本文主要是介绍mysql嵌套循环+半连接_SQL调优之四:嵌套循环连接(Nested Loops Joins),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
嵌套循环连接
嵌套循环连接一个外部数据集到内部数据集中,针对外部数据集的每一行数据,数据库会去匹配内部数据集中所有匹配谓词条件的行。如果这个时候内部数据集或者内部表有索引可用,那么数据库就会通过使用它来定位rowid来获取数据。
优化器什么时候考虑使用嵌套循环连接?
一般来说,嵌套循环连接在小表之间,并且连接条件是带有索引的情况下是最适用的。如果一个数据集只有一行数据,比如说主键列上的等式查询(exployee_id=101),那么这个链接就是一个简单查询。优化器会试着把最小的数据集放在前面,用它来做驱动表。
另一方面,优化器所收到的不同因素会决定它是否要使用嵌套循环连接。
比方说,在一次批处理的过程中,数据库会先从外部数据集中获取一些行,然后根据获取的数据集大小,优化器会决定是使用嵌套循环方式还是哈希连接方式来连接内部数据集。比如,当一次查询连接departments和employees表的时候,如果谓词条件指定的是employees表last_name这一列的值,那么数据库会在last_name上的索引读取足够的记录来判断数据集是否已经超过了一个内部阈值,如果没有超过,那么就使用嵌套循环连接来连接departments表,如果超过了,则使用hash join方式,也就是说会把剩下的内容hash到内存中,然后再来连接departments表。
另外,如果获取数据的方式(access path)不依赖于外部数据集的循环,那么这个结果可能是笛卡尔结果,也就是外部循环的每一次迭代,内部表都会产生同样的行集。可以使用其他的连接方式来连接两个独立的数据集来避免这种情况。
嵌套循环连接的工作方式
理论上来说,嵌套循环连接等于两个嵌套的循环,比如说employees表和departments表之间的嵌套循环连接,可以看成是:
FOR erow IN (select * from employees where X=Y) LOOP
FOR drow IN (select * from departments where erow is matched) LOOP
output values from erow and drow
END LOOP
END LOOP
可以看出,外部数据集的每一行,都会进行一次内部数据集的循环匹配。在这个例子里,employees表就是外部数据,因为它在外部的循环里,针对它的每一行,内部的departments表都要扫描一遍进行匹配。
一次嵌套循环连接涉及以下基础步骤:
1,优化器确定外部表(数据集)
外部循环会产生一个数据集来驱动连接条件。这个数据集可以通过使用索引范围扫描,全表扫描等方式从表里生成。
内循环的迭代次数是基于外部数据集的行数的。比如说,如果外部数据集有10行,那么内部表就要循环10次。
2,优化器生成其他数据集用于内部循环
在执行计划中,外部循环会在内部循环的上面
NESTED LOOPS
outer_loop
inner_loop
3,对于每一个从客户端发来的提取请求,基本的流程是:
a, 从外部数据集获取一行数据
b,探查内部数据集,找到匹配谓词的行集
c,重复以上的过程,知道所有满足该请求的行都被提取出来
有些时候,数据库会对ROWID进行排序,以期得到更有效读取缓存的模式
嵌套嵌套循环(二次嵌套)
例子:
SELECT /*+ ORDERED USE_NL(d) */ e.last_name, e.first_name, d.department_name
FROM employees e, departments d
WHERE e.department_id=d.department_id
AND e.last_name like 'A%';
这一条SQL只有一次连接,但有两次嵌套循环,执行计划是:
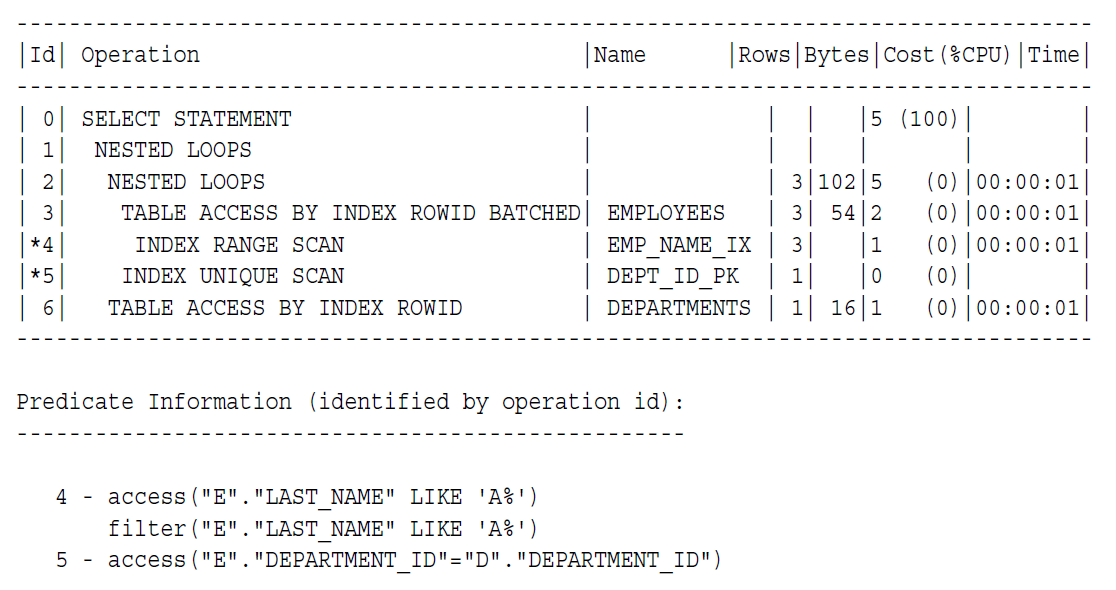
它的基本流程是:
1, 数据库开始迭代里面的那个嵌套循环(第2步):
a. 数据库搜索emp_name_ix,获取last_name以A开头的rowid(4)
比如:
Abel,employees_rowid
Ande,employees_rowid
Atkinson,employees_rowid
Austin,employees_rowid
b. 使用上一步获取的rowid,数据库数据库从employees表批量获取行数据(3):
Abel,Ellen,80
Abel,John,50
这些获取的行集就是最里面的嵌套循环的外部数据集。
批处理的这一步是自适应执行计划里面非常典型的部分。为了判断嵌套循环是否比哈希连接更好,优化器需要确定从行源返回的数目。
如果返回的行太多,那么优化器就会切换成另一种不同的连接方式。
c. 对于外部数据集返回的每一行,数据库扫描dept_id_pk索引来获取departments表中匹配条件的rowid(5)。并且和employees表的行连接起来。
比如:
Abel,Ellen,80,departments_rowid
Ande,Sundar,80,departments_rowid
Atkinson,Mozhe,50,departments_rowid
Austin,David,60,departments_rowid
这些数据会变成外部嵌套循环里面的外部数据集 (1)。
2. 接着,数据库迭代外部表的方式是:
a. 数据库读取外部行源的第一行
比如:
Abel,Ellen,80,departments_rowid
b. 数据库使用departments的rowid来从departments表中获取相对应的行数据(6)。然后把结果连接起来,获得请求的数据。(1)
比如:
Abel,Ellen,80,Sales
c. 数据库读取外部行源的下一行,使用departments的rowid获取相对应的行数据(6),然后迭代循环,直到所有的结果被返回。
Abel,Ellen,80,Sales
Ande,Sundar,80,Sales
Atkinson,Mozhe,50,Shipping
Austin,David,60,IT
PS:这些中间产生的行数据集,会缓存在PGA中
目前的嵌套循环连接的实现方法
oracle11g的时候介绍了一种新的嵌套循环的实现方法。当一个索引或者一个表的数据块不在缓存里面的时候,如果这个块需要被用来做连接,那么就会发生一次物理的I/O。
在这种情况下,数据库可以批处理多个物理I/O请求,并且使用矢量I/O(数组)的方式来处理他们。而不是一次只处理一个物理I/O。数据库会发送一组rowid到操作系统,然后操作系统再进行读取操作。
作为新的实现方法的一部分,以前只会出现一次嵌套循环的执行计划,现在可能会出现两次了。在这种情况下,嵌套循环里面,是先和索引的rowid进行连接匹配,然后带有rowid的结果,再和表进行第二次嵌套循环,来获取实际值。
在某些情况下,数据库不会做二次嵌套循环:
所有需要的列都在索引里面了,并且不需要在访问表。
返回的行的顺序可能和早期版本的不一样。因此,当Oracle要尝试着保留一个特定的顺序的时候,比如说ORDER BY。Oracle数据库可能会使用原先的实现方法,即只有一次嵌套循环。
OPTIMIZER_FEATURES_ENABLE初始化参数设定成了11g以前的版本。
放一张原本的执行计划,你会看到第二步的时候获取了相对应的数据后(还是包含了rowid,因为用了索引),它在ID1这一步是通过TABLE ACCESS BY INDEX ROWID的方式来获取数据,那么它每次就只能读一个rowid去获取数据。
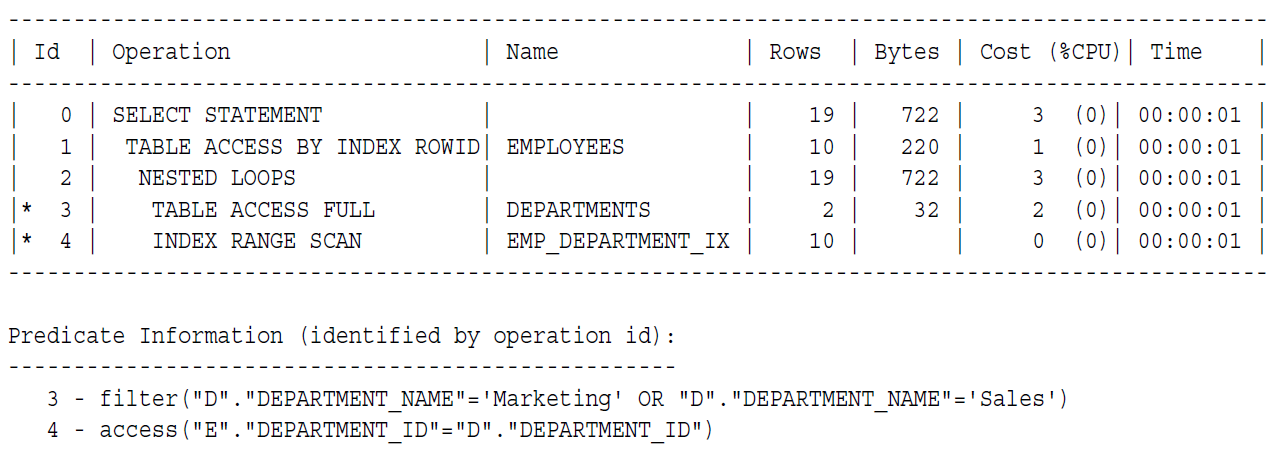
嵌套循环控制
某些情况下,你可能需要使用USE_NL来强制使用嵌套循环连接,或者USE_NL_WITH_INDEX(table index),带索引的,如果没有指定索引,则会自动使用谓词里面的至少一个索引。
这篇关于mysql嵌套循环+半连接_SQL调优之四:嵌套循环连接(Nested Loops Joins)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








