本文主要是介绍3D LUT 滤镜 shader 源码分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在做滤镜相关的渲染学习,目前大部分 LUT 滤镜代码实现都是参考由 GPUImage 提供的 LookupFilter 的逻辑,整个代码实现不多。参考网上的博文也有各种解释,参考了大量博文之后终于理解了,所以自己重新整理了一份,方便以后阅读理解,对整体代码的实现过程结合LUT的原理进行一个简单整理。
GPUImageLookupFilter shader 源码
varying highp vec2 textureCoordinate; varying highp vec2 textureCoordinate2;uniform sampler2D inputImageTexture; // 目标纹理,对应原始资源uniform sampler2D inputImageTexture2; // 查找表纹理,对应LUT图片uniform lowp float intensity;void main(){//获取原始图层颜色highp vec4 textureColor = texture2D(inputImageTexture, textureCoordinate);//获取蓝色通道颜色,textureColor.b 的范围为(0,1),blueColor 范围为(0,63) highp float blueColor = textureColor.b * 63.0;//quad1为查找颜色所在左边位置的小正方形highp vec2 quad1;quad1.y = floor(floor(blueColor) / 8.0);quad1.x = floor(blueColor) - (quad1.y * 8.0);//quad2为查找颜色所在右边位置的小正方形highp vec2 quad2;quad2.y = floor(ceil(blueColor) / 8.0);quad2.x = ceil(blueColor) - (quad2.y * 8.0);//获取到左边小方形里面的颜色值highp vec2 texPos1;texPos1.x = (quad1.x * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.r);texPos1.y = (quad1.y * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.g);//获取到右边小方形里面的颜色值highp vec2 texPos2;texPos2.x = (quad2.x * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.r);texPos2.y = (quad2.y * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.g);//获取对应位置纹理的颜色 RGBA 值lowp vec4 newColor1 = texture2D(inputImageTexture2, texPos1);lowp vec4 newColor2 = texture2D(inputImageTexture2, texPos2);//真正的颜色是 newColor1 和 newColor2 的混合lowp vec4 newColor = mix(newColor1, newColor2, fract(blueColor));gl_FragColor = mix(textureColor, vec4(newColor.rgb, textureColor.w), intensity);}
整个源码的主要逻辑为:查找颜色所在位置的小正方形、查找小正方形内的具体颜色、颜色混合。上面注释已将具体的实现过程描述清楚,但与我们的 LUT 图片割裂,接下来结合 LUT 的实现原理以及具体的数据来形象地描述整个实现流程。
假设我们输入的参数为:
textureColor = ver4(.0, .0, 0.5, 1.0)
查找颜色所在位置的小正方形
我们知道LUT有64个小正方形,目标是为了找到对应小正方形里面的对应的颜色,我们需要先确认是第几个小正方形,正是通过 textureColor.b * 63 查找
带入blueColor -> textureColor.b = 0.5
对 textureColor.b * 63.0 = 31.5
也就是说我们需要第 [31.5] 位置小正方形,但是索引(从0-63共64个)都是正数,对于 31.5 索引 我们该怎么确定是 31 还是第 32 个呢?GPUImage给出的一种插值方式就是两个都要,然后进行一次混合,从而使得值能够俊均匀的在两个小正方形色块中。
具体逻辑为:
quad1.y = floor(floor(blueColor) / 8.0) = 3,确定为小方块在纵坐标索引3,也就是第4行。
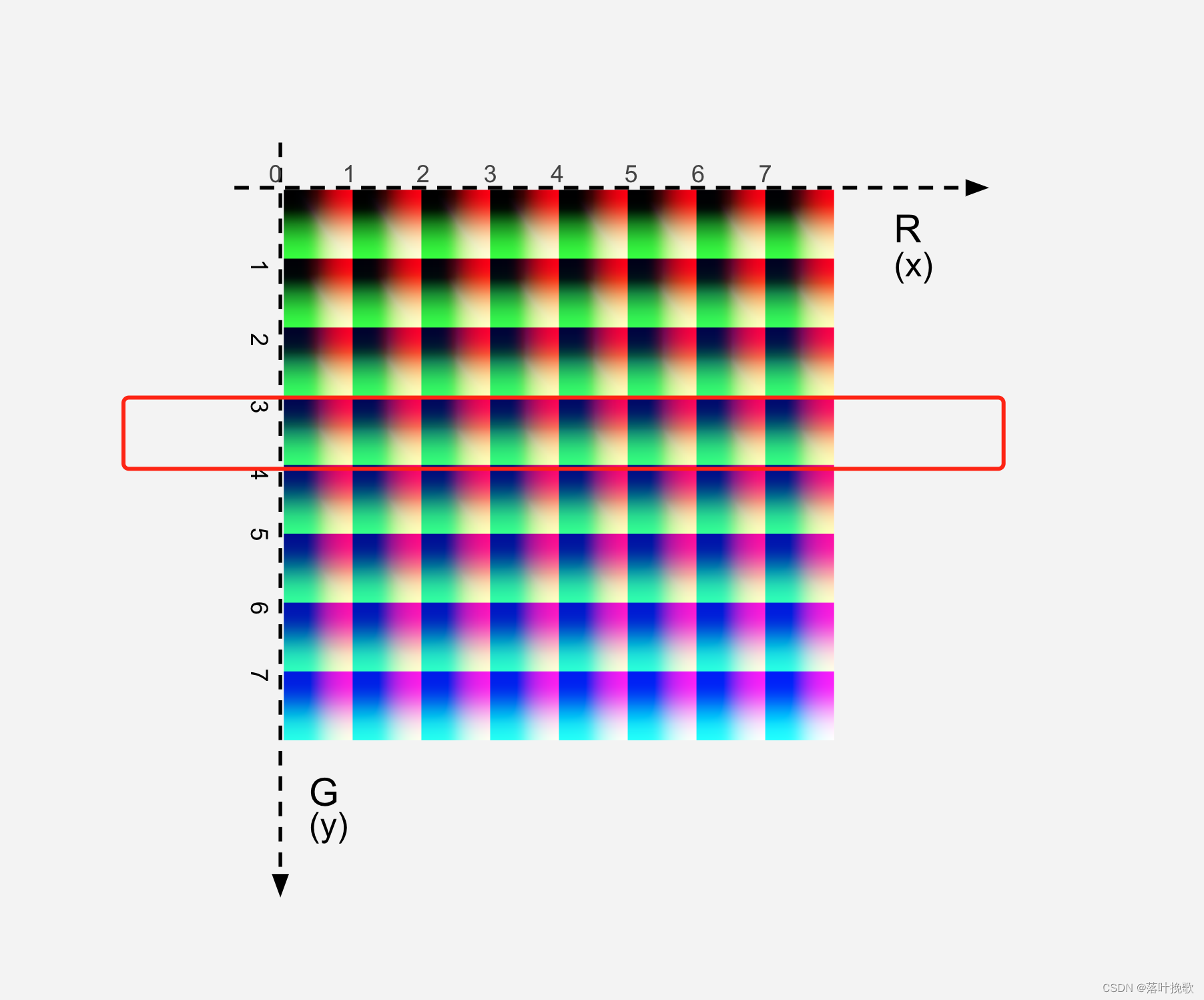
quad1.x = floor(blueColor) - (quad1.y * 8.0) = 31 - 24 = 7
也就确定了小方块为(3,7) 也就是第4排第8个。

同理,对于第2个小方块确定的位置为(4,0) 也就是第5排第1个。
quad2.y = floor(ceil(blueColor) / 8.0) = 4
quad2.x = ceil(blueColor) - (quad2.y * 8.0)= 0
查找小正方形内的具体颜色
已经获取到对应的方块了,接下来需要确定方块内的像素的位置了。一般一个LUT的大小为 512x512,由8x8小方块构成,也就是每个方块的的像素为64x64,如下图所示:

计算x坐标的逻辑为:
texPos1.x = (quad1.x * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.r)
这一段是相对比较难理解的,我们可以分几部分进行理解:
第一部分:(quad1.x * 0.125)
我们得到 quad1.x = 7,也就是第8列,*0.125将坐标转化在(0,1)之间,也就是得到在01坐标系内如图红线的位置。
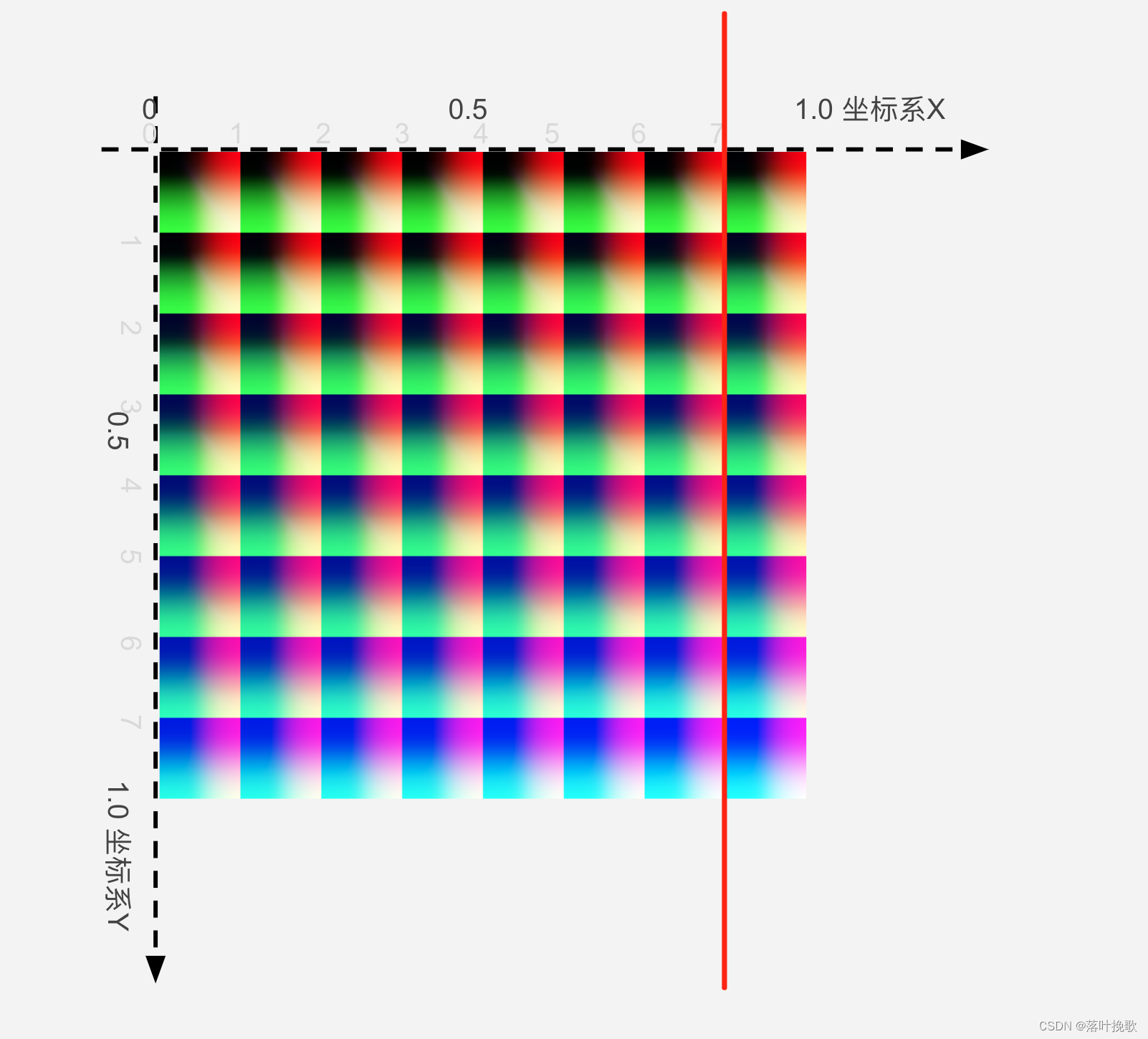
第二部分:((0.125 - 1.0/512.0) * textureColor.r)
我们可以把它当成 (63.0/512.0)* textureColor.r , 63.0/512.0代表着一个512x512中每个小方块的64份数据(为什么是63?别忘了0的存在),textureColor.r 数据在 0-1之间,这样就能确认在第一部分结果基础之上的偏移值。

第三部分:0.5/512.0
这一部分主要是 +0.5 做四舍五入运算,为保证第512行取到的是511.5/512,第1行取到的是 0.5/512.0。
同理,计算y的坐标,以及计算另一个小正方形内的位置是一样的。
最后在通过对从两个小正方形获取到的颜色进行 mix,并返回给着色器,GPU再对原始图像进行每一个像素点绘制,从而实现滤镜的效果。
总结
LUT 对应的 Shader 执行过程主要为:查找颜色所在位置的小正方形、查找小正方形内的具体颜色、颜色混合,整个流程都比较好理解,但代码相对而言比较难理解,网上看了很多其他的大佬写的一些文章,最开始自己看的时候也是很难理解的,后面终于悟了,所以想通过自己的理解,尽力更形象地解释(虽然可能也没有很形象),如果还有什么疑问,欢迎一起交流学习。
这篇关于3D LUT 滤镜 shader 源码分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






