本文主要是介绍【操作系统入门到成神系列 三】如何写出让CPU跑出更快的代码?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,Java领域新星创作者。
- 📝个人公众号:爱敲代码的小黄(回复 “技术书籍” 可获千本电子书籍)
- 📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人
文章目录
- 如何写出让CPU跑出更快的代码
- 一、引言
- 二、CPU Cache 有多快
- 三、CPU Cache 的数据结构和读取过程是什么样的
- 1. 直接映射 Cache
- 四、如何写出让CPU跑的更快的代码
- 1. 如何提升数据缓存的命中率
- 2. 如何提升指令缓存的命中率
- 3. 如何提升多核CPU的缓存命中率
如何写出让CPU跑出更快的代码
代码都是由 CPU 跑起来的,我们代码写的好与坏就决定了 CPU 的执行效率,特别是在编写计算密集型的程序,更要注重 CPU 的执行效率,否则将会大大影响系统性能。
CPU 内部嵌入了 CPU Cache(高速缓存),它的存储容量很小,但是离 CPU 核心很近。
所以缓存的读写速度是极快的,那么如果 CPU 运算时,直接从 CPU Cache 读取数据,而不是从内存的话,运算速度就会很快。

一、引言
本文参考 小林coding 的《图解操作系统》,也是我十分喜欢的一个公众号博主,为他打 call
老读者知道我之前再写 Kafka 的博文,为什么突然开始写操作系统的呢?
原因在于:
当我看到 Kafka 服务端的一些 IO 操作时,我发现我看不懂了,了解之后发现这里 Netty 的概念。
当我尝试了解 IO 时,我发现一些内存、磁盘的交换,搞的我焦头烂额,于是,想静下心来从头开始。
当我把 小林coding 的 《图解操作系统》看完之后,我发现对操作系统的理解更上一层楼。
用一段话,作为今天的开场白:
读书的根本目的,未必是解决现实问题,它更像一场心灵的抚慰。
一个喜欢读书的人,可能不会记得自己读过哪些书。
但是那些看过的故事、收获的感悟、浸染过的气质,就像一颗种子,会在你的身体里慢慢发芽长大,不断提升你的认知,打开你的视野。
二、CPU Cache 有多快
为什么有内存还需要 CPU Cache?
- 根据摩尔定律,CPU的访问速度每 18 个月就会翻倍,内存的速度也会不断增长,但是增长的速度远远小于CPU,于是CPU和内存的访问性能被不断的拉大。
为了弥补 CPU 与内存两者的差距,在 CPU 内部引进了 CPU Cache,也被成为高速缓存
CPU Cache 通常分为大小不等的三级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache
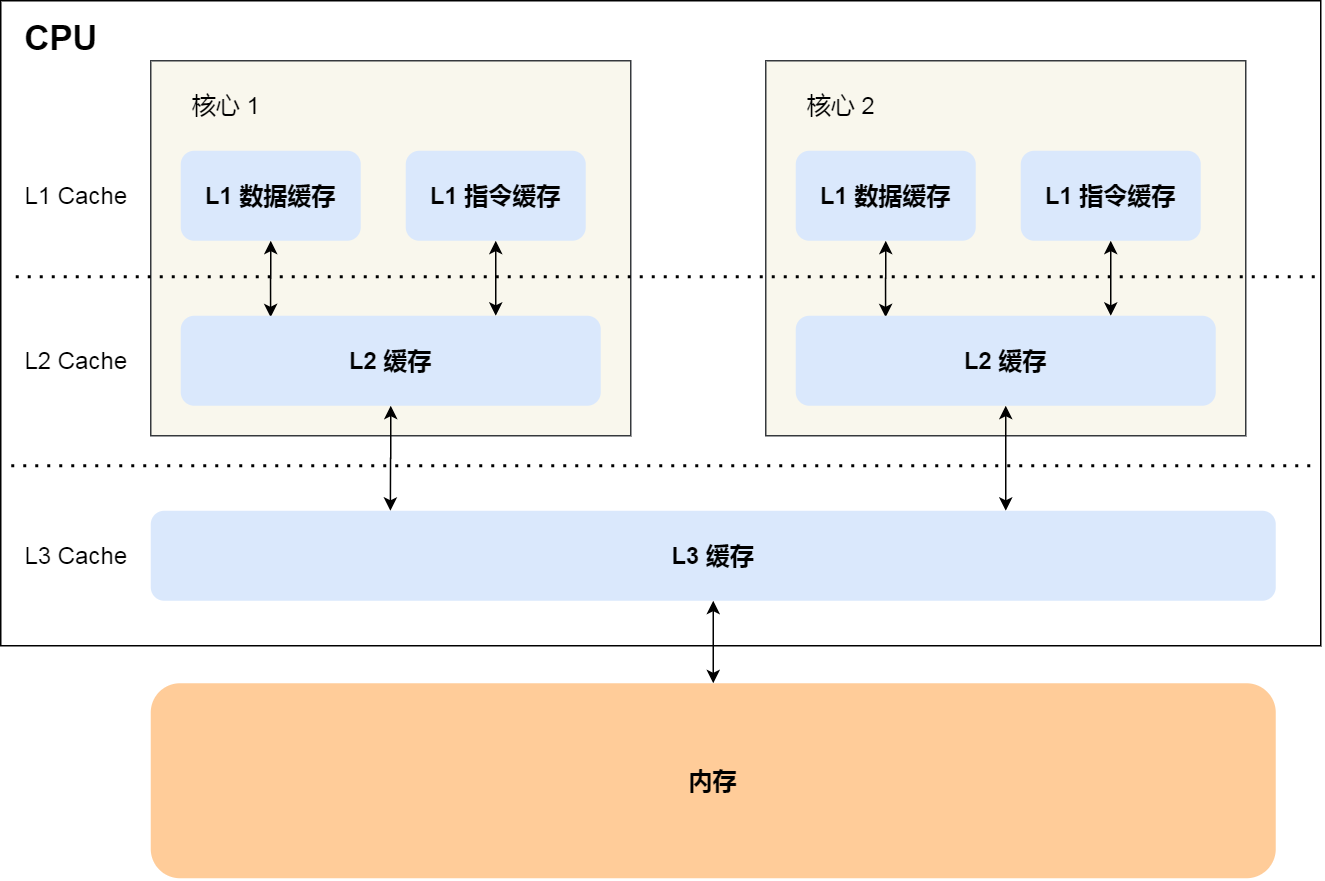
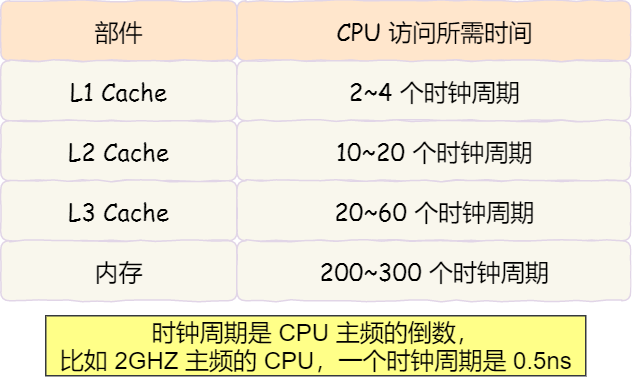
CPU 访问高速缓存的时间:
- L1 Cache:需要
2~4个时钟周期 - L2 Cache:需要
10~20个时钟周期 - L3 Cache:需要
20~60个时钟周期 - 内存:需要
200~300个时钟周期
三、CPU Cache 的数据结构和读取过程是什么样的
CPU Cache 的数据是从内存中读取过来的,以一小块一小块的读取数据,在CPU Cache 中,这样的一小块数据被称为:Cache Line(缓存块)
一般来说,缓存块的大小为:64字节。也就意味着 L1 Cache 一次载入数据的大小是 64 字节。
L1 Cache 一次性载入数据大小为 64 字节有什么作用?
在 Java 中,如果我们开辟一个 int[100] 的数组,每一个数组元素的大小为 4 字节。
相当于我们访问 int[0] 的数据,实际上
int[1]~int[15]的数据都会被加载到我们的 CPU Cache 中。因此,当我们下次访问这些数据时,直接从 CPU Cache 中查询,大大的提升了 CPU 读取数据的性能。
我们的 CPU 是怎么知道内存的数据在不在 CPU Cache 中呢?
1. 直接映射 Cache
前面我们提到过,CPU 访问内存数据时,是一小块一小块的读取的,这一小块的大小取决于:coherency_line_size
这里需要记住:
- 在内存中,这一小块被称为:内存块
- 在 CPU Cache 中,这一小块被称为:缓存块(Cache Line)
直接映射的策略:将我们内存块的地址映射到一个缓存块中的地址,映射实现的方式为【取模运算】,取模运算的结果就是内存块地址所对应的缓存块的地址。
比如:内存被划分 32 个内存块,CPU Cache 共有 8 个缓存块。假如我们的CPU想要访问第 15 号内存块,如果我们内存的数据已经被缓存到 CPU Cache 中,那么必定在第 7 号缓存块。因为 15 % 8 = 7
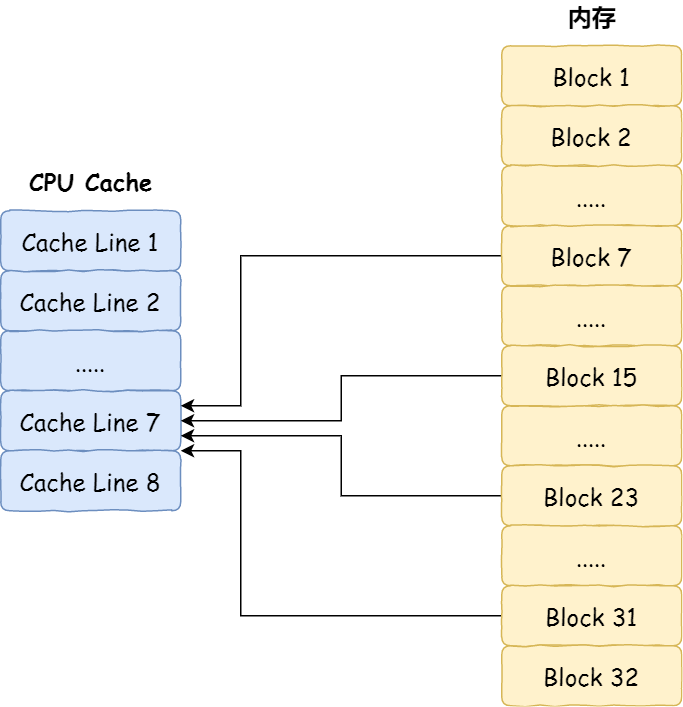
为了区分不同的内存块,在对应的缓存块中还会存储一个 组标记(Tag)。根据这个组标记来区分当前缓存块中的内存块的地址。
当然,除了组标记外,缓存块还有两个信息:
- 从内存加载过来实际存放的数据(data)
- 有效位(Valid bit):用来标记当前的缓存块的数据是否有效。如果为 0,则缓存块无效,会读取内存。
当然,我们的 CPU 从缓存块中读取数据时,并不是读取整个缓存块,而是读取 CPU 所需要的一个数据片段,这样的数据被称为一个 字(Word)。
问题来了,我们怎么能找到这个 字 呢?答案是:需要一个偏移量(offset)
因此,一个内存的访问地址,包括 组标记(Tag)、缓存块索引(Index)、偏移量 这三种信息,于是 CPU 能够通过这些信息,在缓存块中找到缓存的数据。
而对于 CPU Cache 的数据结构,则是由 索引 + 有效位 + 组标记 + 数据块

如果内存的数据已经在 CPU Cache 中了,我们的CPU会得到内存地址的信息(组标记、索引、偏移量)。
那 CPU 访问一个内存地址的时候,会经历以下 4 个步骤:
- 根据我们内存地址中的【索引】进行取模运算,计算出缓冲块中的索引,也就是缓冲块的地址。
- 找到对应的缓存块后,需要判断当前缓存块的有效位
- 如果是无效的,则直接访问内存,刷新数据
- 如果是有效的,则继续往下执行
- 根据我们内存地址的组标记找到缓存块中的组标记
- 如果不相等,则直接访问内存,刷新数据
- 如果相等,则继续往下执行
- 根据内存地址的偏移量,从我们的缓存块中读取对应的 字(word)
四、如何写出让CPU跑的更快的代码
我们想一下,怎么才能写出让 CPU 跑的更快的代码?如果我们想要访问的数据在 CPU Cache 中,那么我们 CPU 的速度也会跑的越快。
L1 Cache 通常分为数据缓存和指令缓存,这是因为 CPU 会分别处理数据和指令,比如 1 + 1 = 2 这个运算,+ 是指令,会被放在 指令缓存 中,而输入的数字 1 会被放在数据缓存中。
1. 如何提升数据缓存的命中率
// 二维数组
int N = 100;
array[N][N] = 0;// 样例一:
for(int i = 0; i < N; i++){for(int j = 0; j < N; j++){array[i][j] = 0;}
}// 样例二:
for(int i = 0; i < N; i++){for(int j = 0; j < N; j++){array[j][i] = 0;}
}
我们猜测一下上述样例一和样例二当中,哪一个样例的速度比较快?
经过测试,样例一 array[i][j] 执行时间比样例二 array[j][i] 快好几倍。
因为我们上面讲过,CPU Cache 会一次性加载 64KB 的顺序数据到缓存中, 我们样例一的数据为顺序数组数据,样例二为跳跃数组数据。
因此,遇到这种遍历数组的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升,
2. 如何提升指令缓存的命中率
有如下数组:
// 当前数组的值在 0~99 进行随机
int array[N];
for(int i = 0; i < N; i++){array[i] = random(100);
}
接下来对这个数组做两个操作:
// 操作一:数组遍历
for(int i = 0; i < N; i++){if(array[i] < 50){array[i] = 0;}
}// 操作二:排序
sort(array, array + N);
有一个问题:你觉得是先遍历再排序速度快,还是先排序再遍历速度快呢?
CPU的分支预测器:如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
通过上面的描述,我们如果元素是随机的,我们的分支预测器无法有效的工作,而当数组元素是顺序的,分支预测器会动态的根据历史数据对未来进行预测,这样命中率就会很高。
所以,答案是:先排序再遍历速度快
我们排序之后,刚开始数组的数据都小于 50,会疯狂的命中我们 if 指令,于是分支预测器将 if 指令放入指令缓存中,大大的提高运算的速度。
3. 如何提升多核CPU的缓存命中率
现代 CPU 都是多核心的,线程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
这篇关于【操作系统入门到成神系列 三】如何写出让CPU跑出更快的代码?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




