄露。
这篇关于深度学习论文: Rethinking “Batch” in BatchNorm及其PyTorch实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






