本文主要是介绍Python练习 -- 通过电影票房数据统计不同类型的票房总数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python练习 – 对单元格进行拆分并保留其他行数据
1.需求
从一份电影票房数据中按照电影类型分类,统计出不同类型的票房总数

2.数据处理
在前期的数据处理中需要将各个电影类型进行拆分,通过以下python代码实现
data = pd.read_csv('movie_metadata.csv')data_new = data.drop(['genres'], axis=1).join(data['genres'].str.split('|', expand=True).stack().reset_index(level=1, drop=True).rename('genres_new'))#代码拆分
# data_1 = data['genres'].str.split('|', expand=True) #expand表示切分的数据时分列显示
# data_1 = data_1.stack() #进行行转列
# data_1 = data_1.reset_index(level=1, drop=True).rename('genres_new')
# data_new = data.drop(['genres'], axis=1).join(data_1) #删除原列并将新列加入原表#为了呈现效果将新加入末尾的列插入到原列位置
data_lsit = data_new.columns.tolist()for name in data_lsit:if name in ['genres_new']:data_lsit.remove(name)data_lsit.insert(data_lsit.index('gross')+1,name)data_new = data_new.reindex(columns=data_lsit)data_new.head(10)
处理结果如下
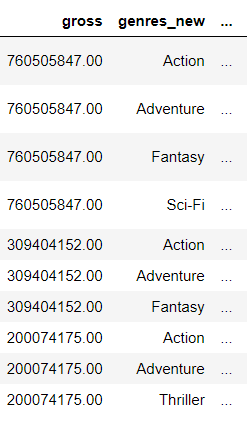
在将每个电影分类拆分后就可以通过groupby来将各个电影类型进行聚合统计
data_new.groupby(by='genres_new',as_index=False)['gross'].sum().sort_values('gross',ascending=False) # data_new.groupby(by='genres_new',as_index=False).sum()[['genres_new','gross']].sort_values('gross',ascending=False) #两种写法得到的结果是一样的#在这里为了更直观的查看结果,通过设置取消科学计数法
pd.set_option('display.float_format', lambda x: '%.2f' % x)
# pd.set_option('display.max_columns', 10000, 'display.max_rows', 10000) 网上有说这个方法也可以,但是我运行完结果还是显示科学计数法
得到的结果如下
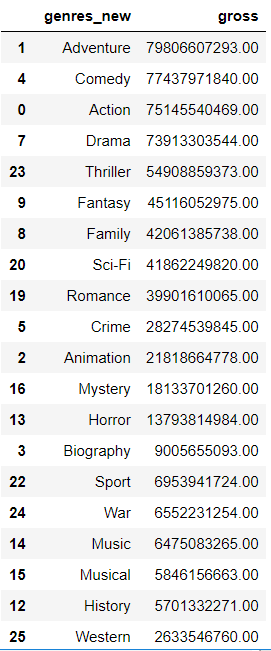
这篇关于Python练习 -- 通过电影票房数据统计不同类型的票房总数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





