本文主要是介绍《PaddlePaddle从入门到炼丹》十——VisualDL 训练可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
VisualDL是一个面向深度学习任务设计的可视化工具,包含了scalar、参数分布、模型结构、图像可视化等功能。可以这样说:“所见即所得”。我们可以借助VisualDL来观察我们训练的情况,方便我们对训练的模型进行分析,改善模型的收敛情况。
scalar,趋势图,可用于训练测试误差的展示
image, 图片的可视化,可用于卷积层或者其他参数的图形化展示
histogram, 用于参数分布及变化趋势的展示
graph,用于训练模型结构的可视化
以上的图像来自VisualDL的Github
既然那么方便,那么我们就来尝试一下吧。VisualDL底层采用C++编写,但是它在提供C++ SDK的同时,也支持Python SDK,我们主要是使用Python的SDK。顺便说一下,VisualDL除了支持PaddlePaddle,之外,还支持pytorch, mxnet在内的大部分主流DNN平台。
VisualDL的安装
本章只讲述在Ubuntu系统上的安装和使用,Mac的操作应该也差不多。
使用pip安装
使用pip安装非常简单,只要一条命令就够了,如下:
pip3 install --upgrade visualdl
测试一下是否安装成功了,运行一个例子下载日志文件:
# 在当前位置下载一个日志
vdl_create_scratch_log
然后再输入,启动VisualDL并加载这个日志信息:
visualdl --logdir=scratch_log/ --port=8080
这里说明一下,visualDL的参数:
host设定IPport设定端口model_pb指定 ONNX 格式的模型文件,这木方我们还没要用到
注意: 如果是报以下的错误,那是因为protobuf版本过低的原因。
root@test:/home/test/VisualDL# visualdl --logdir ./scratch_log --port 8080
Traceback (most recent call last):File "/usr/local/bin/visualdl", line 29, in <module>import visualdl.server.graph as vdl_graphFile "/usr/local/lib/python2.7/dist-packages/visualdl/server/graph.py", line 23, in <module>from . import onnxFile "/usr/local/lib/python2.7/dist-packages/visualdl/server/onnx/__init__.py", line 8, in <module>from .onnx_pb2 import ModelProtoFile "/usr/local/lib/python2.7/dist-packages/visualdl/server/onnx/onnx_pb2.py", line 213, in <module>options=None, file=DESCRIPTOR),
TypeError: __init__() got an unexpected keyword argument 'file'
protobuf的版本要不小于3.5.0,如何小于这个版本可以使用以下命令升级:
pip3 install protobuf -U
然后在浏览器上输入:
http://127.0.0.1:8080
即可看到一个可视化的界面,如下:
使用源码安装
如果读者出于各种情况,使用pip安装不能满足需求,那可以考虑使用源码安装VisualDL,操作如下:
首先要安装依赖库:
# 安装npm
apt install npm
# 安装node
apt install nodejs-legacy
# 安装cmake
apt install cmake
# 安装unzip
apt install unzip
然后在GitHub上clone最新的源码并打开:
git clone https://github.com/PaddlePaddle/VisualDL.git
cd VisualDL
之后是编译生成whl安装包:
python3 setup.py bdist_wheel
生成whl安装包之后,就可以使用pip命令安装这个安装包了,*号对应的是visualdl版本号,读者要根据实际情况来安装:
pip3 install --upgrade dist/visualdl-*.whl
安装完成之后,同样可以使用在上一部分的使用pip安装的测试方法测试安装是否成功。
简单使用VisualDL
我们编写下面这一小段的代码来学习VisualDL的使用,test_visualdl.py的代码如下:
# 导入VisualDL的包
from visualdl import LogWriter# 创建一个LogWriter,第一个参数是指定存放数据的路径,
# 第二个参数是指定多少次写操作执行一次内存到磁盘的数据持久化
logw = LogWriter("./random_log", sync_cycle=10000)# 创建训练和测试的scalar图,
# mode是标注线条的名称,
# scalar标注的是指定这个组件的tag
with logw.mode('train') as logger:scalar0 = logger.scalar("scratch/scalar")with logw.mode('test') as logger:scalar1 = logger.scalar("scratch/scalar")# 读取数据
for step in range(1000):scalar0.add_record(step, step * 1. / 1000)scalar1.add_record(step, 1. - step * 1. / 1000)
运行Python代码之后,在终端上输入,从上面的代码可以看到我们定义的路径是./random_log:
visualdl --logdir=random_log/ --port=8080
然后在浏览器上输入:
http://127.0.0.1:8080
然后就可以看到刚才编写Python代码生成的图像了:
经过这个例子,读者对VisualDL有了进一步的了解了,那么在接下来的我们就在实际的PaddlePaddle例子中使用我们的VisualDL。
在PaddlePaddle使用VisualDL
下面就介绍在PaddlePaddle训练中使用VisualDL,通过在训练的时候使用VisualDL不断收集训练的数据集,最终通过可视化展示出来。
定义MobileNet V2神经网络
创建一个mobilenet_v2.py来定义一个MobileNet V2神经网络。MobileNet V2是MobileNet V1的升级版,从名字可以看出这个网络是为例移动设备而诞生的,它最大的特点就是模型小,预测速度快,适合部署在移动设备上。MobileNet V2是将MobileNet V1和残差网络ResNet的残差单元结合起来,用Depthwise Convolutions代替残差单元的bottleneck,最重要的是与residuals block相反,通常的residuals block是先经过1×1的卷积,降低feature map通道数,然后再通过3×3卷积,最后重新经过1×1卷积将feature map通道数扩张回去;而且为了避免ReLU对特征的破坏,用线性层替换channel数较少层后的ReLU非线性激活。
import paddle.fluid as fluiddef conv_bn_layer(input, filter_size, num_filters, stride, padding, num_groups=1, if_act=True, use_cudnn=True):conv = fluid.layers.conv2d(input=input,num_filters=num_filters,filter_size=filter_size,stride=stride,padding=padding,groups=num_groups,use_cudnn=use_cudnn,bias_attr=False)bn = fluid.layers.batch_norm(input=conv)if if_act:return fluid.layers.relu6(bn)else:return bndef shortcut(input, data_residual):return fluid.layers.elementwise_add(input, data_residual)def inverted_residual_unit(input,num_in_filter,num_filters,ifshortcut,stride,filter_size,padding,expansion_factor):num_expfilter = int(round(num_in_filter * expansion_factor))channel_expand = conv_bn_layer(input=input,num_filters=num_expfilter,filter_size=1,stride=1,padding=0,num_groups=1,if_act=True)bottleneck_conv = conv_bn_layer(input=channel_expand,num_filters=num_expfilter,filter_size=filter_size,stride=stride,padding=padding,num_groups=num_expfilter,if_act=True,use_cudnn=False)linear_out = conv_bn_layer(input=bottleneck_conv,num_filters=num_filters,filter_size=1,stride=1,padding=0,num_groups=1,if_act=False)if ifshortcut:out = shortcut(input=input, data_residual=linear_out)return outelse:return linear_outdef invresi_blocks(input, in_c, t, c, n, s, name=None):first_block = inverted_residual_unit(input=input,num_in_filter=in_c,num_filters=c,ifshortcut=False,stride=s,filter_size=3,padding=1,expansion_factor=t)last_residual_block = first_blocklast_c = cfor i in range(1, n):last_residual_block = inverted_residual_unit(input=last_residual_block,num_in_filter=last_c,num_filters=c,ifshortcut=True,stride=1,filter_size=3,padding=1,expansion_factor=t)return last_residual_blockdef net(input, class_dim, scale=1.0):bottleneck_params_list = [(1, 16, 1, 1),(6, 24, 2, 2),(6, 32, 3, 2),(6, 64, 4, 2),(6, 96, 3, 1),(6, 160, 3, 2),(6, 320, 1, 1),]# conv1input = conv_bn_layer(input,num_filters=int(32 * scale),filter_size=3,stride=2,padding=1,if_act=True)# bottleneck sequencesi = 1in_c = int(32 * scale)for layer_setting in bottleneck_params_list:t, c, n, s = layer_settingi += 1input = invresi_blocks(input=input,in_c=in_c,t=t,c=int(c * scale),n=n,s=s,name='conv' + str(i))in_c = int(c * scale)# last_convinput = conv_bn_layer(input=input,num_filters=int(1280 * scale) if scale > 1.0 else 1280,filter_size=1,stride=1,padding=0,if_act=True)feature = fluid.layers.pool2d(input=input,pool_size=7,pool_stride=1,pool_type='avg',global_pooling=True)net = fluid.layers.fc(input=feature,size=class_dim,act='softmax')return net
创建一个train.py开始训练。首先导入相关的依赖包。
import paddle as paddle
import paddle.dataset.cifar as cifar
import paddle.fluid as fluid
import mobilenet_v2
from visualdl import LogWriter
创建VisualDL的记录器,通过这个记录器可以记录每次训练的数据,并存储在log/目录下。
# 创建记录器
log_writer = LogWriter(dir='log/', sync_cycle=10)# 创建训练和测试记录数据工具
with log_writer.mode('train') as writer:train_cost_writer = writer.scalar('cost')train_acc_writer = writer.scalar('accuracy')histogram = writer.histogram('histogram', num_buckets=50)with log_writer.mode('test') as writer:test_cost_writer = writer.scalar('cost')test_acc_writer = writer.scalar('accuracy')
这里是定义一系列的操作,如定义输入层,获取MobileNet V2的分类器,克隆预测程序,定义优化方法。
# 定义输入层
image = fluid.layers.data(name='image', shape=[3, 32, 32], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')# 获取分类器
model = mobilenet_v2.net(image, 10)# 获取损失函数和准确率函数
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=model, label=label)# 获取训练和测试程序
test_program = fluid.default_main_program().clone(for_test=True)# 定义优化方法
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=1e-3)
opts = optimizer.minimize(avg_cost)
获取CIFAR的训练数据和测试数据,并创建一个执行器,MobileNet V2这个模型虽然使用在手机上的,但是在训练起来却不是那么快,最好使用GPU进行训练,要不是相当的慢。
# 获取CIFAR数据
train_reader = paddle.batch(cifar.train10(), batch_size=32)
test_reader = paddle.batch(cifar.test10(), batch_size=32)# 定义一个使用CPU的执行器
place = fluid.CUDAPlace(0)
# place = fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())# 定义输入数据维度
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
这里从初始化程序中获取全部参数的名称,用于之后训练过程中输出参数的值,并记录到VisualDL中。
# 定义日志的开始位置和获取参数名称
train_step = 0
test_step = 0
params_name = fluid.default_startup_program().global_block().all_parameters()[0].name
开始训练模型,在训练过程中,把训练时的损失值保存到train_cost_writer中,把训练时的准确率保存到train_acc_writer中,把训练过程中的参数变化保存到histogram中。把测试时的损失值保存到test_cost_writer中,把测试时的准确率保存到test_acc_writer中。
# 训练10次
for pass_id in range(10):# 进行训练for batch_id, data in enumerate(train_reader()):train_cost, train_acc, params = exe.run(program=fluid.default_main_program(),feed=feeder.feed(data),fetch_list=[avg_cost, acc, params_name])# 保存训练的日志数据train_step += 1train_cost_writer.add_record(train_step, train_cost[0])train_acc_writer.add_record(train_step, train_acc[0])histogram.add_record(train_step, params.flatten())# 每100个batch打印一次信息if batch_id % 100 == 0:print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %(pass_id, batch_id, train_cost[0], train_acc[0]))# 进行测试test_accs = []test_costs = []for batch_id, data in enumerate(test_reader()):test_cost, test_acc = exe.run(program=test_program,feed=feeder.feed(data),fetch_list=[avg_cost, acc])# 保存测试的日志数据test_step += 1test_cost_writer.add_record(test_step, test_cost[0])test_acc_writer.add_record(test_step, test_acc[0])test_accs.append(test_acc[0])test_costs.append(test_cost[0])# 求测试结果的平均值test_cost = (sum(test_costs) / len(test_costs))test_acc = (sum(test_accs) / len(test_accs))print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
训练时输出的信息:
Pass:0, Batch:0, Cost:2.79566, Accuracy:0.03125
Pass:0, Batch:100, Cost:2.48199, Accuracy:0.15625
Pass:0, Batch:200, Cost:2.49757, Accuracy:0.18750
Pass:0, Batch:300, Cost:2.10605, Accuracy:0.28125
Pass:0, Batch:400, Cost:2.24151, Accuracy:0.15625
Pass:0, Batch:500, Cost:1.99807, Accuracy:0.21875
Pass:0, Batch:600, Cost:1.92178, Accuracy:0.34375
Pass:0, Batch:700, Cost:1.81583, Accuracy:0.28125
Pass:0, Batch:800, Cost:2.22559, Accuracy:0.25000
Pass:0, Batch:900, Cost:1.79611, Accuracy:0.34375
Pass:0, Batch:1000, Cost:2.00520, Accuracy:0.25000
训练结束之后,启动VisualDL工具,指定日志文件的目录和端口号。
visualdl --logdir=log/ --port=8080
访问网页地址:http://localhost:8080/,我们会得到以下的图片。
-
训练时的准确率和损失值的变化,从这些图片可以看到模型正在收敛,准确率在不断提升。

-
下图是使用测试集的准确率和损失值,从图中可以看出后期的测试情况准确率在下降,损失值在增大,也对比上图训练的准确率还在上升,证明模型出现过拟合的情况。

-
下图是训练是参数的histogram图,从图中可以看出参数正在趋于稳定,同时的没有出现异常值,如极大值或者极小值。
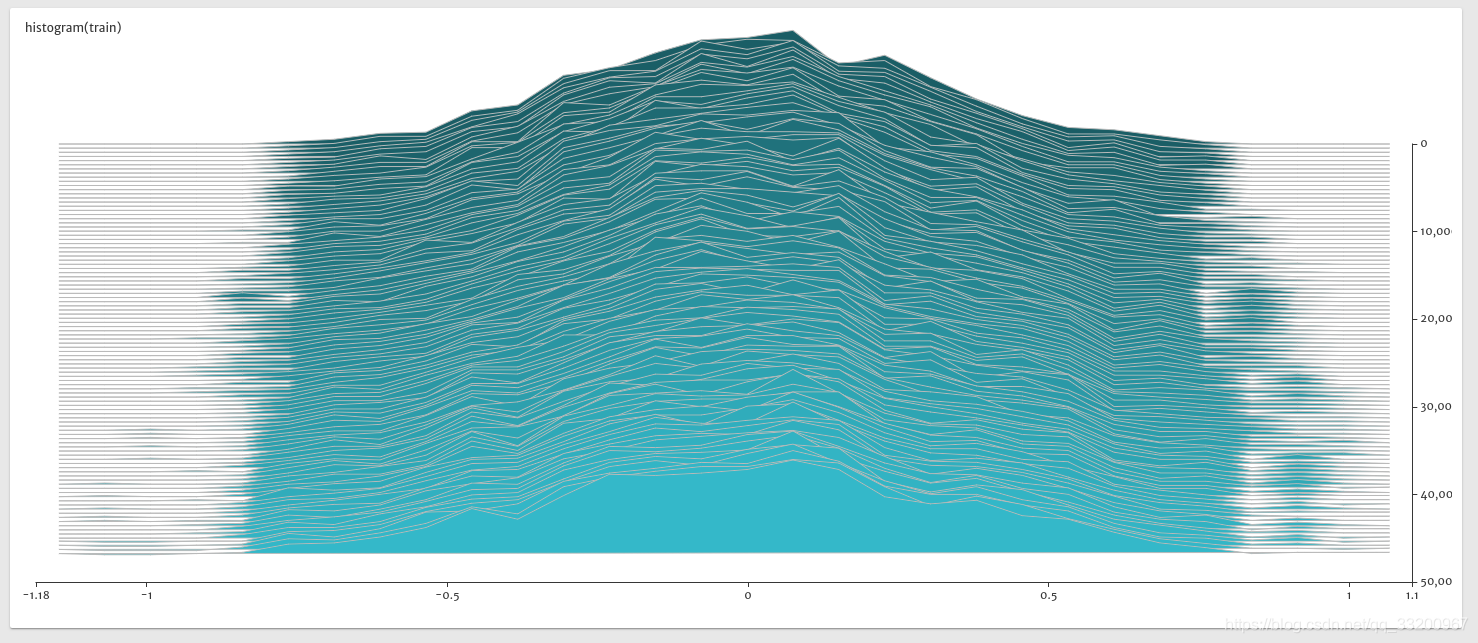
本章关于VisualDL的使用就介绍到这里,读者在实际开发中可以使用VisualDL,通过利用VisualDL给予的训练可视化,不断优化模型。
同步到百度AI Studio平台:https://aistudio.baidu.com/aistudio/projectDetail/38856
同步到科赛网K-Lab平台:https://www.kesci.com/home/project/5c3f495589f4aa002b845d6b
项目代码GitHub地址:https://github.com/yeyupiaoling/LearnPaddle2/tree/master/note10
注意: 最新代码以GitHub上的为准
上一章:《PaddlePaddle从入门到炼丹》九——迁移学习
下一章:《PaddlePaddle从入门到炼丹》十一——自定义图像数据集识别
参考资料
- https://blog.csdn.net/qq_33200967/article/details/79127175
- https://github.com/PaddlePaddle/VisualDL
- https://www.jianshu.com/p/4c9404d4998c
这篇关于《PaddlePaddle从入门到炼丹》十——VisualDL 训练可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







