本文主要是介绍基于match_phrase搜索的分词优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ES 的match_phrase 搜索需要完整匹配输入的内容,比如我们搜索 ‘中国人民’ ,要保证的是doc中必须有 ‘中国人民’ 的内容出现。再比如我们搜索 ‘国人民’ 时,结果集中的 doc 中就要有 ‘国人民’ 的内容。一般在使用match 或 term 搜索的时候会引入词库,比如 ik 、 jieba 都利用词库来分词,之后按照分词粒度搜索。
然而match_phrase 的搜索背景下,搜索的内容有可能不是一段被完整分词的内容比如上面的例子 ‘国人民’。所以无法利用分词召回内容。取而代之的是使用 standard 或 ngram-1 先对 doc 进行最细粒度分词,搜索的时候也是按照最细粒度的单字进行匹配搜索。
下面以入库文档内容:'应付项目的增加' 为例
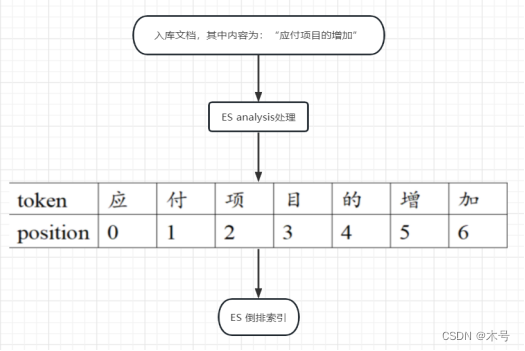
执行查询:
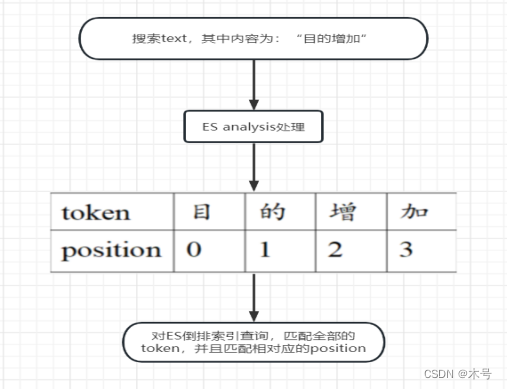
由于搜索text中的四个token 以及它们之间的相对位置和document中一样,所以能够搜索到入库的document。
这样做的原因是在短语搜索时,由于无法预判用于执行搜索的query文本,所以为了支持短语搜索,现有的技术将会在索引入库文档时,将文档中的每一个字当成一个独立的term,之后再存储到倒排索引中。而在搜索的时候,使用相同的逻辑将query文本的每一个字当成一个独立的term,然后从库中找同时包含所有query term的文档,接着在初步筛出来的文档中找出满足在文档中出现的顺序和query中的一致的文档作为最后结果。
当我们输入的搜索内容较多的时候,需要处理的单字也是成线性增长,性能也会有显著的下降;对此提出使用新的分词策略,修正了ik 、jieba等主流的分词器的分词缺点;
以下是新分词器的分词原理:主要特征是在index时将文本进行穷举式分词,也就是首先对于单个字的处理成一个term,之后处理多字词,并且这些多字词使用的position为第一个字(或最后一个字,通过参数控制)对应的term的position,然后将这些分词的结果全部放到倒排索引中,供后续query查找。在search时将搜索内容按照同样的position处理逻辑处理为一段无重复的分词,使用search分词器分词好的term进行搜索。
继续使用上面的例子,但是分词使用优化后的index分词器:
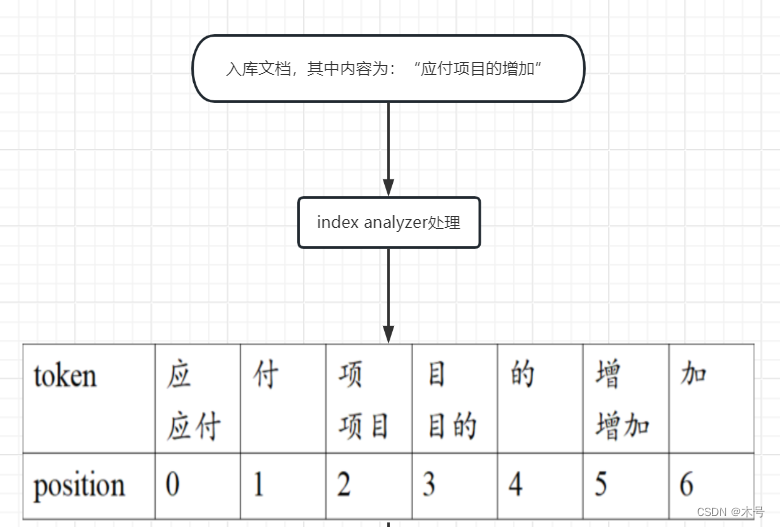
执行查询,这时使用search分词器:
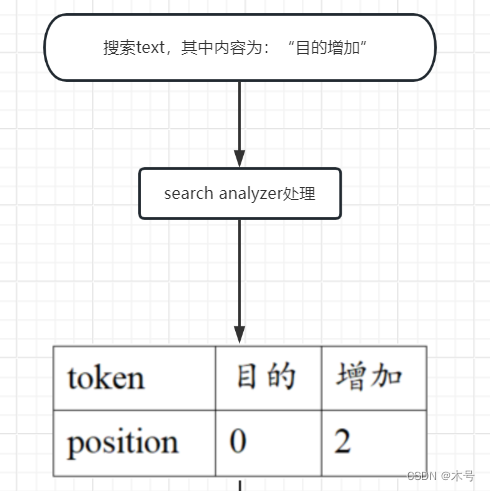
连接关系:index 分词器 和 search 分词器是ES内的两个分词组件,没有直接的连接关系,通过框架内的流程顺序建立关系。逻辑上的关联关系无论其分词粒度不同,但是得到的分词term的position都是一样的。以上面为例:search text 分词结果(目的:0,增加:2) 能够匹配到index (目的:3,增加:5)。这也是search 分词器解析的短语搜索时能够匹配index 分词器分解的文档的原因。
github: GitHub - muhao1020/elasticsearch-analysis-maxword at master
这篇关于基于match_phrase搜索的分词优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

