本文主要是介绍爱奇艺|海量数据实时分析服务技术架构演进,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.现状与挑战
Druid是一个分布式的支持实时分析的数据存储系统,数据与时间强相关,已由0.10.0版本升级到0.14.2版本;
Impala是Cloudera受谷歌Dremel启发开发的实时交互SQL大数据查询工具;
Kudu是Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力;
Kylin是Apache开源的一个分布式引擎, 提供了在Hadoop之上的SQL查询接口及OLAP能力,支持超大规模数据;
Presto是一个分布式的SQL查询引擎,其设计专门用于进行高速、实时的数据分析;
- ElasticSearch是一个高可靠、可扩展、分布式的全文搜索引擎。
不同的业务场景需要不同的大数据技术架构,对于爱奇艺号而言,因单日数据量达到亿级且分固定时间选择和自由时间选择(至少查询近2年数据)查询数据的业务特点,因此采用的是Druid和ElasticSearch的组合技术架构,其中自由时间选择查询Druid,而固定时间选择查询ElasticSearch。同时,为了保证数据的高可用,Druid和ElasticSearch都有主备2份数据。
Druid本身对数据写入和查询只提供了基于JSON的API接口,学习接口的使用方法,了解各种字段含义,学习成本很高;另外,数据的安全性,在早期的Druid版本中支持较弱;再有,高qps长时间跨度的聚合查询也是一个很大的挑战。
对于ElasticSearch,因不适用于大数据量的聚合计算,要尽量避免此种应用场景,且ElasticSearch提供的RESTful API的查询接口学习成本也相对较高。另外,因为Druid集群是服务于公司全部业务的,如何做业务隔离也是一个严峻的挑战。
2.技术架构演进
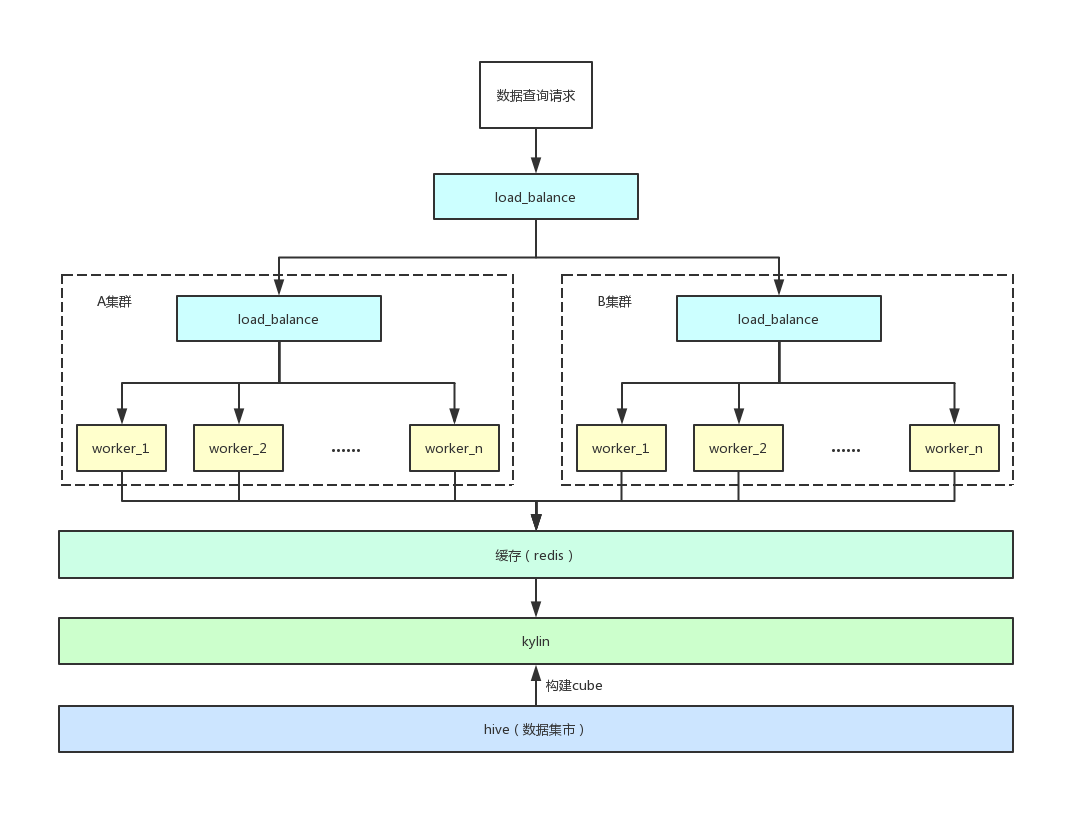
在最初的爱奇艺号数据服务中,主要采用的是Kylin,架构如下图所示:
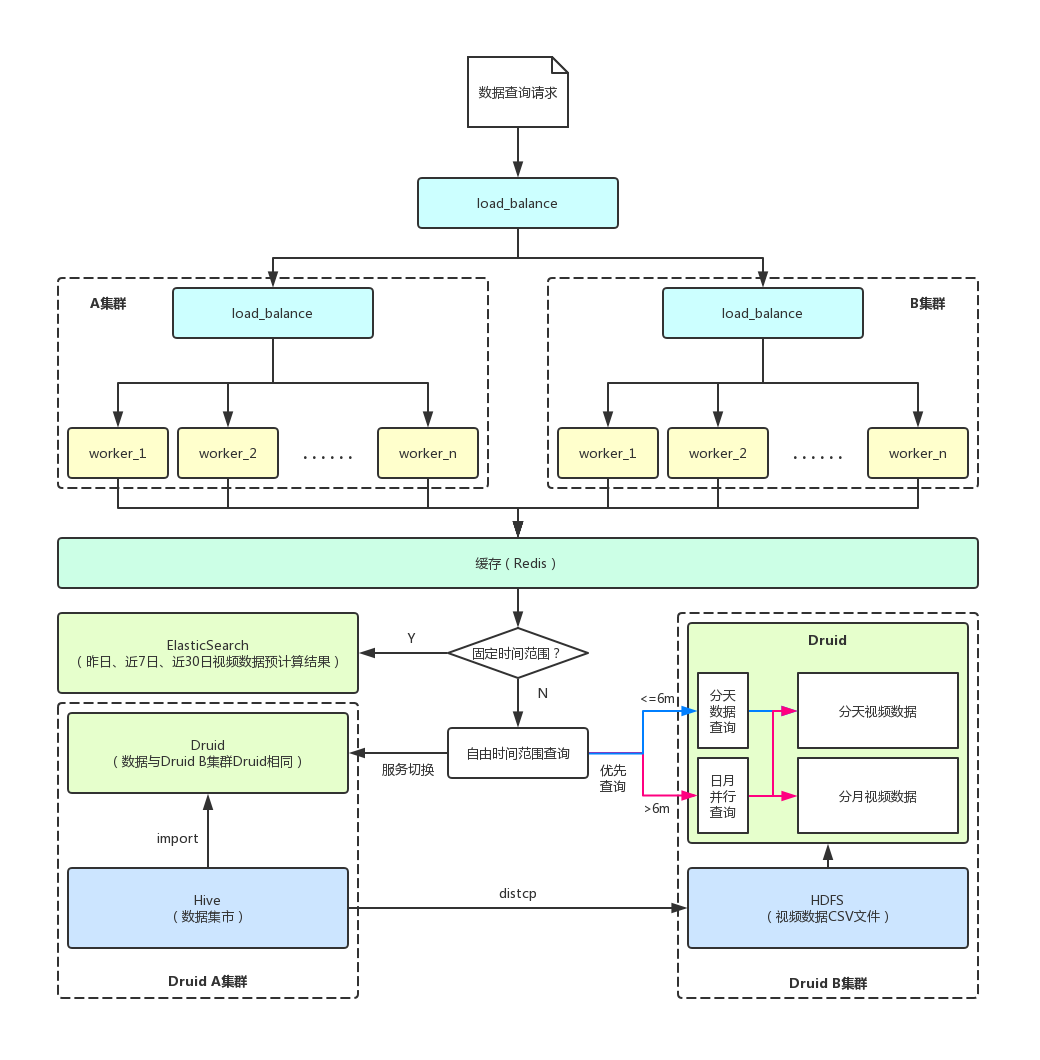
基于此,我们进行了新的技术选型,对Impala+Kudu、ElasticSearch、Druid等技术架构进行了对比。最后,因Druid具有超大数据规模、毫秒级查询时延、高并发查询、高稳定性等的特点,故爱奇艺号选择Druid平台作为底层架构。而对于固定时间选择,因其时间固定且视频量级为亿级,故采用ElasticSearch存储和查询,重新选型后的架构如下图所示。
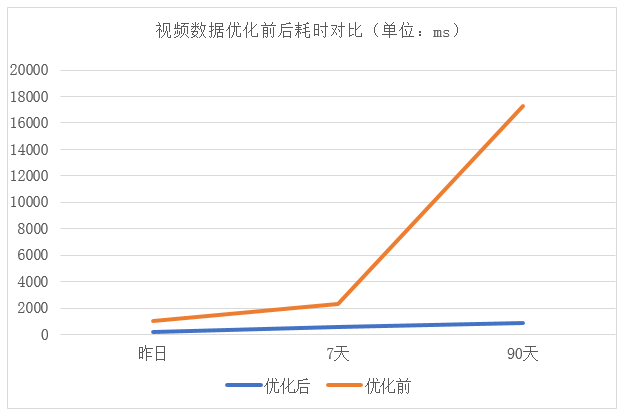
经过上述优化,一个普通的爱奇艺号用户查询数据时长由2s+缩减至150ms+,性能提升十分明显,用户反馈良好,固定时间选择具体性能对比如下图所示:
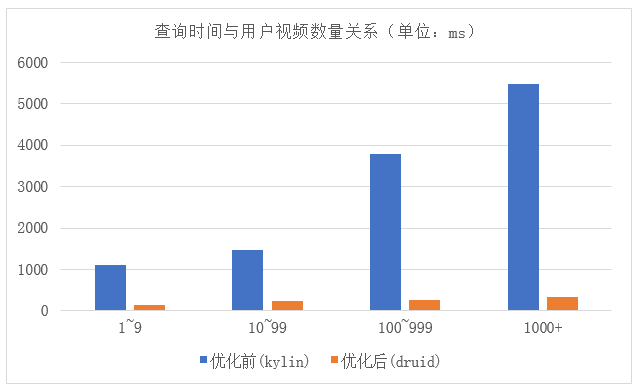
由上图可以看出,优化后自由时间选择的查询时长明显优于优化前,查询时长是数量级级别的差异。但当用户的视频量比较大时,Druid的查询性能明显下降,于是我们通过扩容集群机器等方式进一步解决用户视频量大而导致查询变慢的问题。
3.选择Druid的原因
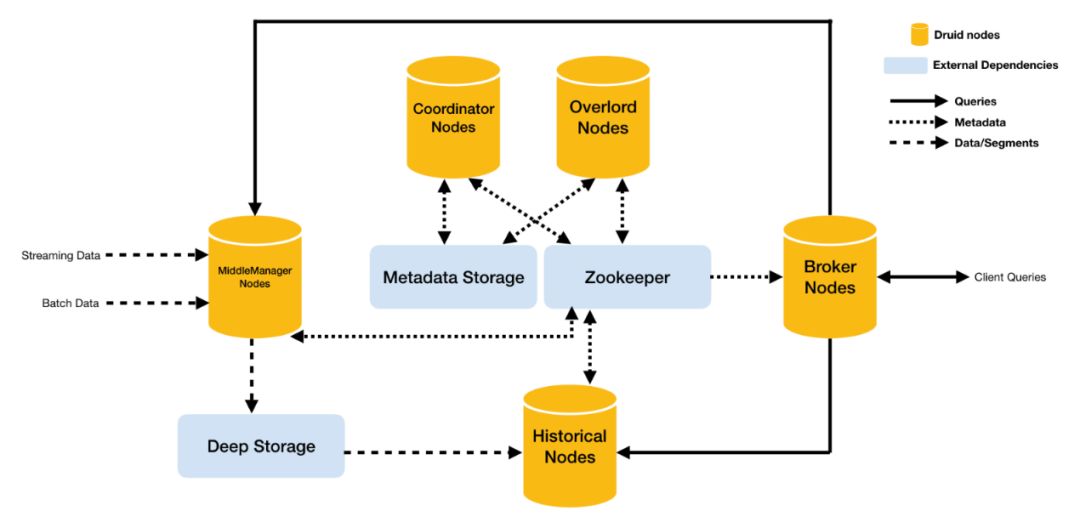
MiddleManager节点:摄入数据以及生成Segment数据文件
Historical节点:加载已生成好的数据文件,以供数据查询
Coordinator节点:负责历史节点的数据负载均衡,以及通过规则管理数据的生命周期
Overload节点:负责数据摄入的负载均衡
Broker节点:对外提供数据查询服务,并同时从MiddleManager节点和Historical节点查询数据,合并后返回给调用方
Metadata:存储Druid集群的元数据信息,比如:Segment的相关信息,一般是MySQL。
Zookeeper:为Druid集群提供一致性协调服务。
Deep Storage:存放生成的Segment数据文件,并共Historical节点下载,一般是HDFS。
Druid为何能支持如何快速的查询呢?下面为你详细介绍。
在介绍Druid快速查询原理之前,首先介绍一下Druid的数据查询过程。
查询节点接收外部Client的查询请求,并根据查询中指定的interval找出相关的Segment,然后找出包含这些Segment的实时节点和历史节点,再将请求分发给相应的实时节点和历史节点,最后将来自实时节点和历史节点的查询结果合并后返回给调用方。其中,查询节点通过Zookeeper来发现历史节点和实时节点的存活状态。
下图展示了在系统架构中查询请求数据如何流动,以及哪些节点涉入其中。
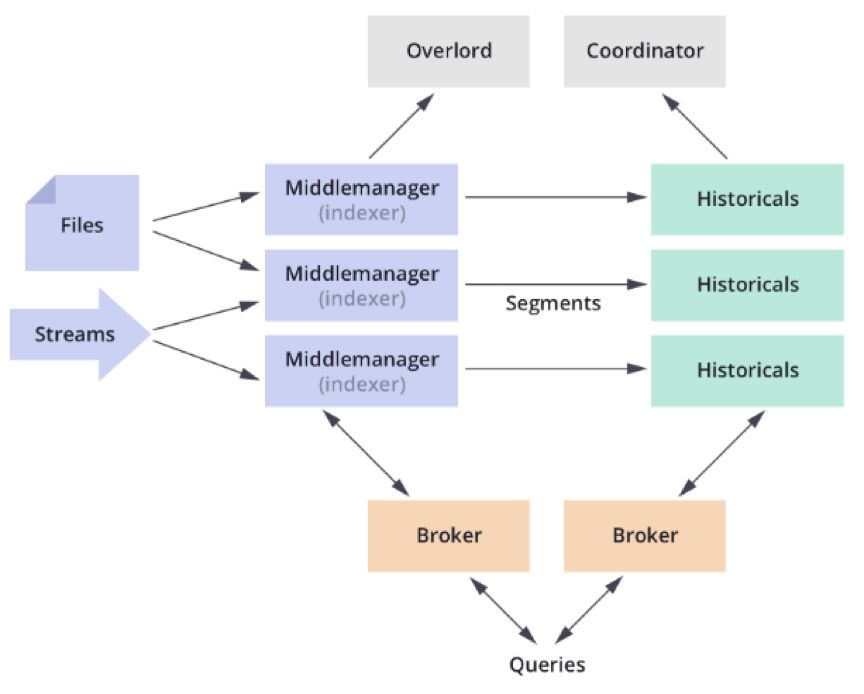
查询请求首先进入查询节点,查询节点将与已知存在的Segment进行匹配查询;
查询节点选择一组可以提供所需要的Segment的历史节点和实时节点,将查询请求分发到这些机器上;
历史节点和实时节点都会进行查询处理,然后返回结果;
查询节点将历史节点和实时节点返回的结果合并,返回给查询请求方。
内存式查询
缓存的使用
Segment特殊存储格式:列式存储、Bitmap索引、RoaringBitmap Compression
首先,Druid是一个内存式的数据库,设计初衷就是数据的查询落到内存中,如果内存足够大,可以保证所有的数据都加载到内存中;其次,如果Broker节点上已经缓存本次查询的结果(即之前查询过与本次查询完全相同的查询),那么Broker节点直接返回数据给客户端,而无需再查询各历史节点,进一步提高了查询速度;再次,基于Druid基本存储单位Segment的特殊存储格式,列式存储保证了,每次查询只查询其需要的列,而不必查询出一行中的所有数据列,Bitmap索引的使用,保证了其快速查询。
下面重点介绍一下其中Bitmap索引:
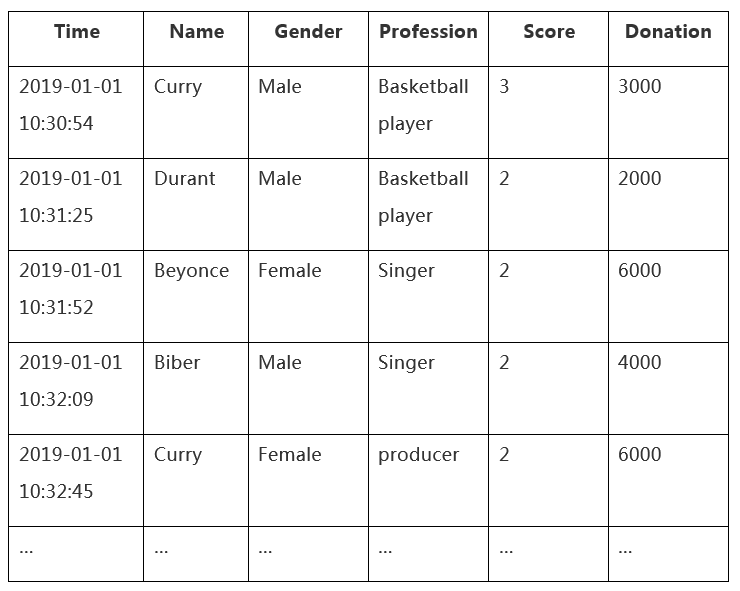
如果想查询出篮球运动员Curry的得分情况和捐款情况,如何快速查询出来呢?
首先,为每个字段中的每个值建立一个Bitmap索引,上述中共有name/gender/profession/score/donation 5个非时间字段,其中name/gender/profession属于维度列,score/donation属于度量列。对于name这个字段,因为其有4个值,Curry、Durant、Beyonce、Biber4个值,因此有4个Bitmap,每个Bitmap 0表示无,1表示有,Bitmap大小由数据条数决定,即有多少条数据,这个Bitmap的size就是多大。
Curry对应的Bitmap如下:
1 | 0 | 0 | 0 | 1 |
1 | 1 | 0 | 0 | 0 |
1 | 0 | 0 | 0 | 0 |
4.展望
Druid在0.10版本之后开始支持SQL,且随着版本的升级支持的SQL函数也越来越多,但因为Druid SQL本质上是一个语言翻译层,受限于Druid本身的查询处理能力,支持的SQL功能有限。 Druid目前并没有支持JOIN查询,所有的聚合查询都被限制在单个DataSource进行,但在实际的使用过程中,往往需要不同DataSource进行关联查询才能得到想要结果,这也是目前Druid开发团队的难题。
现在爱奇艺大部分DataSource的Segment的粒度是天或小时级的,当需要查询的时间跨度比较大时,会导致查询变慢,占用大量Historical节点资源,可以创建一个Batch任务,把几天前(或几周前)的数据按照天或月粒度Roll up重新构建Index,当查询时间跨度较大时,性能会有明显提升。
此外,因为目前爱奇艺号不同功能使用的是同一个Druid集群,只是在DataSource间做数据隔离,但是数据查询Broker之间并未做隔离,各功能之间数据查询会互相影响,也是希望解决的难题。
这篇关于爱奇艺|海量数据实时分析服务技术架构演进的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






