本文主要是介绍跑通Faster-RCNN Pytorch-1.0以及如何训练自己的数据集(详细到发抖),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.环境配置
1.1 安装cuda
1.2 安装cudnn
1.3 安装Pytorch
2.下载Faster-RCNN pytorch1.0并跑通VOC2007数据集
2.1下载代码
2.2 配置和需要修改的地方
2.3 训练
2.4 测试
2.5 用demo.py对图片进行检测
3.训练自己的数据集
3.1 制作数据集
3.2 训练
3.3 测试
3.4 跑demo.py对图片进行检测
1.环境配置
系统:ubuntu20.04
显卡:RTX3060
cuda11.3+cudnn8.2.1 参考博客:Ubuntu16.04下安装cuda和cudnn的三种方法(亲测全部有效)_隔壁老王的博客-CSDN博客_ubuntu安装cuda
python 3.6 + Anaconda
Pytorch-1.7.1
1.1 安装cuda
官网安装包链接:https://developer.nvidia.com/cuda-toolkit-archive 。
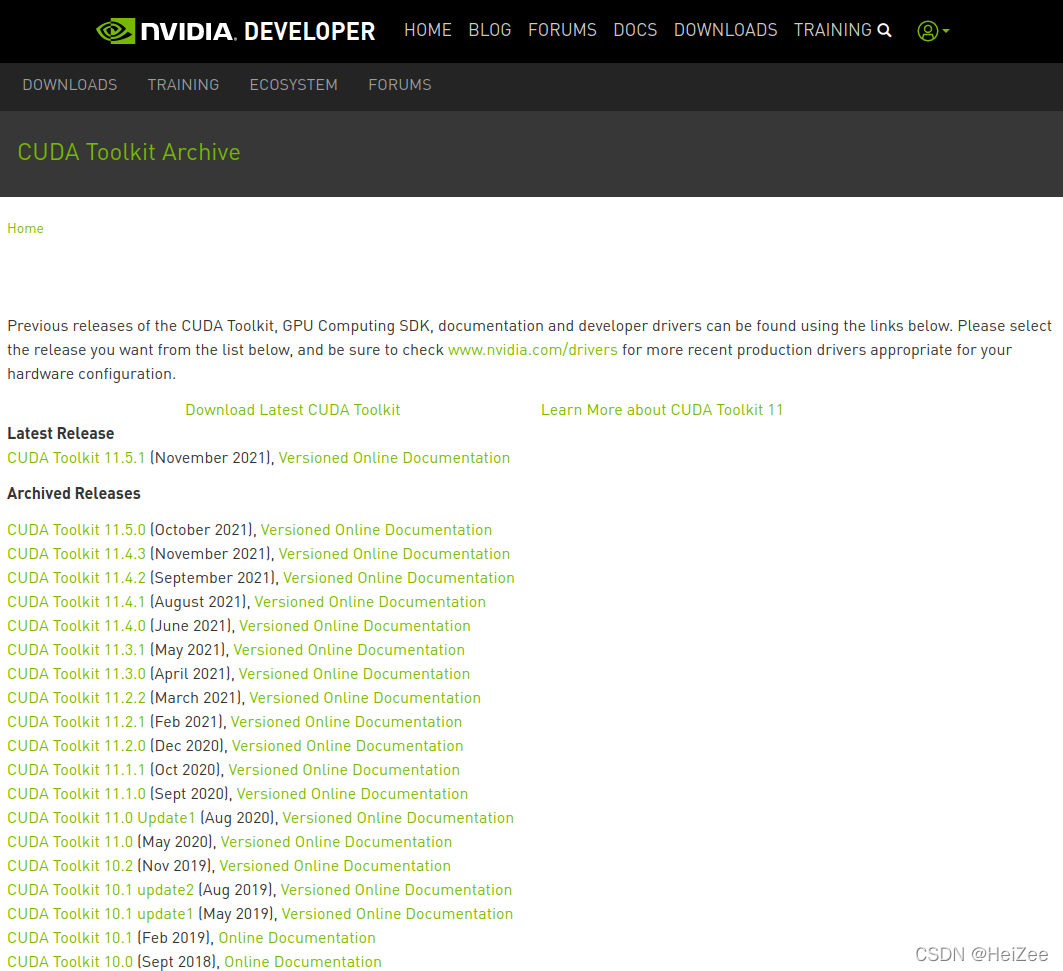
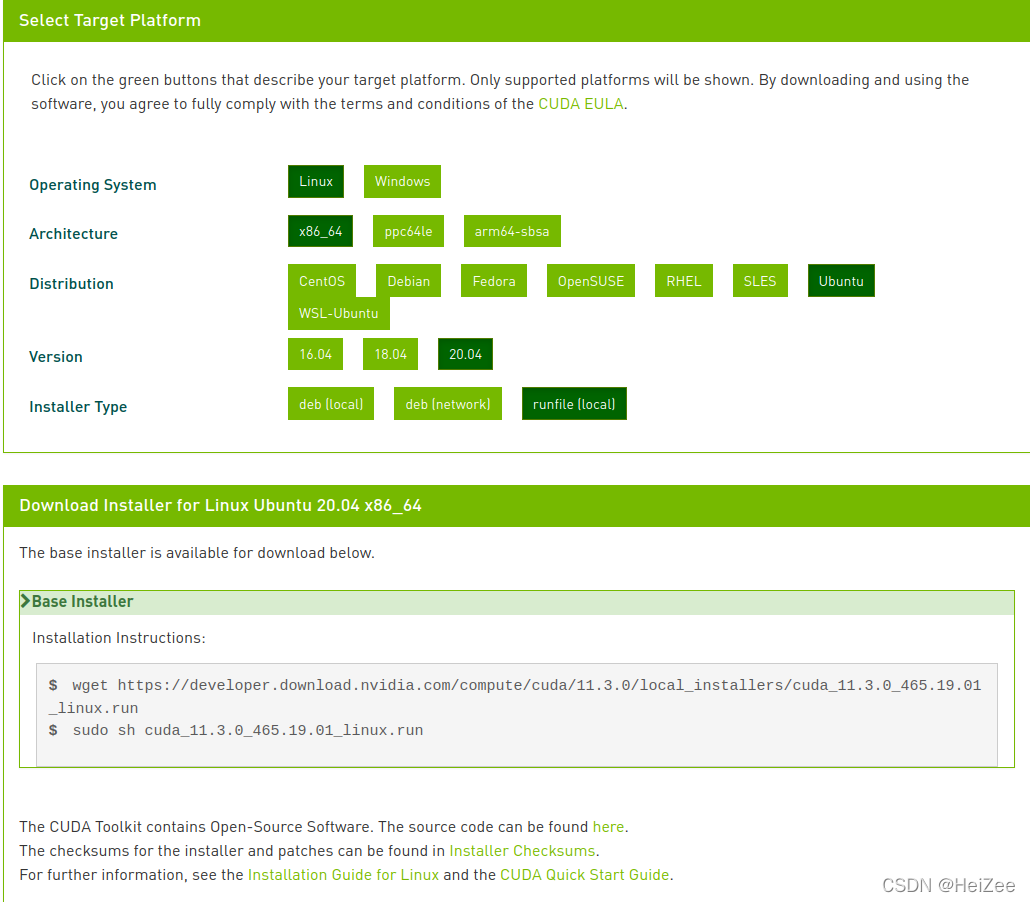
在终端输入:
wget https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.runsudo sh cuda_11.3.0_465.19.01_linux.run安装之前要先查看自己的显卡是否支持cuda10.0以上或者以下的版本,30系列的显卡貌似不支持cuda10.0以下的版本,显卡驱动可以向下兼容cuda版本,在终端输入nvidia-smi即可查看显卡驱动版本:
显卡驱动对应的cuda版本如下:
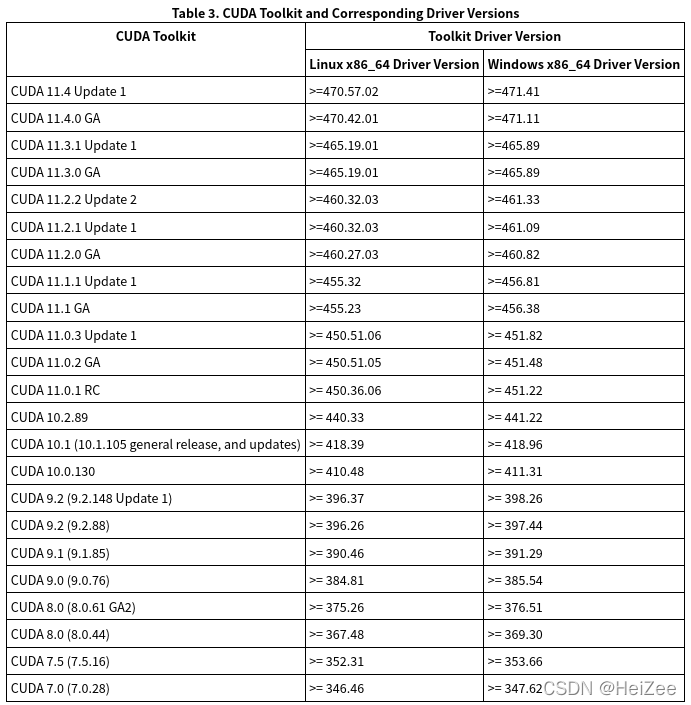
我的显卡驱动是470.86版本,所以可以使用所有版本的cuda,但是百度了以下好像cuda11.4没有对应的Pytorch版本,所有索性就下载了cuda11.3版本。
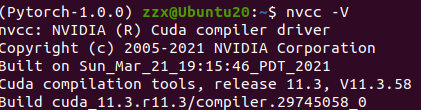
安装好了之后,在终端输入nvcc -V即可看到cuda11.3
1.2 安装cudnn
官网安装包链接:cuDNN Archive | NVIDIA Developer
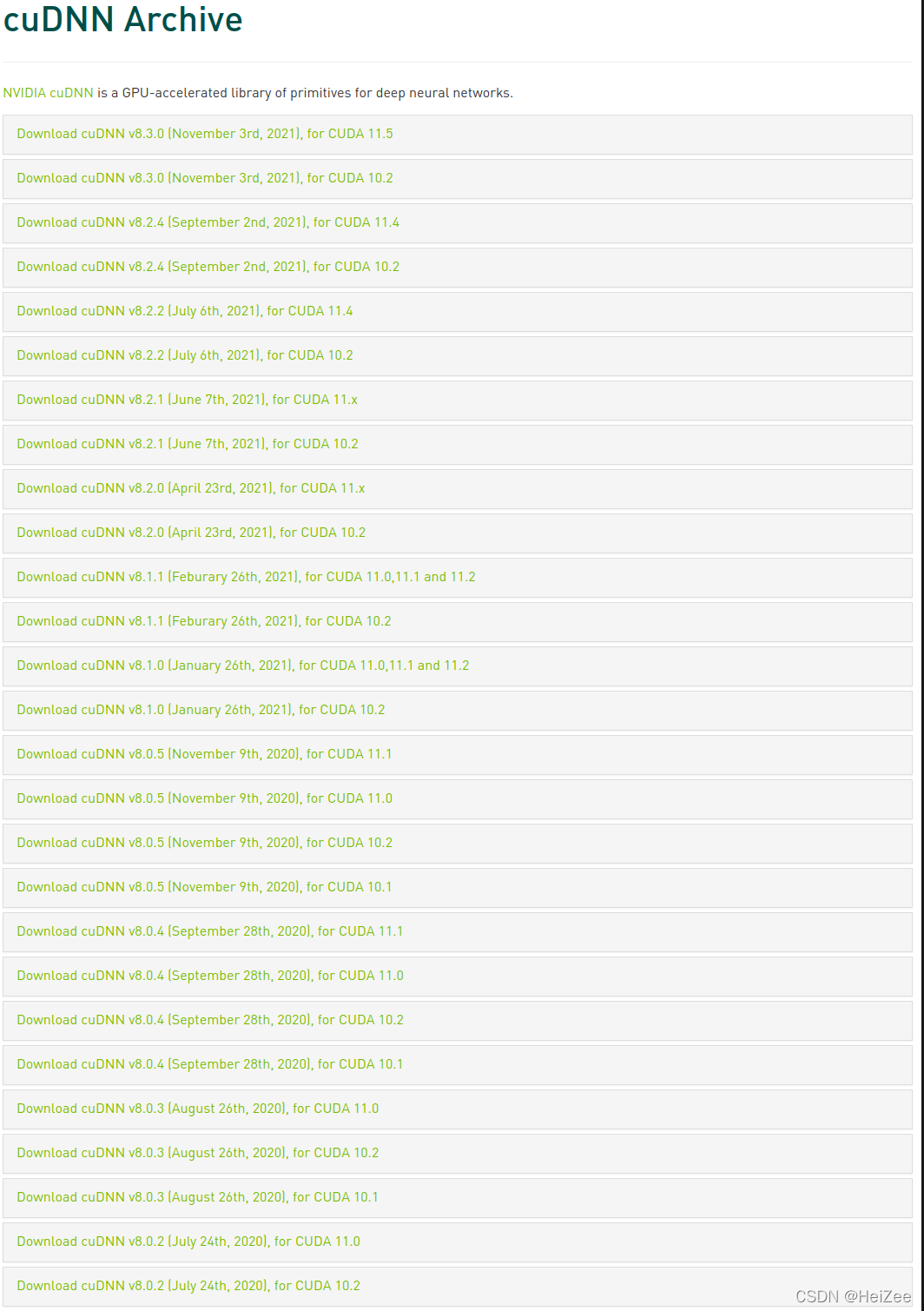
注意看cuda版本对应的cudnn版本,我下载的是cuda11.3,所以下载的是cudnn8.2.1版本,下载完之后解压下来,会看到一个cuda文件夹,在当前目录打开终端,依次输入代码:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/sudo chmod a+r /usr/local/cuda/include/cudnn.hsudo chmod a+r /usr/local/cuda/lib64/libcudnn*1.3 安装Pytorch
官网安装包链接:PyTorch

利用Anaconda进行安装Pytorch时,要添加清华镜像源,不然会下载的很慢
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/# 设置搜索时显示通道地址
conda config --set show_channel_urls yes
配置完清华镜像源之后,要修改以下Pytroch官网给的安装代码,需要将-c pytorch去掉才会优先使用清华镜像源进行下载
conda install pytorch torchvision torchaudio cudatoolkit=11.32.下载Faster-RCNN pytorch1.0并跑通VOC2007数据集
2.1下载代码
git clone https://github.com/jwyang/faster-rcnn.pytorch.git2.2 配置和需要修改的地方
建议直接去github下载压缩包然后解压下来,最近用git clone下载东西都很慢。下载好之后:
cd faster-rcnn.pytorch-pytorch-1.0 && mkdir datacd data && mkdir pretrained_model然后下载预训练模型放到/data/pretrained_model中,作者给出了两个效果比较好的特征提取网络,下载链接:VGG16:VT Server ResNet101:VT Server
之后回到根目录下载依赖的python包,注意scipy版本,不能太高,1.2.1差不多
pip install -r requirements.txt 之后
cd libpython setup.py build develop完事之后,下载VOC2007数据集
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
将这三个压缩包解压到/data中,并将/data/VOCdevkit改名为/data/VOCdevkit2007
之后需要安装CoCo API,否则运行训练代码的时候,会报错:
ImportError: cannot import name '_mask'
安装CoCo API,链接:GitHub - cocodataset/cocoapi: COCO API - Dataset @ http://cocodataset.org/ 建议直接下载压缩包,当然也可以试试用git clone,下载完之后呢解压到/data下,并将其文件夹改名为coco,即/data/coco,之后
cd coco/PythonAPImake完事之后,data文件夹下面应该有三个文件夹

之后需要对config.py一处地方进行修改,否则会报错:
TypeError: load() missing 1 required positional argument: 'Loader'
在/lib/model/utils/config.py中的374行
yaml_cfg = edict(yaml.load(f))修改为
yaml_cfg = edict(yaml.load(f, Loader=yaml.FullLoader))2.3 训练
作者给出了训练的代码
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py \--dataset pascal_voc --net vgg16 \--bs $BATCH_SIZE --nw $WORKER_NUMBER \--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP \--cuda
| --GPU_ID | 一般是GPU 0,可以通过 |
| --dataset | 需要训练的数据集 |
| --net | 预训练的网络模型 |
| --bs | batch_size 默认是1 显存较大的话可以设置4 或者其他参数 |
| --nw | number work 显卡比较好的话可以设置4 一般的话设置 1 |
| --lr | 学习率 |
| --lr_decay_step | 学习率衰减周期,每隔 |
| --cuda | 使用cuda |
| --epochs | 训练几轮 |
| --use_tfb | 使用tensorboardX对loss进行可视化 |
我的参数设置
CUDA_VISIBLE_DEVICES=0 python trainval_net.py --dataset pascal_voc --net res101 --bs 4 --nw 4 --lr 0.001 --lr_decay_step 5 --cuda --use_tfb --epochs 20开始训练
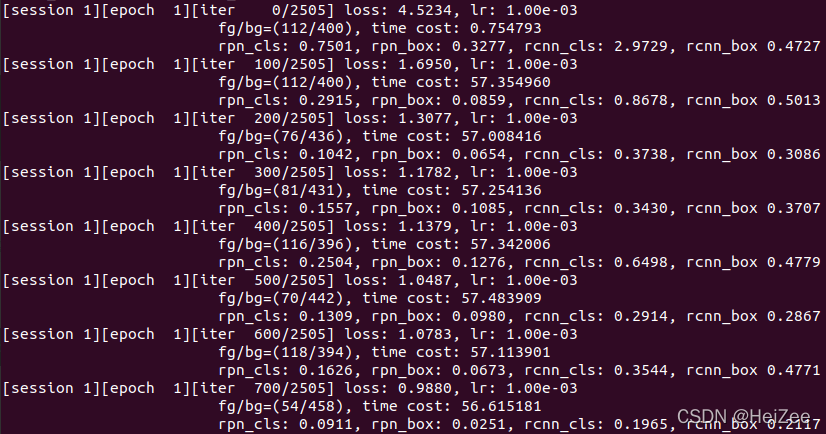
训练好之后在faster-rcnn.pytorch/models/res101/pascal_voc/里面就有很多个模型。
使用tensorboardX对loss进行可视化,在faster-rcnn.pytorch下,输入
tensorboard --logdir=logs/logs_s_1/losses/ --port=8888之后就会有个网址给你
TensorBoard 2.6.0 at http://localhost:8888/ (Press CTRL+C to quit)
在网页中输入http://localhost:8888/即可看到可视化的结果
2.4 测试
作者给出了测试的代码
python test_net.py --dataset pascal_voc --net vgg16 \--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT \--cuda选用刚刚训练完的模型,选择最后一个,如果是按着本文的流程来的话,应该是

我的代码如下
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 20 --checkpoint 2504 --cuda
结果
AP for aeroplane = 0.7382
AP for bicycle = 0.7671
AP for bird = 0.7674
AP for boat = 0.6232
AP for bottle = 0.5563
AP for bus = 0.7966
AP for car = 0.8373
AP for cat = 0.8748
AP for chair = 0.5078
AP for cow = 0.8198
AP for diningtable = 0.6214
AP for dog = 0.8673
AP for horse = 0.8794
AP for motorbike = 0.7613
AP for person = 0.7881
AP for pottedplant = 0.4624
AP for sheep = 0.7477
AP for sofa = 0.7411
AP for train = 0.7439
AP for tvmonitor = 0.7553
Mean AP = 0.7198
2.5 用demo.py对图片进行检测
将需要检测的图片放到faster-rcnn.pytorch/images中,然后运行

python demo.py --dataset pascal_voc --net res101 --cfg cfgs/res101.yml --load_dir models --checksession 1 --checkepoch 20 --checkpoint 2504 --image_dir images --cuda
就可以看到检测出来的图像啦

3.训练自己的数据集
3.1 制作数据集
首先把data/VOCdevkit2007/VOC2007/Annotations和/ImageSets/Main和/JPEGImages中的东西全部删掉
| Annotations | 存放数据打标签后的xml文件 |
| Main | 存放图片的名字和正负样本标签 |
| JPEGImages | 存放图片 |
在Main中有四种txt文件
| trainval | 存放全部的训练集和验证集图片的名字,不要带后缀,比如图片是0.jpg,就写0就行了 |
| train | 存放全部的训练集图片名字,占trainval的50% |
| val | 存放全部的验证集图片名字,占trainval的50% |
| test | 存放全部的测试集图片名字 |
另外还有其他的txt文件,不过也是这四种类型,比如我用的是钢材的表面残缺检测数据集,我就需要另外多弄几个txt文件,我检测的类型有三个:擦花、桔皮、碰伤,凸粉,所以我就需要分别创建出各种类别的txt文件
| cahua_trainval.txt | 存放擦花类型训练集和验证集的图片名字 |
| cahua_train.txt | 存放擦花类型的训练集图片名字 |
| cahua_val.txt | 存放擦花类型的验证集图片名字 |
| cahua_test.txt | 存放擦花类型的测试集图片名字 |
| jupi_trainval.txt | 存放桔皮类型训练集和验证集的图片名字 |
| jupi_train.txt | 存放桔皮类型的训练集图片名字 |
| jupi_val.txt | 存放桔皮类型的验证集图片名字 |
| jupi_test.txt | 存放桔皮类型的测试集图片名字 |
| pengshang_trainval.txt | 存放碰伤类型训练集和验证集的图片名字 |
| pengshang_train.txt | 存放碰伤类型的训练集图片名字 |
| pengshang_val.txt | 存放碰伤类型的验证集图片名字 |
| penghsnag_test.txt | 存放碰伤类型的测试集图片名字 |
| tufen_trainval.txt | 存放凸粉类型训练集和验证集的图片名字 |
| tufen_train.txt | 存放凸粉类型的训练集图片名字 |
| tufen_val.txt | 存放凸粉类型的验证集图片名字 |
| tufen_test.txt | 存放凸粉类型的测试集图片名字 |
这四个txt文件跟上面四个不同的是,这四个txt存放的是某一类的图片,我还有另外三个类,所以我还需要再多创建8个txt文件,但是这些txt都单独存放某一类的图片名字,而上面四个txt,即不带前缀的txt文件,就需要存放所有类的图片名字。
另外不同的是,上面存放全部图片的txt文件,不需要打上正负样本标签,就像这样:
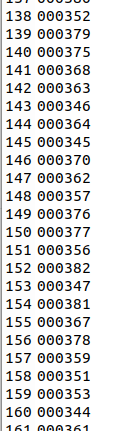
而其他类型类型的四个txt文件,则需要打上正负样本的标签,如果是擦花类型的txt文件,我就需要在除了擦花类型的图片之外的图片名字后面加上 -1 ,擦花类型的图片名字后面加上 1,就像这样:
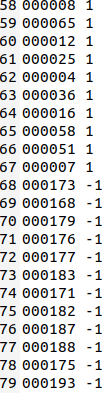
以此类推,最后文件夹里面应该有
接着,将所有的图片都放在JPEGImages文件夹里面,像这样
接着就是打标签了,用labelImage进行数据标注,安装方法参照博客Ubuntu20.04安装LabelImg工具--亲测有效_sunchanglan151的博客-CSDN博客
安装好之后,打开labelImage,标注的格式使用
![]()
之后就是快乐的打标签过程,打完标签之后,将所有标签都丢到data/VOCdevkit2007/VOC2007/Annotations文件夹里面,这样数据集就做好了。
3.2 训练
训练之前,要把之前跑VOC2007数据集产生的缓存删除,如果Ubuntu系统的内存不够,还需要把之前生成的20个模型删除掉:
删除缓存:将faster-rcnn.pytorch/data/cache文件夹里面的东西全删掉
删除模型:将faster-rcnn.pytorch/models/res101/pascal_voc文件夹里面的东西全删掉
之后还需要修改一下代码,对pascal_voc.py和demo.py进行修改
pascal_voc.py 48行,修改为'__background__'和你的类,我的修改方式如下所示
demo.py修改方式同上,之后就可以快乐的进行训练了,训练方式还是跟之前一样,我的训练方式如下,因为数据集比较少,所以修改了一些参数
CUDA_VISIBLE_DEVICES=0 python trainval_net.py --dataset pascal_voc --net res101 --bs 1 --nw 4 --lr 0.001 --lr_decay_step 3 --cuda --use_tfb --epochs 60可以适当调整bs和epochs和lr,之后就又是漫长的训练过程。
3.3 测试
还是运行之前的代码,但是要小改,就是要改那个模型,像我的话,就是
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 60 --checkpoint 654 --cuda测试结果
AP for cahua = 0.3382
AP for jupi = 0.9671
AP for pengshang = 0.2674
AP for tufen = 0.6232结果不算很好,有待提高。
3.4 跑demo.py对图片进行检测
还是一样,将需要检测的图片放到faster-rcnn.pytroch/images下,像这样
然后就跑demo.py代码
python demo.py --dataset pascal_voc --net res101 --cfg cfgs/res101.yml --load_dir models --checksession 1 --checkepoch 60 --checkpoint 654 --image_dir images --cuda然后在 faster-rcnn.pytroch/images下就可以看到检测到的结果


效果还不错,都预测对了。
至此本文就结束了,第一次写博客,写不好望指点,谢谢!
这篇关于跑通Faster-RCNN Pytorch-1.0以及如何训练自己的数据集(详细到发抖)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






