本文主要是介绍Django 尝试SSE报错 AssertionError: Hop-by-hop headers not allowed 的分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
情况描述
近期计划测试一下django对日志打印的支持,一般都是用websocket的方式,想测试一下SSE (Server-sent events)的服务端推送,发现过程中存在报错:
Traceback (most recent call last):File "D:\Software\Anaconda3\lib\wsgiref\handlers.py", line 137, in runself.result = application(self.environ, self.start_response)File "D:\IDE Projects\Music\venv\lib\site-packages\django\contrib\staticfiles\handlers.py", line 76, in __call__return self.application(environ, start_response)File "D:\IDE Projects\Music\venv\lib\site-packages\django\core\handlers\wsgi.py", line 142, in __call__start_response(status, response_headers)File "D:\Software\Anaconda3\lib\wsgiref\handlers.py", line 249, in start_responseassert not is_hop_by_hop(name),"Hop-by-hop headers not allowed"
AssertionError: Hop-by-hop headers not allowed
部分代码
response = HttpResponse(content_type='text/event-stream')response['Cache-Control'] = 'no-cache'# AssertionError: Hop-by-hop headers not allowedresponse['Connection'] = 'keep-alive'response['Transfer-Encoding'] = 'chunked'
初步分析
1)报错大致是说Hop-by-hop headers not allowed ,说是HTTP1.0 不支持这个头部
HTTP 首部字段将定义成缓存代理和非缓存代理的行为,分成 2 种类型。
端到端首部(End-to-end Header)
分在此类别中的首部会转发给请求 / 响应对应的最终接收目标,且必须保存在由缓存生成的响应中,另外规 定它必须被转发。
逐跳首部(Hop-by-hop Header)
分在此类别中的首部只对单次转发有效,会因通过缓存或代理而不再转发。HTTP/1.1 和之后版本中,如果要使用 hop-by-hop 首部,需提供 Connection 首部字段。
2)依据堆栈信息,找到对应的判断函数 is_hop_by_hop(name) ,只要头部存在如下的集合元素,就会被判定为 hop_by_hop
# wsgiref\handlers.pyif __debug__:for name, val in headers:name = self._convert_string_type(name, "Header name")val = self._convert_string_type(val, "Header value")assert not is_hop_by_hop(name),"Hop-by-hop headers not allowed"# handlers\wsgi.py
_hoppish = {'connection':1, 'keep-alive':1, 'proxy-authenticate':1,'proxy-authorization':1, 'te':1, 'trailers':1, 'transfer-encoding':1,'upgrade':1
}.__contains__def is_hop_by_hop(header_name):"""Return true if 'header_name' is an HTTP/1.1 "Hop-by-Hop" header"""return _hoppish(header_name.lower())
3)于是乎,我把Connection 和 Transfer-Encoding 注释掉,就正常了
附带SSE 在django的使用办法
(一)前端 HTML 部分代码
<p id="info">测试</p><script>var need_close = false;var eventSource = new EventSource('/sse');info_elm = document.getElementById("info");// 开启连接的监听// 解决重复请求(默认会无限重连) 也可以由后端内容决定是否关闭eventSource.onopen = function(){if (need_close){eventSource.close();}need_close = true;};// 收到事件的监听eventSource.onmessage = function(event) {// 处理接收到的事件数据info_elm.innerText = info_elm.innerText + event.data + '\n';};</script>
(二)django
### views.py
from django.http import StreamingHttpResponsedef sse(request):def event_stream():# 测试读取当前文件with open('appname/views.py', encoding='utf-8') as file:for line in file:# time.sleep(1)yield f'data: {line}\n\n'return StreamingHttpResponse(event_stream(), content_type='text/event-stream', headers={'Cache-Control':'no-cache'})def hello(request):return render(request, 'sse.html' )### urls.py
urlpatterns = [path('sse', views.sse),path('hello', views.hello),
]
(三) 结果
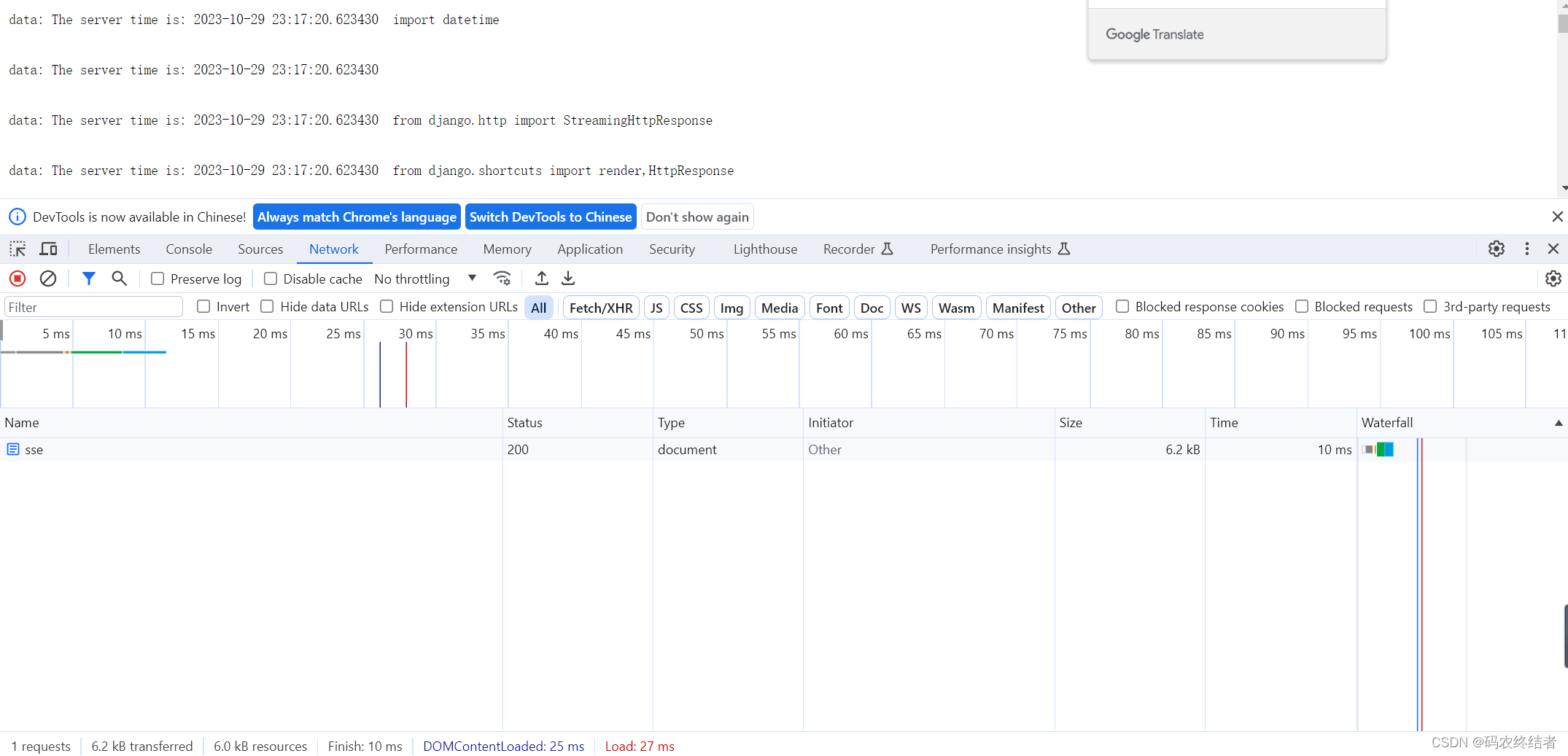
http://127.0.0.1:8000/sse
能看到只有一个请求,内容是逐步刷新出来的
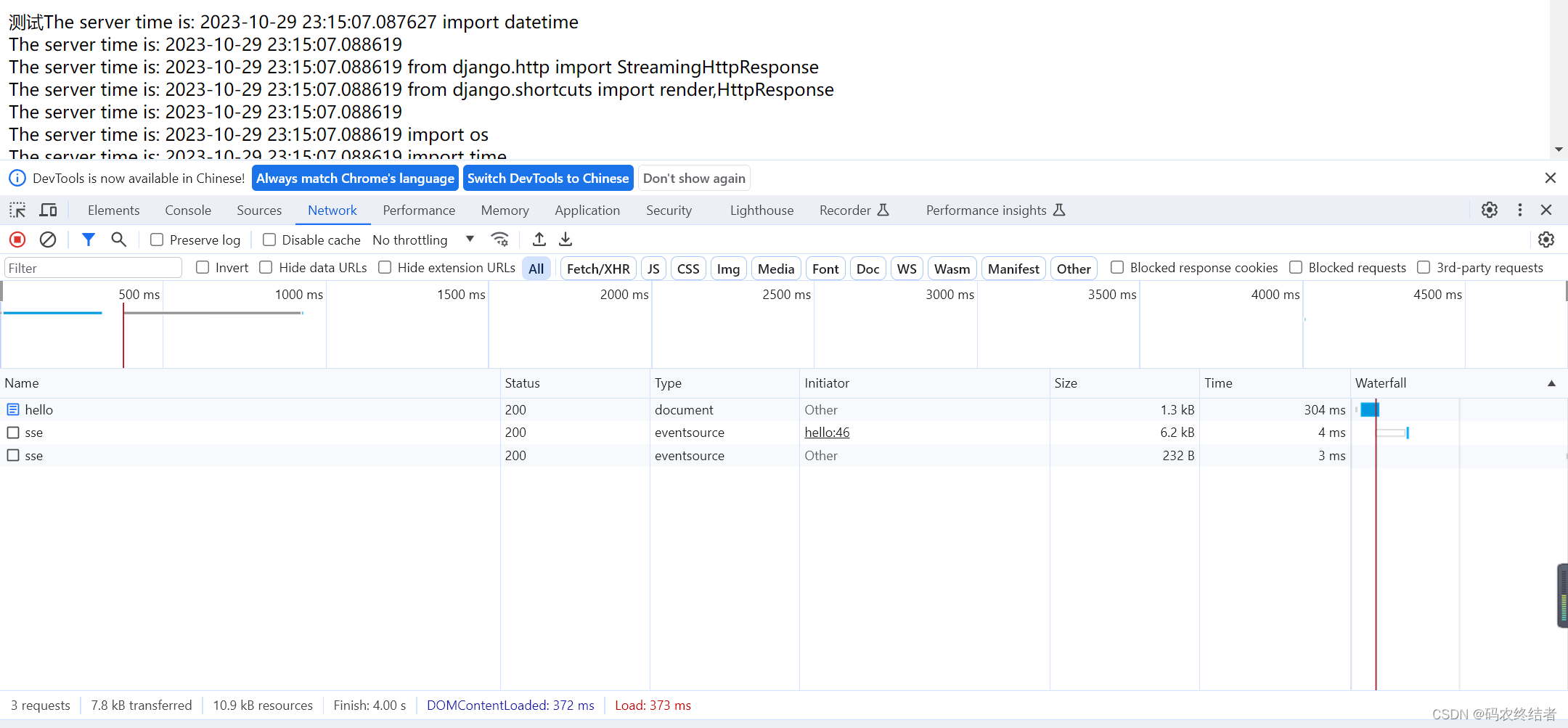
http://127.0.0.1:8000/hello
能看到有三个请求,第二个是SSE请求,结束后,EventSource自动拉起了第三个请求,由于在onopen 配置了变量控制,所以后期不会有新的推送进来导致数据重复载入前端
(四) 不可行方案
如下方案主要是 response.flush() 并不能把数据刷新到客户端,所以这个与直接返回结果没太大区别,也可能是我目前使用方式不对或理解没到位。
官方文档: response.flush() 这个方法使一个 HttpResponse 实例成为一个类似文件的对象
def sse(request):response = HttpResponse( content_type='text/event-stream')response['Cache-Control'] = 'no-cache'for i in range(5):response.write(f'data:{i} \n\n')response.write('id: {i} ')response.write(f'message: {datetime.datetime.now()}')response.write('event: 发送数据')# 数据发送到客户端response.flush()time.sleep(1)return response
总结
1、发现网上很多给的代码都跑不起来,要么不和预期,终究还是得找官方
2、尝试看看源码,可能能找到问题原因还有一些没接触过的写法
3、可以用while True ,然后将数据读取写入到循环内部,然后通过控制时间间隔来减少推送
参考链接:
HTTP 首部字段详细介绍
Python __debug__内置变量的用法
SSE介绍
W3shcool SSE
关于SSE关闭的问题
EventSource专题
这篇关于Django 尝试SSE报错 AssertionError: Hop-by-hop headers not allowed 的分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






