在上一篇51job职位信息的爬取中,对岗位信息div下各式各样杂乱的标签,简单的Xpath效果不佳,加上string()函数后,也不尽如人意。因此这次我们跳过桌面web端,选择移动端进行爬取。
一、代码结构
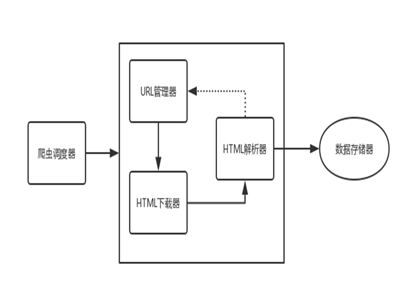
按照下图所示的爬虫基本框架结构,我将此份代码分为四个模块——URL管理、HTML下载、HTML解析以及数据存储。
二、URL管理模块
这个模块负责搜索框关键词与对应页面URL的生成,以及搜索结果不同页数的管理。首先观察某字段(大数据, UTF-8为'E5A4A7 E695B0 E68DAE') 全国范围内的结果,前三页结果的URL如下:
URL前半部分:

这部分中我们可以看到两处处不同,第一处为编码后'2,?.html'中间的数字,这是页数。另一处为参数stype的值,除第一页为空之外,其余都为1。另外,URL中有一连串的数字,这些是搜索条件,如地区、行业等,在这儿我没有用上。后面的一连串字符则为搜索关键词的字符编码。值得注意的是,有些符号在URL中是不能直接传输的,如果需要传输的话,就需要对它们进行编码。编码的格式为'%'加上该字符的ASCII码。因此在该URL中,%25即为符号'%'。
URL后半部分:

后半部分很明显的就能出首页与后面页面的URL参数相差很大,非首页的URL后半部分相同。
因此我们需要对某关键字的搜索结果页面分两次处理,第一次处理首页,第二次可使用循环处理后续的页面。
- if __name__ == '__main__':
- key = '数据开发'
- # 第一页
- url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'+key+',2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
- getUrl(url)
- # 后页[2,100)
- urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,'+key+',2,{}.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(i) for i in range(2,30)]
- for url in urls:
- getUrl(url)
三、HTML下载模块
下载HTMl页面分为两个部分,其一为下载搜索结果某一页的HTML页面,另一部分为下载某一岗位具体页面。由于页面中具体岗位URL需要从搜索结果页面中获取,所以将下载搜索结果页面及获取具体岗位URL放入一个函数中,在提取到具体岗位URL后,将其传入至另一函数中。
3.1搜索结果页面下载与解析
下载页面使用的是requests库的get()方法,得到页面文本后,通过lxml库的etree将其解析为树状结构,再通过Xpath提取我们想要的信息。在搜索结果页面中,我们需要的是具体岗位的URL,打开开发者选项,找到岗位名称。

我们需要的是<a>标签里的href属性。右键,复制——Xpath,得到该属性的路径。
- //*[@id="resultList"]/div/p/span/a/@href
由于xpath返回值为一个列表,所以通过一个循环,将列表内URL依次传入下一函数。
- def getUrl(url):
- print('New page')
- res = requests.get(url)
- res.encoding = 'GBK'
- if res.status_code == requests.codes.ok:
- selector = etree.HTML(res.text)
- urls = selector.xpath('//*[@id="resultList"]/div/p/span/a/@href')
- # //*[@id="resultList"]/div/p/span/a
- for url in urls:
- parseInfo(url)
- time.sleep(random.randrange(1, 4))
3.2具体岗位信息页面下载
该函数接收一个具体岗位信息的参数。由于我们需要对移动端网页进行处理,所以在发送请求时需要进行一定的伪装。通过设置headers,使用手机浏览器的用户代理,再调用get()方法。
- def parseInfo(url):
- headers = {
- 'User-Agent': 'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/ADR-1301071546) Presto/2.11.355 Version/12.10'
- }
- res = requests.get(url, headers=headers)
四、HTML解析模块
在3.2中,我们已经得到了岗位信息的移动端网页源码,因此再将其转为etree树结构,调用Xpath即可得到我们想要的信息。
需要注意的是页面里岗位职责div里,所有相关信息都在一个<article>标签下,而不同页面的<article>下层标签并不相同,所以需要将该标签下所有文字都取出,此处用上了string()函数。
- selector = etree.HTML(res.text)
- title = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/p/text()')
- salary = selector.xpath('//*[@id="pageContent"]/div[1]/p/text()')
- company = selector.xpath('//*[@id="pageContent"]/div[2]/a[1]/p/text()')
- companyinfo = selector.xpath('//*[@id="pageContent"]/div[2]/a[1]/div/text()')
- companyplace = selector.xpath('//*[@id="pageContent"]/div[2]/a[2]/span/text()')
- place = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/em/text()')
- exp = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[2]/text()')
- edu = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[3]/text()')
- num = selector.xpath('//*[@id="pageContent"]/div[1]/div[2]/span[1]/text()')
- time = selector.xpath('//*[@id="pageContent"]/div[1]/div[1]/span/text()')
- info = selector.xpath('string(//*[@id="pageContent"]/div[3]/div[2]/article)')
- info = str(info).strip()
五、数据存储模块
首先创建.csv文件,将不同列名称写入首行。
- fp = open('51job.csv','wt',newline='',encoding='GBK',errors='ignore')
- writer = csv.writer(fp)
- writer.writerow(('职位','薪资','公司','公司信息','公司地址','地区','工作经验','学历','人数','时间','岗位信息'))
再在解析某一页面数据后,将数据按行写入.csv文件。
- writer.writerow((title,salary,company,companyinfo,companyplace,place,exp,edu,num,time,info))
源码:爬取51job移动端源码(12月)
相关:智联招聘源码分析
贪吃蛇链表实现及部分模块优化




