本文主要是介绍【tensorflow】windows下搭建tensorflow-slim网络进行目标分类(安装配置+使用教程+问题总结),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0.(可选)下载cuda,cudnn
若是想GPU跑深度学习,有英伟达显卡
关于版本的选择,要关注自身显卡驱动能支持的最高CUDA版本。
下载cuda地址:
CUDA10.1版本:https://developer.nvidia.com/cuda-10.1-download-archive-base
下载cudnn
cuDNN是一个SDK,是一个专门用于神经网络的加速包,注意,它跟我们的CUDA没有一一对应的关系,即每一个版本的CUDA可能有好几个版本的cuDNN与之对应,但一般有一个最新版本的cuDNN版本与CUDA对应更好。
这里下载的是cudnn7.6.5,官网地址:https://developer.nvidia.com/cudnn
下载完压缩包并解压:里面有3个文件夹:

复制,并粘贴到cuda的安装目录,
一般是:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
然后合并:
1.windows下安装anaconda
官网下载anaconda
https://www.anaconda.com/products/individual
一般下载的都是最新版本
安装anaconda
点击安装程序安装
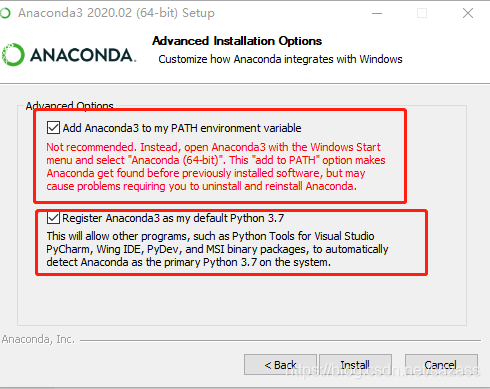
上面是添加path系统环境变量,不勾选就需要自己来手动添加。可以认真看一下英文注解;
下面勾选就是把anaconda位置作为默认的python3的地址;
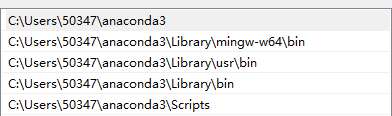
若没有勾选环境变量,手动添加可以参考以下(版本不同可能会不一样):
cmd打开终端,输入conda --version检验有没有安装成功
2.创建虚拟环境:
打开Anaconda Prompt:
更换国内源
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes下载一个python为3.7的虚拟环境:
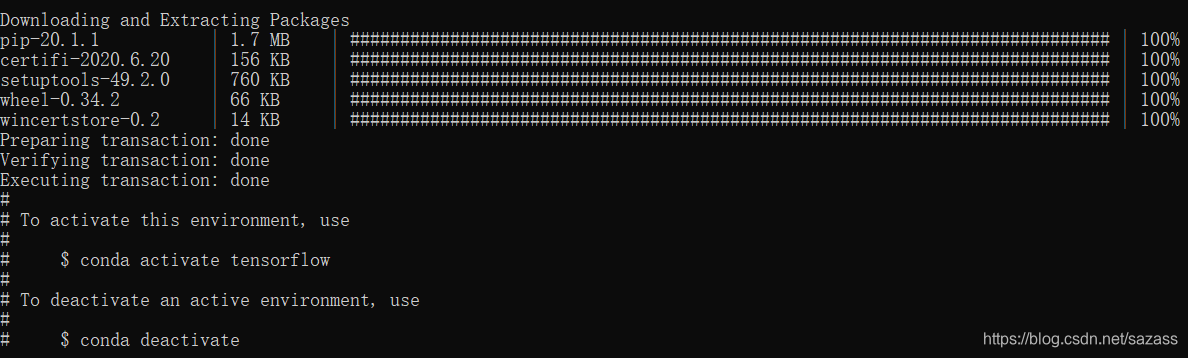
输入:conda create -n tensorflow python=3.7
等待下载完毕,(虚拟环境在anaconda目录下envs目录下)
3.下载pycharm
http://www.jetbrains.com/pycharm/download/#section=windows
4.下载tensorflow-slim模块
github地址:https://github.com/tensorflow/models
若下载速度过慢,可采用gitee的方式下载:
1.将需要的tenforflow资源fork到自己的GitHub账号上;

2.注册gitee账号,关联gitee和github账号
3.选择添加仓的方式添加GitHub的fork资源:

 然后下载tensorflow-models软件包
然后下载tensorflow-models软件包
5.使用pycharm打开tensorflow-slim
slim项目的相对位置:\research\slim

6.设置虚拟环境:
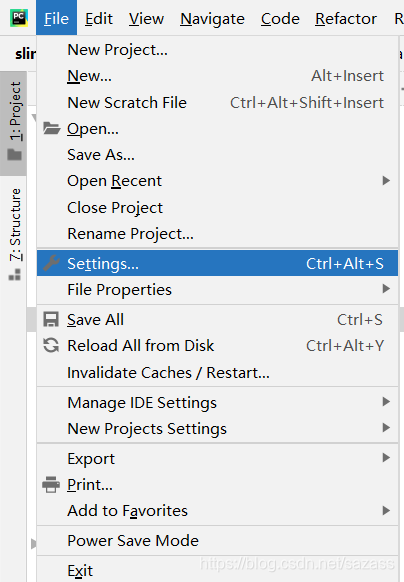
打开pycharm上File -> settings:
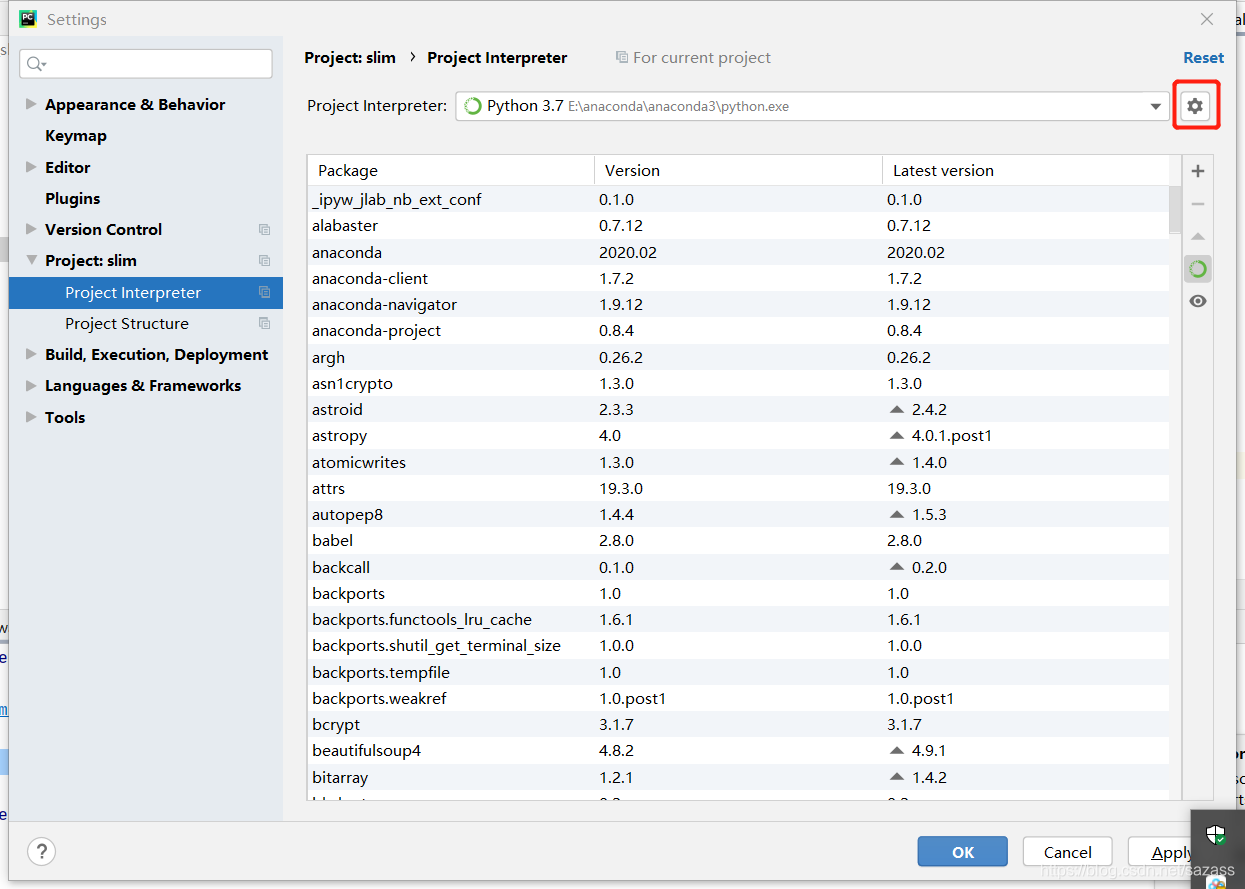
选择到Project:slim 下的 Project Interpreter,可以不采用原有的环境,选择自己创建的虚拟环境
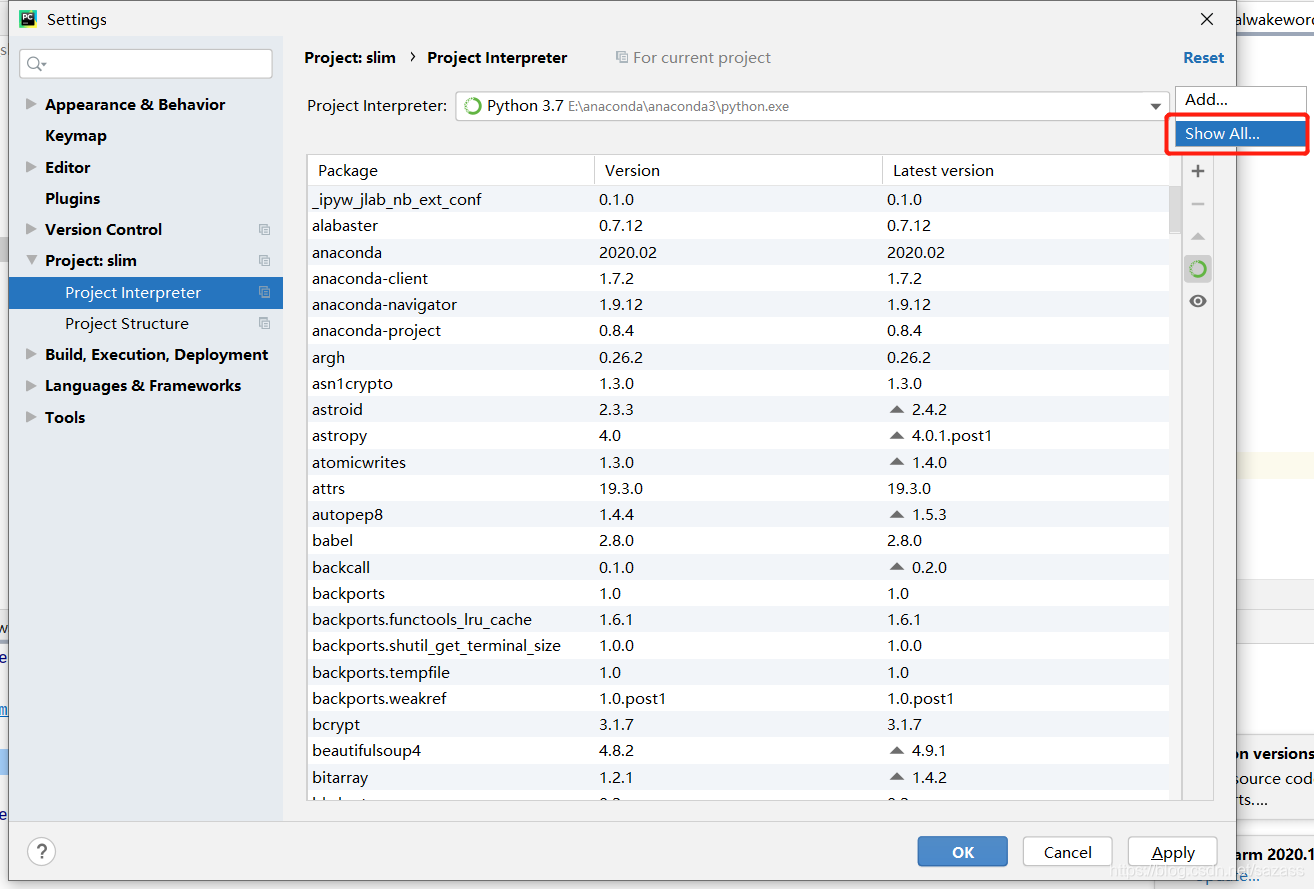
 然后找到自己创建的模拟环境的路径
然后找到自己创建的模拟环境的路径
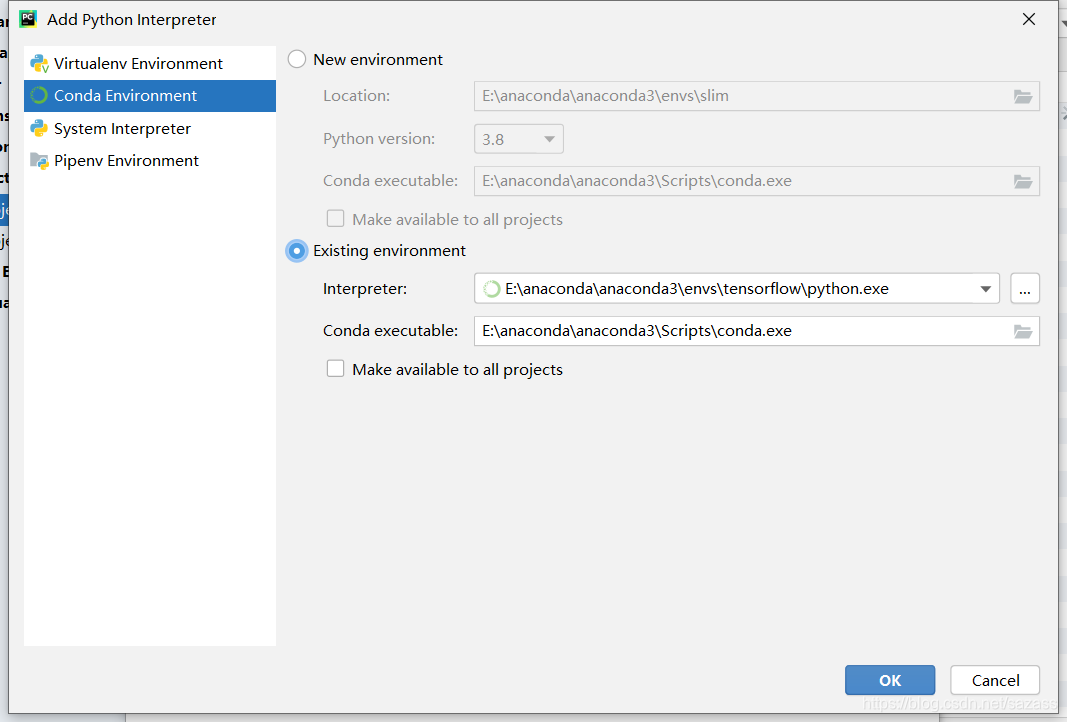
然后确认即可。
若是该虚拟环境没有安装tensroflow,可以pip下载:
在pycharm窗口的下方点击Terminal,然后利用pip下载tensorflow:
pip install tensorflow-gpu==2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple

下载完之后就可以在Project Interpreter内找到已经下载的包:
7.tensorflow模块的简单说明:
待更新······
8.在运行tensorflow的一些问题总结:
1.AttributeError: module ‘tensorflow’ has no attribute ‘Session’
原因:在新的Tensorflow 2.0版本中已经移除了Session这一模块
解决方案:
tf.Session() 更换为 tf.compat.v1.Session()
2.ImportError: No module named ‘contextlib2’
解决方案:
下载contextlib2,可以直接在pycharm上下载:
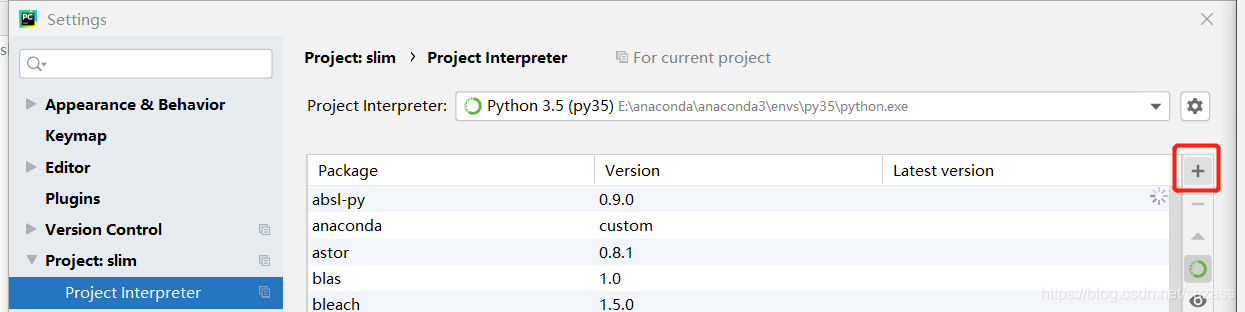
 或者终端下载:
或者终端下载:pip install contextlib2
3.ImportError: No module named 'PIL'
解决方案:
终端下载:pip install pillow
注:下载一般突然结束,并出现大量红字,应该是超时的问题,一般来说重新运行指令即可继续下载,若速度过满或文件过大造成反复超时,可采用国内源,
pip install pillow -i https://pypi.doubanio.com/simple/
4.AttributeError: module 'tensorflow' has no attribute 'flags'
类似:tf.flags.DEFINE_float,tf.flags.DEFINE_string会报错,找不到flags;
原因:tf.flags.DEFINE_float()是tensorflow1的用法,在tensorflow2里不可直接这样写,需要加上.compat.v1.app
解决方案:
整体上改为:tf.compat.v1.app.flags.DEFINE_float


5.AttributeError: module 'tensorflow' has no attribute 'gfile'
跳转之后这里出了问题:
if not tf.gfile.Exists(dataset_dir):tf.gfile.MakeDirs(dataset_dir)
问题产生的原因:在当前的版本中,gfile已经定义在io包的file_io.py中。
解决方法:修改如下:
if not tf.io.gfile.exists(dataset_dir):tf.io.gfile.makeDirs(dataset_dir)
还要注意函数大小写!!
这篇关于【tensorflow】windows下搭建tensorflow-slim网络进行目标分类(安装配置+使用教程+问题总结)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



