本文主要是介绍python 爬虫爬取阿婆主的全部视频详情,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很多时候,我们在B站上喜欢一个阿婆主,我们想要把他(她)发出的所有的视频链接都获取下来时候,这时候就会很麻烦,毕竟如果视频只要一多,就会很麻烦了,很耗时间了。
这时候,使用爬虫进行爬取就是一个非常好的操作了。
下面就来介绍一下吧。
以B站上面一个我比较喜欢的电影视频阿婆主(bili_51592201250)作为例子吧。
1、首先打开B站,在搜索框中输入对应需要搜索的内容(bili_51592201250),之后点击搜索;
2、这时候能够看到如下图所示:
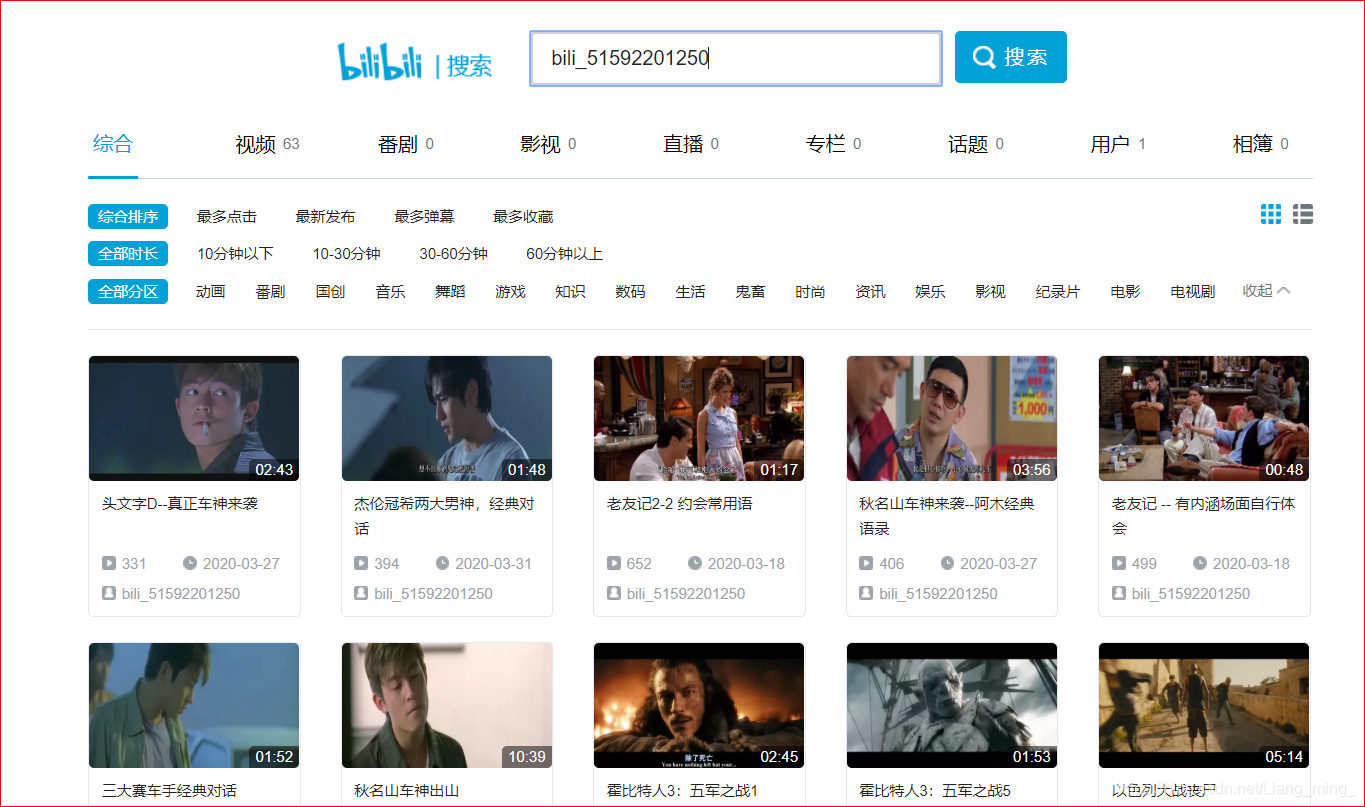
3、这个页面就是我们需要进行爬取并且处理的页面,废话不多说,直接分析页面,上代码;
4、直接从搜索结果可以看到这个阿婆主发布的视频有多少个页面,如下图所示(4页),这个页码可以选择使用代码进行获取,但是总的来说直接从页面中获取简单;
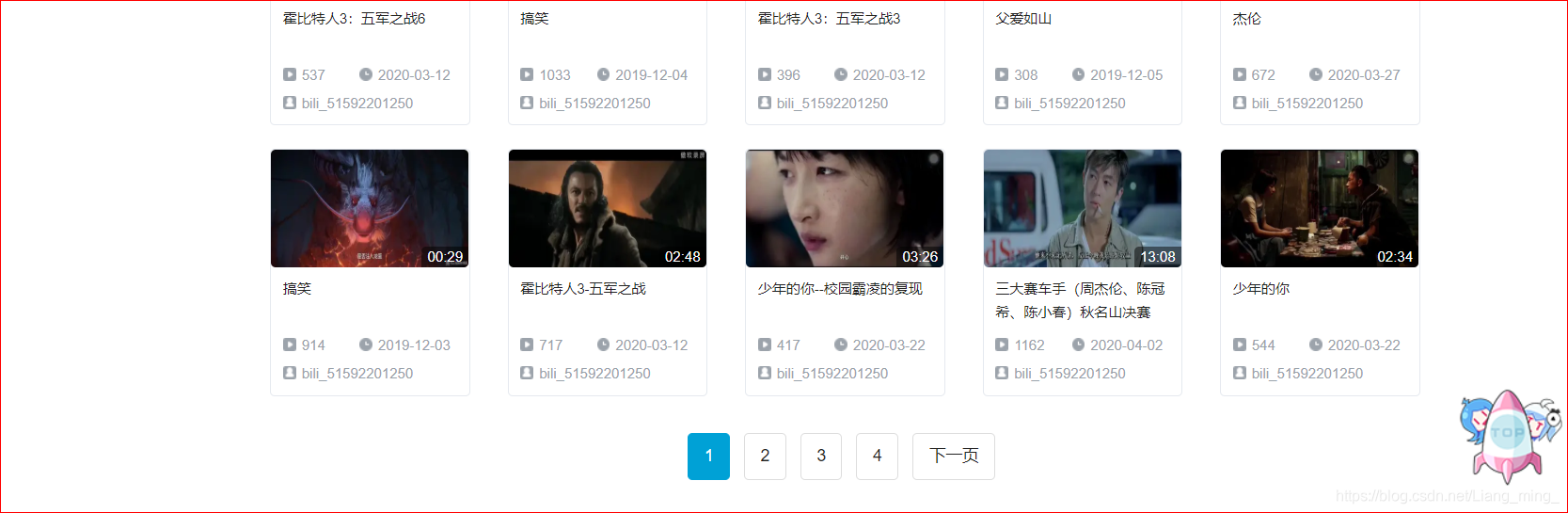
5、分析该页面对应的url链接,可以得知如下:
第一个页面url= https://search.bilibili.com/all?keyword=bili_51592201250&page=1
第二个页面url= https://search.bilibili.com/all?keyword=bili_51592201250&page=2
以此类推(在发起请求时候可以使用一个小循环进行逐个爬取)
6、发起请求前的准备
import requests,parsel,re
from fake_useragent import UserAgentua = UserAgent()
headers = {"User-Agent":ua.random} # 设置请求头
7、发起请求
try:res = requests.get(url,headers=headers) # 如果遇到反爬技术,可以考虑添加代理proxies={"https":"124.90.51.71:8888"}if res.status_code == 200:html = parsel.Selector(res.text)urls = html.xpath('//ul[@class="video-list clearfix"]/li[@class="video-item matrix"]/a/@href').extract() # 每个视频对应的url链接titles = html.xpath('//ul[@class="video-list clearfix"]/li[@class="video-item matrix"]/a/@title').extract() # 每个视频对应的标题times = html.xpath('//ul[@class="video-list clearfix"]/li[@class="video-item matrix"]/a/div/span[1]/text()').extract() # 每个视频对应的时间长度plays = html.xpath('//span[@title="观看"]/text()').extract() # 每个视频对应的播放量except Exception as e:# 如果上面的请求出现问题,那么一般就是反爬机制的作用,可以考虑在这里面添加代理进行爬取# 或者也可以寻找其他的接口,获取up主的详情信息,记得B站有提供一个接口的print("Fail:",e)pass
代码量并不多,直接就可以获取到了对应的阿婆主发的所有的视频链接以及视频对应的其他一些信息,是不是非常的简单,快去尝试一下吧。
这篇关于python 爬虫爬取阿婆主的全部视频详情的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




