本文主要是介绍访问微博热搜榜,获取微博热搜榜前50条热搜名称、链接及其实时热度,并将获取到的数据以邮件的形式发送,每20秒一次发送到个人邮箱中。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、需求
访问微博热搜榜(Sina Visitor System),获取微博热搜榜前50条热搜名称、链接及其实时热度,并将获取到的数据通过邮件的形式,每20秒发送到个人邮箱中。
注意事项:
- 定义请求头
本实验需要获取User-Agent、Accept、Accept-Language、Cookie四个字段,前三个字段可能都是相同的,主要是Cookie不同。具体获取流程如下:
打开目标网页,本实验目标网页为Sina Visitor System
按键盘上面F12进入开发者模式,此时页面如下:

按键盘上面F5刷新页面,此时开发者模式中会有网页相关信息,页面如下:
依次点击Network、All、以及summary(即目标链接的地址),各个位置如下图所示:
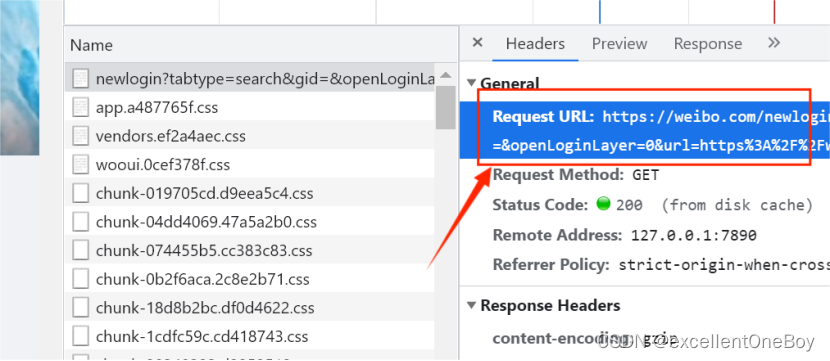
点击summary后出现右侧窗口,点击Header能够得到相关报文字段,如下图所示:
cookie获取

def job():print('**************开始爬取微博热搜**************')header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'zh-CN,zh-Hans;q=0.9','Cookie':#填上自己的}url = 'https://s.weibo.com/top/summary'html = page_request(url=url, header=header)page_parse(html)邮件发送程序。
以网易邮箱为例,开通自己的授权码,QQ邮箱同理。
登录自己的网易邮箱
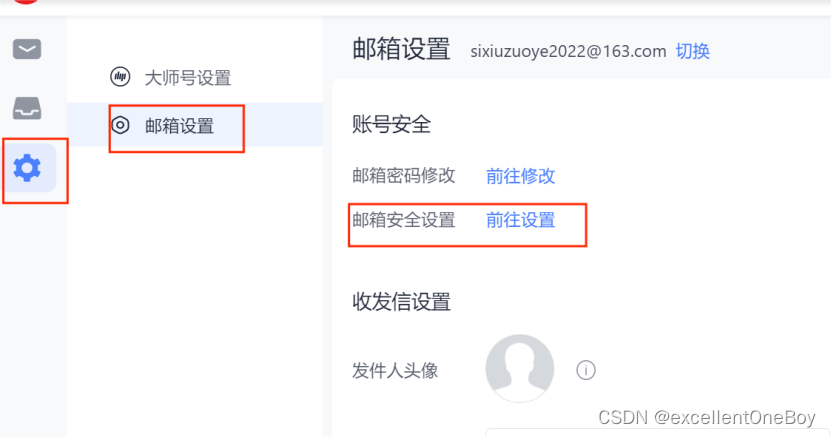


会生成一个授权码,你把那个授权码填到代码里就可以了。
class Email163(object):HOST = 'smtp.qq.com'#网易邮箱是 smtp.163.comPORT = '25'#默认的不用改PASSWORD = 'XXXXXXXXX'填写自己的授权码FROM_ADDR = 'XXX@qq.com'#填上自己的邮箱SUBTYPE_PLAIN = 'plain'SUBTYPE_HTML = 'html'ATTACHMENT = 'attachment'EMBEDDED = 'embedded'def __init__(self, body: str, to_addrs: str) -> None:msg = MIMEText(body, self.SUBTYPE_PLAIN, 'utf-8')msg['From'] = self.FROM_ADDRmsg['To'] = to_addrs# 设置邮件的格式以及发送主题msg['subject'] = Header('微博热搜', 'utf-8')self.msg = msg.as_string()self.to_addrs = to_addrsdef send_default_email(self) -> None:try:smtp = smtplib.SMTP()smtp.connect(self.HOST, self.PORT)smtp.login(self.FROM_ADDR, self.PASSWORD)smtp.sendmail(self.FROM_ADDR, self.to_addrs, self.msg)smtp.close()print(f'邮件成功发送给:{self.to_addrs}')except smtplib.SMTPException:raise Exception(f'给{self.to_addrs}发送邮件失败')完整代码
# 爬虫相关模块
from bs4 import BeautifulSoup
# 发送邮箱相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import urllib.request
# 定时模块
import schedule
import time
# 请求网页
import urllib.request
import gzip
class Email163(object):HOST = 'smtp.163.com'PORT = '25'PASSWORD = 'XXXXXXXXXXX'#授权码FROM_ADDR = '自己的邮箱'#填自己的SUBTYPE_PLAIN = 'plain'SUBTYPE_HTML = 'html'ATTACHMENT = 'attachment'EMBEDDED = 'embedded'def __init__(self, body: str, to_addrs: str) -> None:msg = MIMEText(body, self.SUBTYPE_PLAIN, 'utf-8')msg['From'] = self.FROM_ADDRmsg['To'] = to_addrs# 设置邮件的格式以及发送主题msg['subject'] = Header('微博热搜', 'utf-8')self.msg = msg.as_string()self.to_addrs = to_addrsdef send_default_email(self) -> None:try:smtp = smtplib.SMTP()smtp.connect(self.HOST, self.PORT)smtp.login(self.FROM_ADDR, self.PASSWORD)smtp.sendmail(self.FROM_ADDR, self.to_addrs, self.msg)smtp.close()print(f'邮件成功发送给:{self.to_addrs}')except smtplib.SMTPException:raise Exception(f'给{self.to_addrs}发送邮件失败')
def page_request(url, header):request = urllib.request.Request(url, headers=header)html = ''try:response = urllib.request.urlopen(request)if response.info().get('Content-Encoding') == 'gzip':# 如果响应使用gzip压缩,则解压缩数据compressed_data = response.read()decompressed_data = gzip.decompress(compressed_data)html = decompressed_data.decode('utf-8')else:html = response.read().decode('utf-8')except urllib.error.URLError as e:if hasattr(e, 'code'):print(e.code)if hasattr(e, 'reason'):print(e.reason)return html
# 解析网页
def page_parse(html):soup = BeautifulSoup(html, 'lxml')news = []# 处理热搜前50urls_title = soup.select('#pl_top_realtimehot > table > tbody > tr > td.td-02 > a')hotness = soup.select('#pl_top_realtimehot > table > tbody > tr > td.td-02 > span')for i in range(len(urls_title)):new = {}title = urls_title[i].get_text()url = urls_title[i].get('href')# 个别链接会出现异常if url == 'javascript:void(0);':url = urls_title[i].get('href_to')# 热搜top没有显示热度if i == 0:hot = 'top'else:hot = hotness[i - 1].get_text()new['title'] = titlenew['url'] = "https://s.weibo.com" + urlnew['hot'] = hotnews.append(new)print(len(news))print(news)for element in news:print(element['title'] + '\t' + element['hot'] + '\t' + element['url'])content = ''for i in range(len(news)):content += str(i) + '、\t' + news[i]['title'] + '\t' + '热度:' + news[i]['hot'] + '\t' + '链接:' + news[i]['url'] + ' \n'get_time = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '\n'content += '获取事件时间为' + get_timeto_addrs = '接收邮箱'#填上自己的email163 = Email163(content, to_addrs)email163.send_default_email()
def job():print('**************开始爬取微博热搜**************')header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'zh-CN,zh-Hans;q=0.9','Cookie':'自己的cookie'#填自己的}url = 'https://s.weibo.com/top/summary'html = page_request(url=url, header=header)page_parse(html)
if __name__ == "__main__":# 定时爬取,每隔20s爬取一次微博热搜榜并将爬取结果发送至个人邮箱# 可以将20修改成其他时间schedule.every(20).seconds.do(job)while True:schedule.run_pending()这篇关于访问微博热搜榜,获取微博热搜榜前50条热搜名称、链接及其实时热度,并将获取到的数据以邮件的形式发送,每20秒一次发送到个人邮箱中。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




