本文主要是介绍火山引擎ByteHouse:如何用OLAP引擎提升数字营销效果?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
随着市场竞争的加剧,企业对数字营销投入的效果监测和优化需求日益增强,营销实时监控也成为企业提升运营效率的重要手段。在数字化营销中,数据是进行实时分析和监控的基础。企业需要建立符合自身需求的数据平台,整合和分析来自不同渠道的数据,以提供更加准确和及时的决策支持,实现更好效果。
在数据平台建设中,不少企业开始引入OLAP引擎,以提升对营销活动的数据实时查询和相应效果。OLAP引擎的特点在于能处理大规模的数据集,并快速地提供多维度的数据分析的结果。
ByteHouse则是火山引擎推出的一款基于开源ClickHouse构建的OLAP引擎,具备云原生的特点,能提供极速数据分析服务,支撑实时数据分析和海量数据离线分析,对内经过字节跳动大量业务检验,对外也已在互联网、游戏、金融、汽车等领域落地,并产生了良好业务效果。
针对企业数字营销领域的实时性需求,ByteHouse凭借其在数据处理领域的领先技术,为企业在营销实时监控领域提供了强大的支持,具体包括:
-
数据分析和预测:ByteHouse结合火山引擎VeCDP等增长营销类产品,企业可以实时分析使用行为、购买偏好和市场趋势,从而预测未来的市场需求和竞争态势。这些预测结果可以帮助企业制定更加精准的营销策略,提高客户满意度和销售额。
-
目标客户精准推送:根据数据分析结果,企业可以准确地识别目标客户群体,并实时推送个性化的广告和促销信息。通过ByteHouse、增长营销平台GMP等,企业可以快速地调整广告策略,以实现最佳的营销效果。
-
广告效果评估和优化:ByteHouse可以帮助企业实时监控广告效果,包括点击率、转化率和ROI等指标。结合火山引擎DataTester这类A/B测试产品,对比不同广告策略的表现,企业可以及时调整策略,提高广告效果和投资回报率。
在技术层面上,实时营销的难点在于要求数据实时写入、落盘延时低,对数据处理的性能也有高要求。
在数据实时写入和落盘方面,ByteHouse主要采用自研的Kafka引擎支持流式数据的实时写入、入库,保证数据传输的及时性,以支持实时的业务决策。除此之外,数据逻辑反复出现,也容易出现数据唯一性的问题。通过自研的Unique引擎实现实时的upsert语义,让数据实时写入、实时去重。这是为了确保在实时数据处理过程中,不会因为数据的重复而导致的错误。
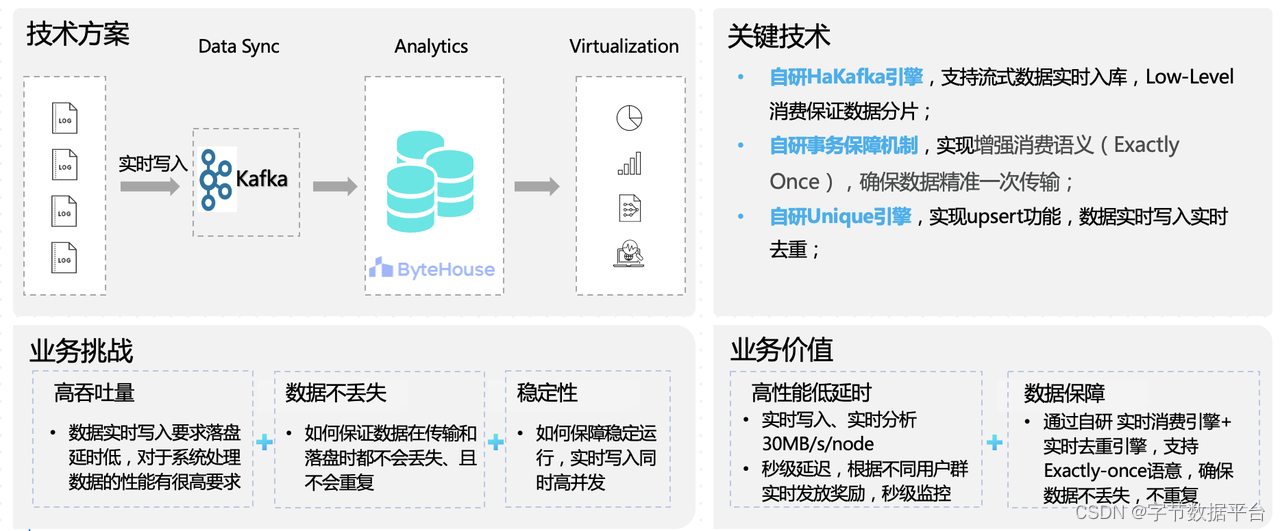
在字节跳动内部实时营销场景中,通过ByteHouse方案的优化,营销业务的实时性能和分析性能得到了显著提升,以某个节日营销为力,业务的每一个节点的实时性能达到了30MB/s/node,分析性能也在秒级以内。
数据实时分析可以帮助企业在数字营销场景中更好地了解用户需求和市场趋势,优化营销策略和广告投放,提高营销效果和ROI。火山引擎ByteHouse也将持续提升在实时数据查询、分析方向的技术及产品能力,帮助企业在数据驱动下提高品牌价值和市场竞争力。
点击跳转火山引擎ByteHouse了解更多
这篇关于火山引擎ByteHouse:如何用OLAP引擎提升数字营销效果?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




