本文主要是介绍使用DDPG算法实现cartpole 100万次不倒,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DDPG的全称是Deep Deterministic Policy Gradient,一种Actor Critic机器增强学习方法。
CartPole是http://gym.openai.com/envs/CartPole-v0/ 这个网站提供的一个杆子不倒的测试环境。 CartPole环境返回一个状态包括位置、加速度、杆子垂直夹角和角加速度。玩家控制左右两个方向使杆子不倒。杆子倒了或超出水平位置限制就结束一个回合。一个回合中杆不倒动作步数越多越好。
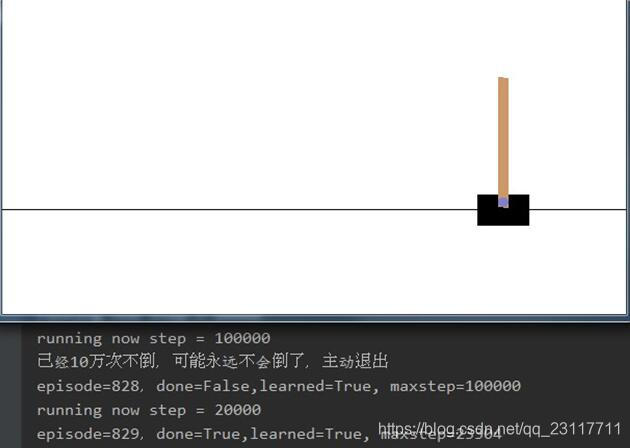
cartpole_ddpg 程序是训练出一个DDPG神经网络,用来玩CartPole-v0,使杆子不倒,步数越多越好。现在程序已可以训练出100万步不倒的网络。
源代码:https://github.com/ccjy88/cartpole_ddpg
最多测过一个回合中100万步不倒,为了节约时间程序中一个回合坚持100000步杆子不倒,程序主动退出循环。用现在程序参数1000个回合内就可以产生不倒的回合。
算法特点:
为了尽可能多的得到Critic评价的高分,就需要尽可能多的尝试各种可能。因些每一个回合尝试的步
数 MAX_EP_STEPS 设置的比较大为7500步,也可以设置为10000步、20000步。
为了尽可能多的尝试各种可能,开始运行时通过加入随机数产生动作,大约前450次是搜集数据并不学习。等采集的样本数大于MAX_EP_STEPS后才开始学习。当一个回合结束时或达到MAX_EP_STEPS步,在这个回合中记录的奖励reward计算奖励贴现值。并将这个奖励用来训来Critic的Q估计网络和Q_现实网络。大约学习330个回合后就可以产生永远不倒的情况了,前450个回合并只是收集数据没有学习。
程序说明:
cartpole_DDPG.py 是主程序。
设置一个回合最大步数MAX_EP_STEPS=7500
记录状态动作的内存也是7500行容量。
创建Brain_DDPG为agent。
在每个回合的步骤中,从agent获得动作,并加入正确分布的随机值。随机值的系数在训练后逐步减少直至为0.
从环境获得奖励和下一个状态,并存储在这个回合的记忆内存中。
每个回合结束后在回合记忆内存中计算奖励的贴现值,并增加到agent的记忆中。
agent的记忆中足够大再开始学习,对于坚持步数很多的回合全部学习,而不是随机取样学习,要全面学习。
Brain_DDPG.py为DDPG算法实现的内核。
DDPG算法公式略。
大思路为根据状态、动作和奖励,训练出一个Critic能对状态和动作正确打分Q。
有了分值Q,就可以再训练一个Actor在状态s时能做出高分动作a。
现在的程序能在学习几百个回合后,训练出一个Brain,实现一个回合10万次百万次杆子不倒。
定义变量当前状态s 下一个状态s_ 当前动作a,下一个动作a_,奖励r
封装类Brain_DDPG做为API接口。Brain_DDPG的四个子类:
Q是Critic,打分的网络,Q(s,a)打出分q
Q是打分估计网络。Q_打分的现实网络。Q和Q_结构完全相同,参数由Q逐步同步到Q_
U是Actor,是执行动作的网络。U(s)返回动作a
U是动作估计网络,U_是动作现实网络。U和U_结构完全相同,参数由U逐步同步到U_
核心算法是先由U_(s_)算出下一个动作a_
再由Q_和参数r,s_,a_算出q的现实值q_target = r + gamma * Q_(s_,a_)
由Q(s,a)算出估计值q
损失函数就是 q_target - q的差的平方再平均。
对着损失函数不断进行梯度下降学习,就可以训练出打分的Q网络了。Q参数再软同步到Q_
有了Q,那么就需要让动作网络训练成返回高分的动作。设U的参数为theta(U)。
为了求最大值需要求梯度grad(Q,theta(u))。按复合函数求导公式写成
grad_u = (grad(U * grad(Q,grad(U) ,theta(u))
对 grad_u 进行梯度下降优化,可以优化网络U的参数theta(U),使U(s)返回的动作a打分Q最高。因为tensorflow中的优化器支不持最大值,所以使用了负的学习率并求最小值。
源代码:
https://github.com/ccjy88/cartpole_ddpg
程序测试环境:
python 3.7.7
tensorflow 1.15.0rc3
无显卡无硬件加速
参考:
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master
这篇关于使用DDPG算法实现cartpole 100万次不倒的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







