本文主要是介绍【C语言】函数指针存疑调试及回调函数编写(结构体内的Callback回调函数传参和虚伪的回调函数__weak声明),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【C语言】函数指针存疑调试及回调函数编写(结构体内的Callback回调函数传参和虚伪的回调函数__weak声明)
文章目录
- 函数指针存疑调试
- 函数指针
- 函数调用
- 回调函数编写
- 结构体内的回调函数
- 虚伪的回调函数
- 附录:压缩字符串、大小端格式转换
- 压缩字符串
- 浮点数
- 压缩Packed-ASCII字符串
- 大小端转换
- 什么是大端和小端
- 数据传输中的大小端
- 总结
- 大小端转换函数
函数指针存疑调试
函数指针
首先 函数指针就是指向函数地址的指针
而地址又可以用(void *)类型来表示
比如函数:
void a(int i)
{printf("i: %d\n",i);
}
其地址就是(void *)&a
那么我们可以定义一个typedef来指向该指针
void a(int i)
{printf("i: %d\n",i);
}
typedef void (*abc)(int i);
fxn=&a;
同样 若a的返回值为int类型 也可以通过强转换来实现
int a(int i)
{printf("i: %d\n",i);
}
typedef void (*abc)(int i);
fxn=(void *)&a;
但不建议这样做 因为这样做的话 fxn就没有了返回值
还是将typedef改成typedef int (*abc)(int i);比较好
这样在调用fxn函数时 也可以获取到返回值
函数调用
现在 我们把函数a的声明改成void
且给fxn赋值时不用(void *)强转
回到最初的样子
思考以下代码:
#include <stdio.h>
typedef void (*abc)(int i);void a(int i)
{printf("i: %d\n",i);
}int main(void)
{abc fxn;fxn=a;printf("取内容调用 %d\n",fxn);fxn(1);((abc) fxn) (2);((void (*)(int)) fxn) (3);(*fxn)(4);(* (abc) fxn) (5);(* (void (*)(int)) fxn) (6);fxn=&a;printf("取地址调用 %d\n",fxn);fxn(1);((abc) fxn) (2);((void (*)(int)) fxn) (3);(*fxn)(4);(* (abc) fxn) (5);(* (void (*)(int)) fxn) (6);
}运行结果:
取内容调用 4199760
i: 1
i: 2
i: 3
i: 4
i: 5
i: 6
取地址调用 4199760
i: 1
i: 2
i: 3
i: 4
i: 5
i: 6上半部分就是直接调用fxn函数的内容
下半部分就是调用fxn函数的地址
其中 i为1 2 3时为直接调用 为4 5 6时为取内容再调用
首先 通过两次对fxn变量的打印 我们发现都是4199760
也就是说
函数内容=函数地址
fxn=&fxn
那么反过来取地址上面的内容也成立
*fxn=*(&fxn)
可能有人会说 在typedef的时候 fxn就是地址
确实是这样 因为函数指针只能这样定义
但函数指针与普通的变量指针不同的是
变量指针赋值为变量是无法编译的
变量指针赋值为变量地址得到的是变量地址
函数指针赋值为函数得到的是函数地址
函数指针赋值为函数地址得到的是函数地址
说白了就是编译的问题
严格意义上来说 以下代码的第一行是不规范的 但是编译器优化以后 两者都一样
fxn=a;
fxn=&a;
但是 换成变量和变量指针 则会报错
int b=1;
int * c=b;
这就是函数指针和变量指针的区别
那么回到我们刚刚的测试代码
以下六种调用方法一毛一样:
fxn(1);((abc) fxn) (2);((void (*)(int)) fxn) (3);(*fxn)(4);(* (abc) fxn) (5);(* (void (*)(int)) fxn) (6);
且函数赋值也一样:
fxn=a;
fxn=&a;
所以:

但为了尽可能满足代码可读性 建议使用以下格式:
fxn=a;
fxn(1);
回调函数编写
此处的回调函数就是刚刚提到的函数指针
回调函数可以通过传参的形式传给其他函数
从而在其他函数内被调用
结构体内的回调函数
此方法经常在TI ADI等生态的sdk被看到
其中 TI最喜欢结构体内套结构体了 就算只有一个变量也要套结构体
比如TI毫米波雷达SDK:
定义:
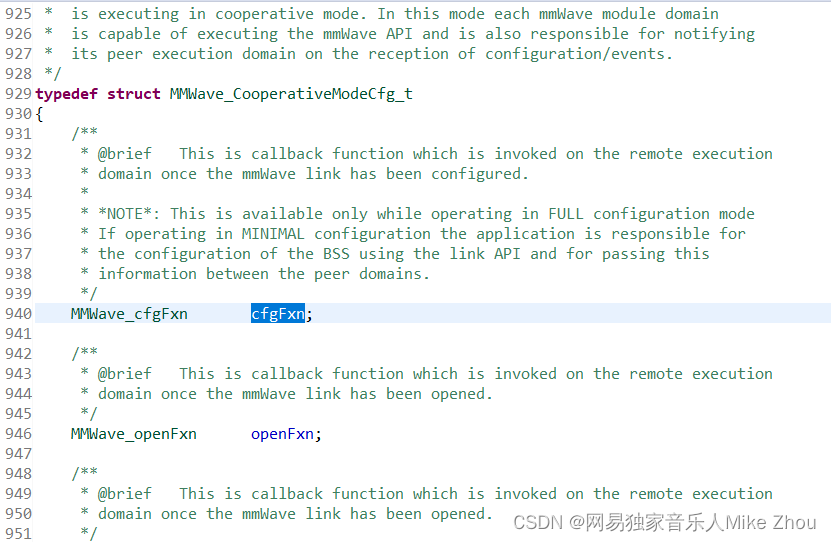
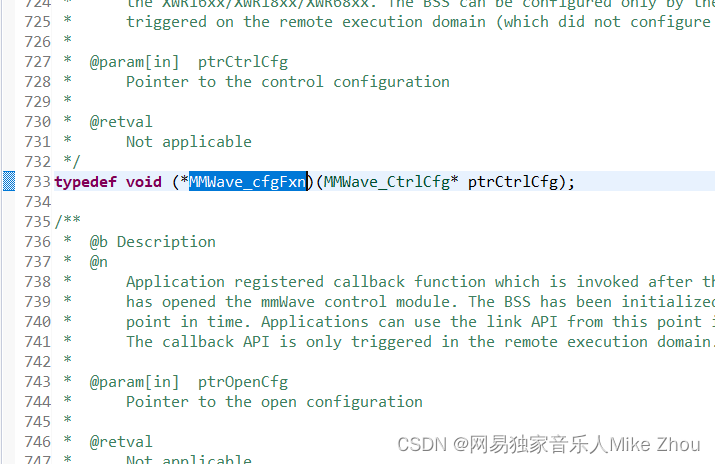
赋值:
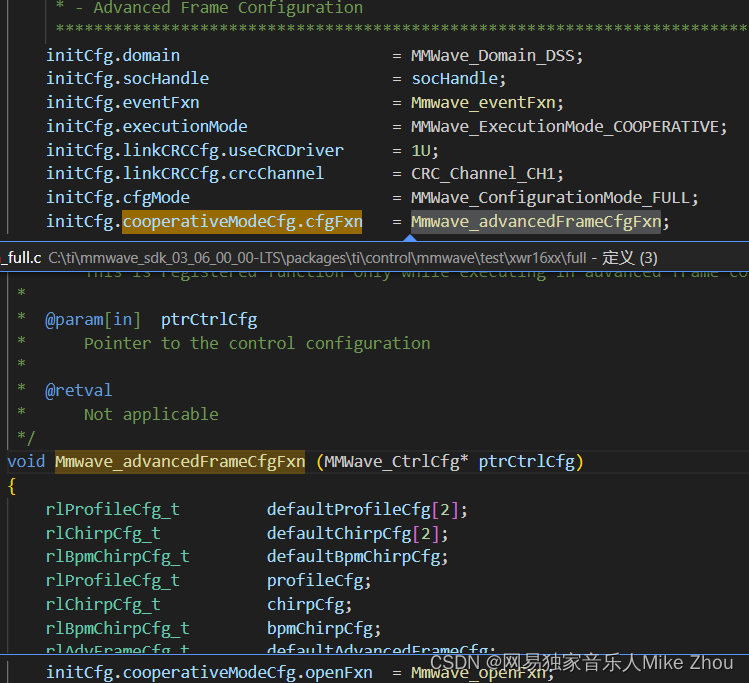
调用:
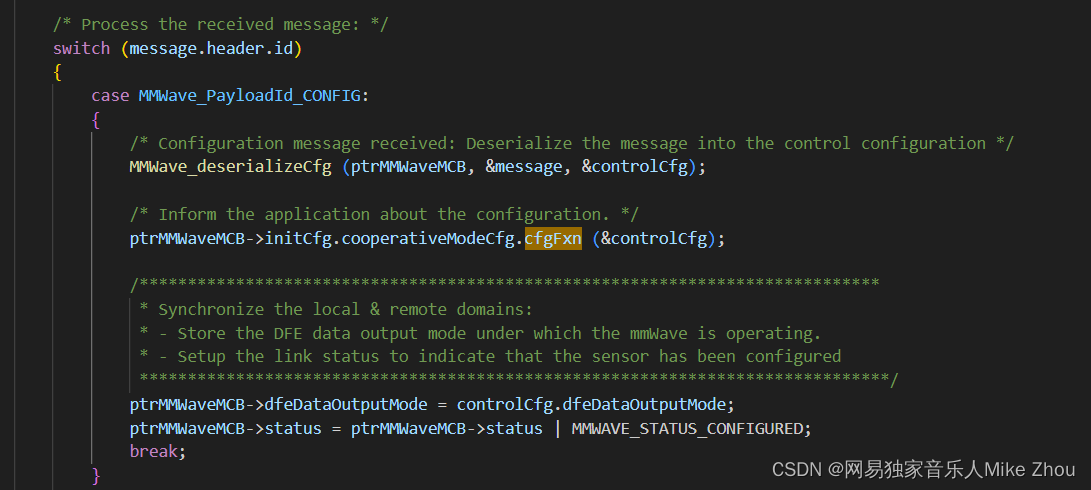
可以看到 无论是定义还是赋值 或者调用 都是用的最简单的方法
我们可以定义一个结构体 把刚刚我们定义的函数指针变量放进去:
typedef void (*abc)(int i);typedef struct
{abc fxn;
}text;
调用时 用最简单的方法赋值并调用:
text stu;
stu.fxn=a;
stu.fxn(1);
完整代码:
#include <stdio.h>
typedef void (*abc)(int i);typedef struct
{abc fxn;
}text;void a(int i)
{printf("i: %d\n",i);
}int main(void)
{text stu;stu.fxn=a;stu.fxn(1);
}虚伪的回调函数
在STM32的生态中 比如HAL库内 有很多回调函数
其定义都是用了__weak声明
也就是__attribute__((weak))
是一种GNU编译器里面的修饰变量
用于告诉编译器这个函数是可以被覆写修改的
定义:

调用:
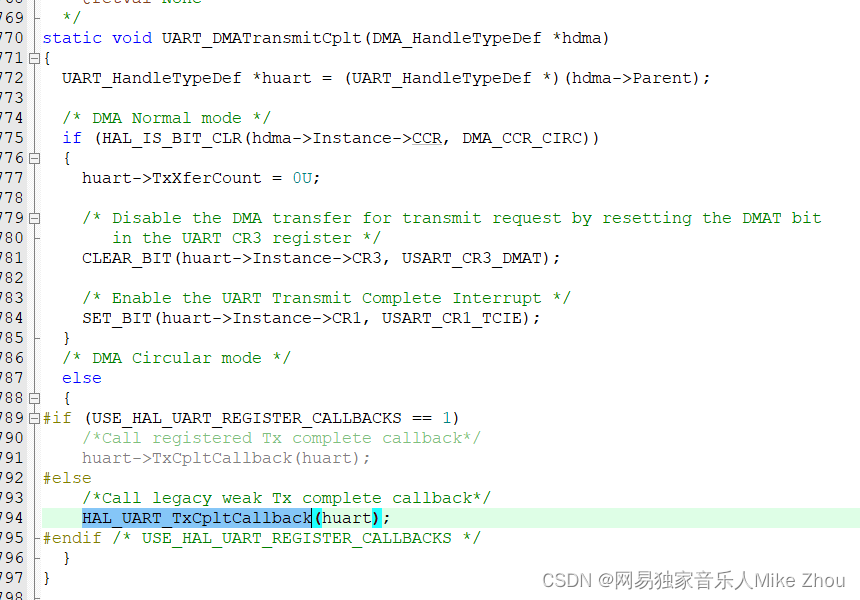
而赋值的话 就是用户自己来写了
比如:
void HAL_UART_TxCpltCallback(UART_HandleTypeDef *huart)
{
if(huart==&RF_UART_Handle){ //HAL_UART_Transmit(&RF_UART_Handle,&RxBuffer,1,0xFFFF);HAL_UART_Receive_IT(&RF_UART_Handle,&RxBuffer,1);}
}这种回调函数虽然叫Callback 但实际上与函数指针无关 不是真正的回调函数
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}压缩Packed-ASCII字符串
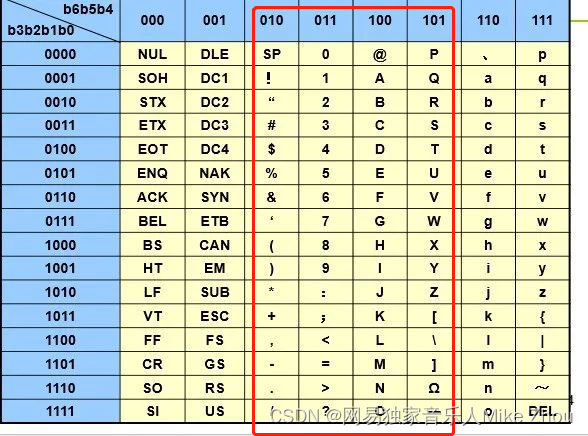
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表
压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(buf,0,str_len/4*3); for(i=0;i<str_len;i++){if(str[i]==0x00){str[i]=0x20;}}for(i=0;i<str_len/4;i++){buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);}return 1;
}//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(str,0,str_len);for(i=0;i<str_len/4;i++){str[4*i]=(buf[3*i]>>2)&0x3F;str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);str[4*i+3]=buf[3*i+2]&0x3F;}return 1;
}大小端转换
在串口等数据解析中 难免遇到大小端格式问题
什么是大端和小端
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
简单来说:大端——高尾端,小端——低尾端
举个例子,比如数字 0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
数据传输中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
则发送的buf应为{0x52,0x0A}
而数据位一般是小端格式(单字节无大小端之分)
如:
一个16位的数据发送出来为{0x52,0x0A}
则对应的uint16_t类型数为: 0x0A52
而对于浮点数4.0f 转为32位应是:
40 80 00 00
以大端存储来说 发送出来的buf就是依次发送 40 80 00 00
以小端存储来说 则发送 00 00 80 40
由于memcpy等函数 是按字节地址进行复制 其复制的格式为小端格式 所以当数据为小端存储时 不用进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x00,0x00,0x80,0x40};memcpy(&dat,buf,4);float f=0.0f;f=*((float*)&dat); //地址强转printf("%f",f);
或更优解:
uint8_t buf[]={0x00,0x00,0x80,0x40}; float f=0.0f;memcpy(&f,buf,4);
而对于大端存储的数据(如HART协议数据 全为大端格式) 其复制的格式仍然为小端格式 所以当数据为小端存储时 要进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};memcpy(&dat,buf,4);float f=0.0f;swap32(&dat); //大小端转换f=*((float*)&dat); //地址强转printf("%f",f);
或:
uint8_t buf[]={0x40,0x80,0x00,0x00};memcpy(&dat,buf,4);float f=0.0f;swap32(&f); //大小端转换printf("%f",f);
或更优解:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};float f=0.0f;dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)f=*((float*)&dat);
总结
固 若数据为小端格式 则可以直接用memcpy函数进行转换 否则通过移位的方式再进行地址强转
对于多位数据 比如同时传两个浮点数 则可以定义结构体之后进行memcpy复制(数据为小端格式)
对于小端数据 直接用memcpy写入即可 若是浮点数 也不用再进行强转
对于大端数据 如果不嫌麻烦 或想使代码更加简洁(但执行效率会降低) 也可以先用memcpy写入结构体之后再调用大小端转换函数 但这里需要注意的是 结构体必须全为无符号整型 浮点型只能在大小端转换写入之后再次强转 若结构体内采用浮点型 则需要强转两次
所以对于大端数据 推荐通过移位的方式来进行赋值 然后再进行个别数的强转 再往通用结构体进行写入
多个不同变量大小的结构体 要主要字节对齐的问题
可以用#pragma pack(1) 使其对齐为1
但会影响效率
大小端转换函数
直接通过对地址的操作来实现 传入的变量为32位的变量
中间变量ptr是传入变量的地址
void swap16(void * p)
{uint16_t *ptr=p;uint16_t x = *ptr;x = (x << 8) | (x >> 8);*ptr=x;
}void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}void swap64(void * p)
{uint64_t *ptr=p;uint64_t x = *ptr;x = (x << 32) | (x >> 32);x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);*ptr=x;
}
这篇关于【C语言】函数指针存疑调试及回调函数编写(结构体内的Callback回调函数传参和虚伪的回调函数__weak声明)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




