本文主要是介绍2023.8DataWhale_cv夏令营第三期笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
背景描述
任务一:跑通BaseLine,快速入门
1.1赛题内容简介
1.2nii格式数据介绍
1.3官方代码展示与解析
1.4笔者的想法
1.4.1增加提取的信息特征
1.4.2 增加最大迭代次数
1.4.3修改算法模型
任务二:CNN深度学习
概述
2.1CNN卷积神经网络
2.1.1流程介绍
2.1.2卷积层
2.1.3激活层
2.1.4池化层
2.1.5网络架构
2.1.6网络训练
2.2基于ResNet18项目代码解析
2.2.1包和模块导入
2.2.2自定义数据加载器
2.2.3模型定义
2.2.4训练与验证
2.2.5预测并保存结果
2.3一些问题与解决办法
2.3.1包、模块缺失
2.3.2 多线程运行错误
2.3.3路径分隔错误
2.4 一些想法和尝试
2.4.1增加迭代次数
2.4.2数据增强
2.4.3提升预测轮数
2.4.4一些并未尝试的想法
任务三:进阶提升准确率
概述:
3.1更换预训练模型
3.1.1ResNet34
3.1.2ResNet50
3.2数据增强
3.2.1使用模糊和随机变换
3.3使用jpg训练
3.3.1nii2jpg
3.3.2训练集、验证集划分
3.3.3数据准备
3.3.4结果预测
背景描述
由于笔者正在参加DataWhale举办的cv夏令营,同时围绕脑PET图像分析和疾病预测挑战赛进行先关的人工智能学习,因此以下内容为笔者学习过程中的一些思考与感悟,包含一些疑惑和不理解的地方通过查阅资料得到的结果。
任务一:跑通BaseLine,快速入门
1.1赛题内容简介
使用官方提供的脑PET数据集,构建逻辑回归模型来进行脑PET图像的疾病预测,数据集被分为两类,分别为轻度认知障碍(MCI)患者的脑部影像数据和健康人(NC)的脑部影像数据,图像数据格式为nii,因此本赛题可抽象为一个二分类问题。
1.2nii格式数据介绍
nii是一种常用的医学图像数据格式,主要用于存储和交换神经影像数据。以下是一些主要特点:
1.主要用于存储3D(三维)医学图像数据,如MRI(磁共振成像)和CT(计算机断层扫描)图像。
2.支持多种数据类型,使得其可以支持不同类型的数据处理和分析
3.允许在头文件中添加元数据,如病人信息、扫描参数等。这些元数据可以提供有关图像的更多上下文信息,以便于后续的分析和解释,这点也会在后续的学习中得到体现。
1.3官方代码展示与解析
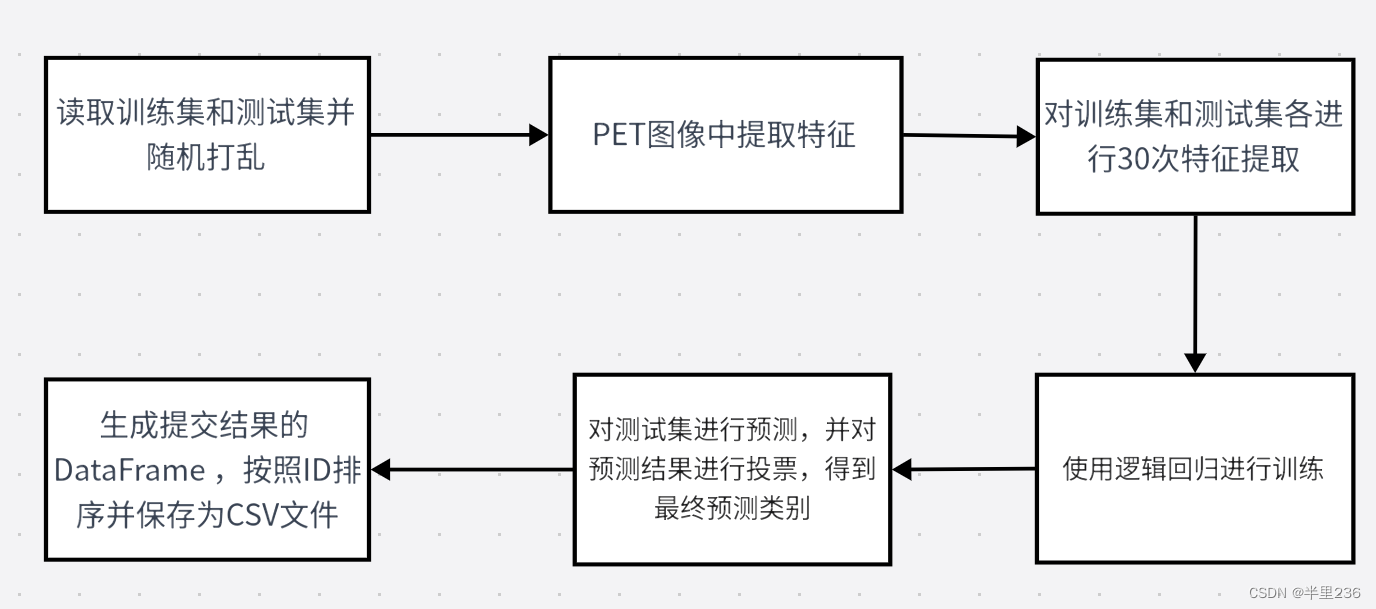
上面是官方给出的流程图
import glob # 获取文件路径
import numpy as np
import pandas as pd
import nibabel as nib # 处理医学图像数据
from nibabel.viewers import OrthoSlicer3D # 图像可视化
from collections import Counter # 计数统计
第一步不必多说,自然是导入所需要使用的各个库。其中nibabel是专门用来处理医学图像数据的模块,值得一提的是OrthoSlicer3D模块可以用于在训练过程中展示脑图的三维切片图像,但在本次代码中以笔者之见不是必须的。
# 读取训练集文件路径
train_path = glob.glob('./脑PET图像分析和疾病预测挑战赛公开数据/Train/*/*')
test_path = glob.glob('./脑PET图像分析和疾病预测挑战赛公开数据/Test/*')# 打乱训练集和测试集的顺序
np.random.shuffle(train_path)
np.random.shuffle(test_path)第二步,读取数据集的文件路径,并打乱训练集和测试集的顺序。此处打乱数据集的顺序,目的是为了防止模型对数据的顺序产生依赖性,同时提高模型的泛化能力和鲁棒性。
# 对PET文件提取特征
def extract_feature(path):# 加载PET图像数据img = nib.load(path)# 获取第一个通道的数据img = img.dataobj[:, :, :, 0]# 随机筛选其中的10个通道提取特征random_img = img[:, :, np.random.choice(range(img.shape[2]), 10)]# 对图片计算统计值feat = [(random_img != 0).sum(), # 非零像素的数量(random_img == 0).sum(), # 零像素的数量random_img.mean(), # 平均值random_img.std(), # 标准差len(np.where(random_img.mean(0))[0]), # 在列方向上平均值不为零的数量len(np.where(random_img.mean(1))[0]), # 在行方向上平均值不为零的数量random_img.mean(0).max(), # 列方向上的最大平均值random_img.mean(1).max() # 行方向上的最大平均值]# 根据路径判断样本类别('NC'表示正常,'MCI'表示异常)if 'NC' in path:return feat + ['NC']else:return feat + ['MCI']第三步,提取图像特征。特征部分采用:通过计算每个通道的非零像素数量、零像素数量、平均值、标准差以及在行、列方向上平均值不为零的数量等特征,提取出图像的一些基本统计信息。值得注意的是最后一步将样本的类别名加入feat列表作为特征,这一步很巧妙。
# 对训练集进行30次特征提取,每次提取后的特征以及类别('NC'表示正常,'MCI'表示异常)被添加到train_feat列表中。
train_feat = []
for _ in range(30):for path in train_path:train_feat.append(extract_feature(path))# 对测试集进行30次特征提取
test_feat = []
for _ in range(30):for path in test_path:test_feat.append(extract_feature(path))第四步,对训练集和测试集分别进行了30次的特征提取。
# 使用训练集的特征作为输入,训练集的类别作为输出,对逻辑回归模型进行训练。
from sklearn.linear_model import LogisticRegression
m = LogisticRegression(max_iter=1000)
m.fit(np.array(train_feat)[:, :-1].astype(np.float32), # 特征np.array(train_feat)[:, -1] # 类别
)
第五步,使用逻辑回归进行训练。此处导入了在机器学习中常用的sklearn的逻辑回归模块,将最大迭代次数设置为1000,即训练1000轮,在这过程中模型将尝试优化参数。
# 对测试集进行预测并进行转置操作,使得每个样本有30次预测结果。
test_pred = m.predict(np.array(test_feat)[:, :-1].astype(np.float32))
test_pred = test_pred.reshape(30, -1).T# 对每个样本的30次预测结果进行投票,选出最多的类别作为该样本的最终预测类别,存储在test_pred_label列表中。
test_pred_label = [Counter(x).most_common(1)[0][0] for x in test_pred]第六步,对测试集进行预测并投票,得到最后的类别。
# 生成提交结果的DataFrame,其中包括样本ID和预测类别。
submit = pd.DataFrame({'uuid': [int(x.split('/')[-1][:-4]) for x in test_path], # 提取测试集文件名中的ID'label': test_pred_label # 预测的类别}
)# 按照ID对结果排序并保存为CSV文件
submit = submit.sort_values(by='uuid')
submit.to_csv('submit1.csv', index=None)第七步,生成提交结果的DataFrame,并按id排序得到最终的提交结果。结果显示f_score为0.48485。
1.4笔者的想法
1.4.1增加提取的信息特征
在1.3中的第三步,我们讲述了图像特征提取部分的内容,其中提取到的都是一些图像的基本统计信息,除了这些信息以外,我们还可以尝试提取别的信息来尝试提高模型的准确率。如形状特征、稀疏编码特征、图像纹理特征、对比度特征等。但是笔者水平有限,没有办法做到,希望有能力的同学可以尝试相关方法。
1.4.2 增加最大迭代次数
同时对于1.3中第五步的最大迭代次数也可以进行调整,不同的迭代次数得到的训练结果自然不同。笔者尝试了将最大迭代次数修改为1250后,得到结果为0.5,显然得到提高
1.4.3修改算法模型
此外,在1.3中第五步,我们使用的是逻辑回归模型,但是我们可以使用其他模型进行训练,也许得到的效果会更好,如:决策树、k近邻算法、CNN卷积神经网路等。笔者尝试了使用k近邻算法,修改代码部分为1.3中第五步:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
train_data = np.array(train_feat)[:, :-1].astype(np.float32)
train_labels = np.array(train_feat)[:, -1]
k = 3 # 设置 k 的值
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(train_data, train_labels)最终得到的结果为0.44211,当然算法中参数k值的选取也与结果有关,由于每天只能提交三次结果因此无法实验更多次得到较好的参数值。
任务二:CNN深度学习
概述
任务二主要使用卷积神经网络(Convolutional Neural Network,CNN)来对脑PET图像进行分析与疾病预测。官方给出了两种方案,一种是基于飞桨套件实现的PPHGNet,一种是基于pytorch实现的ResNet18。笔者将二者全部跑了一遍,PPHGNet实现的结果分数为0.57426,而ResNet18则达到了0.69444。
由于对飞桨套件使用不是很熟悉,本文主要分为CNN学习心得、源代码详解、一些问题与解决方案、心得体会四部分。如果对PPHGNet感兴趣可以点击下方链接进行学习。基于PaddleClas套件的脑PET图像分析和疾病预测挑战赛-baseline - 飞桨AI Studio (baidu.com)
2.1CNN卷积神经网络
2.1.1流程介绍
CNN卷积神经网络主要是通过卷积、非线性函数激活、池化来进行下采样,提取图像特征,最后经过全连接层进行分类或者回归任务。
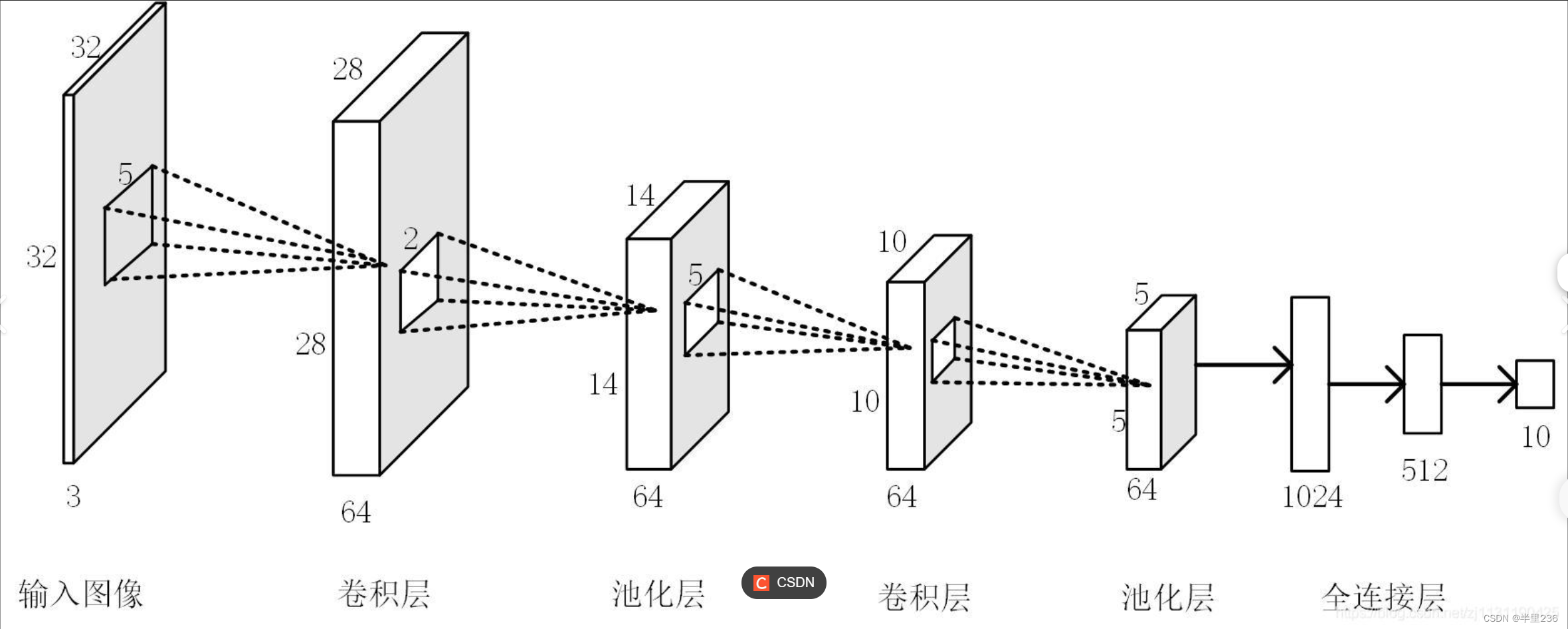
2.1.2卷积层
卷积层使用卷积核在输入数据上进行卷积操作,从而提取局部特征。卷积运算的过程为使用卷积核一般是3*3大小的数字矩阵在输入数据上进行平扫,计算规则为对应数据相乘求和得到中心位置像素值,卷积操作结束后的输出图像即为特征图(feature map)。
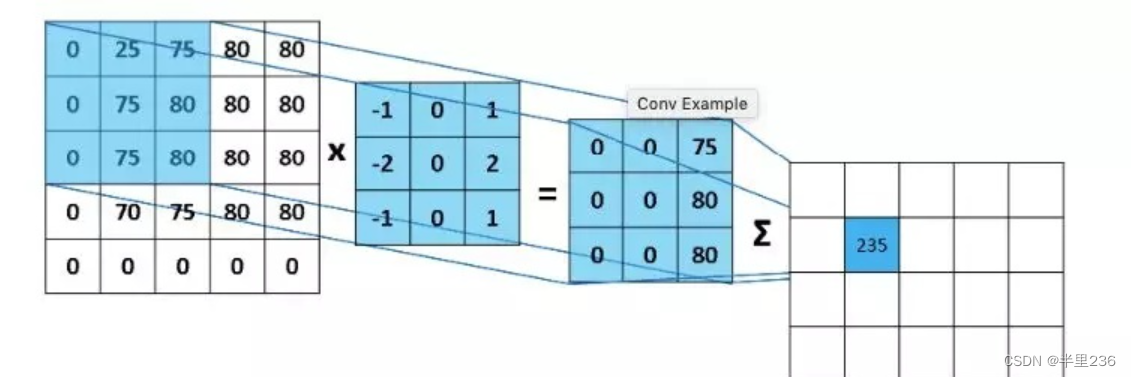
卷积操作过程中通过设定kernel_size(卷积核大小),stride(步长),padding(填充值),out_channels(输出通道数)来决定特征图的尺寸大小和通道数。计算规则如下(w为图像的长或宽,f为卷积核大小):
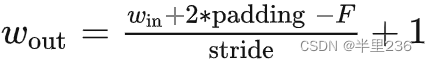
2.1.3激活层
激活层使用非线性函数对被卷积后的特征图进行处理。主要目的是为了向神经网路中引入非线性元素,提升网络的拟合能力。此外,激活层的引入还能有效的解决梯度爆炸和梯度消失的问题,提高模型训练的效率。常见的激活函数有:Sigmoid、ReLu、Leaky ReLu、Tanh、softmax等。通常情况下,卷积模块使用的激活函数都是ReLu,可以闭眼入。因而,下面将对ReLu稍作解释。
ReLU(Rectified Linear Unit)会将负值映射为0,正值保持不变。ReLU函数的定义如下:
ReLU(x) = max(0, x)
其中,x为输入,ReLU(x)为输出
ReLu函数具有简单高效、激活稀疏性(当输入信号为负值时,ReLU函数的输出为0。这样可以使得神经网络中的部分神经元不活跃,减少了网络的计算量,提高了网络的泛化能力)、避免梯度饱和等优点,但缺点是容易造成神经元死亡、输出不归一化。
2.1.4池化层
池化操作用于减小特征图的空间尺寸,减少计算量,并提取出重要的特征。池化操作方式类似于卷积操作,主要分为最大池化和平均池化两种。顾名思义,最大池化就是将池化窗口中最大值最为输出,平均池化则是求取均值。
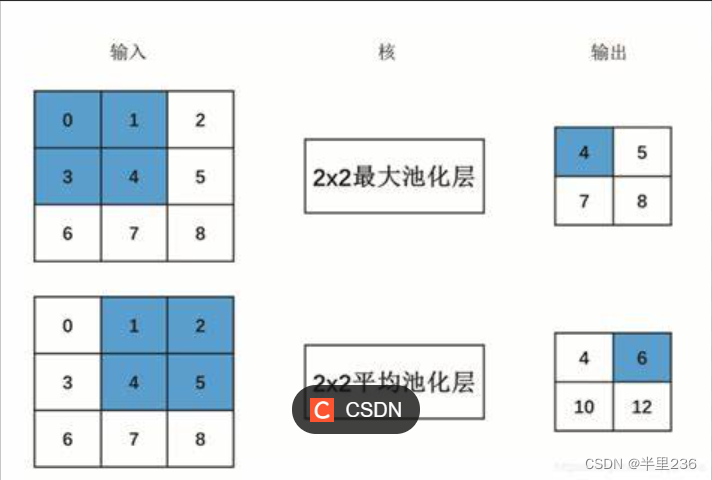 虽然池化能够起到提取关键信息的作用,但是在池化过程中会不可避免的出现信息损失。
虽然池化能够起到提取关键信息的作用,但是在池化过程中会不可避免的出现信息损失。
2.1.5网络架构
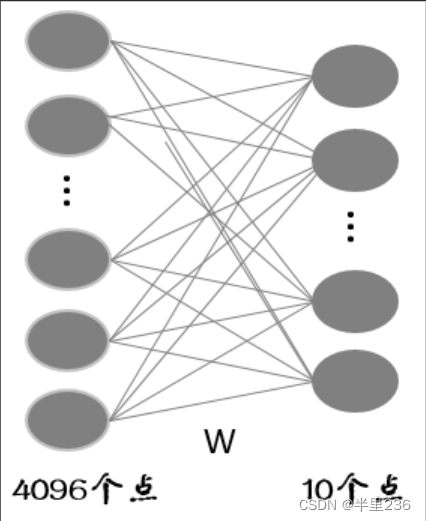
通过上面三个层依次组合后即可实现一个最简单的卷积模块,通过连接几个卷积模块,就能得到最终的特征图。此时,可以根据任务需求,进行不同操作,本文主要讲解分类网络,因此后面应该将网络展平,再连接一个全连接层,再次应用池化操作进行特征压缩。在全连接层中,每个神经元都与前一层中的所有神经元连接,通过学习权重来实现特征的组合和映射。全连接层可以将高维特征映射到输出类别的概率分布,用于分类任务。
2.1.6网络训练
谈及网络训练,离不开前向传播,反向传播,损失函数和优化器四个概念。依笔者之见,网络的训练过程可以抽象为:
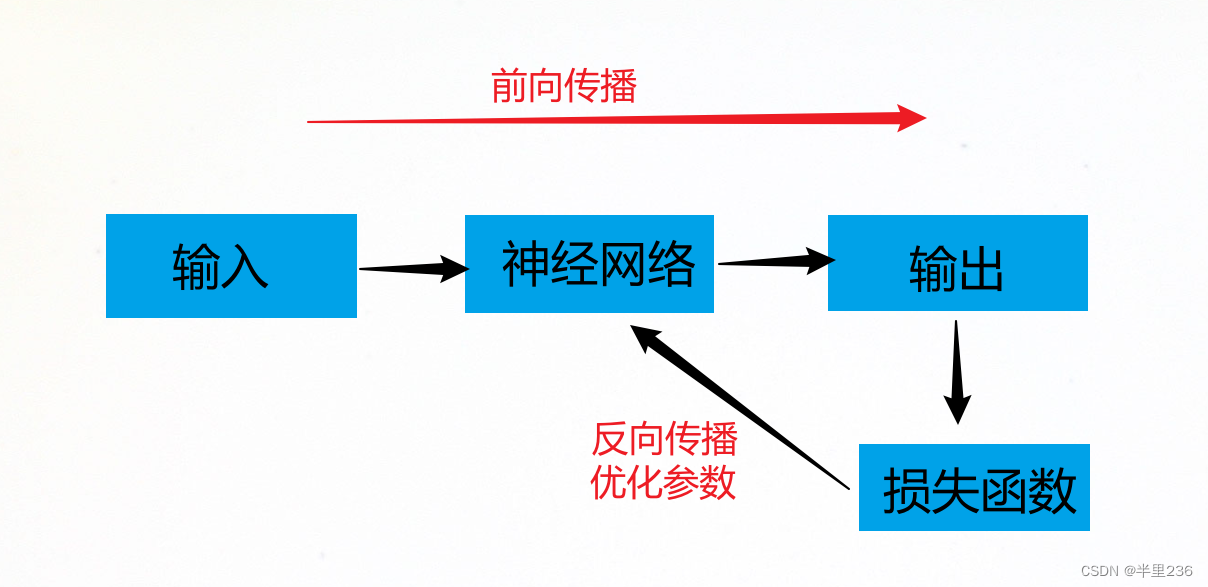 当然实际情况远比此复杂,此处仅仅展示笔者的思路,辅助理解。常见的损失函数包括均方误差、交叉信息熵、对数损失等,优化器包括SGD、Adam、RMSProp等,但是此处给出最常用的损失函数是交叉熵,优化器是SGD,但是也可以根据自己的需求进行更改。
当然实际情况远比此复杂,此处仅仅展示笔者的思路,辅助理解。常见的损失函数包括均方误差、交叉信息熵、对数损失等,优化器包括SGD、Adam、RMSProp等,但是此处给出最常用的损失函数是交叉熵,优化器是SGD,但是也可以根据自己的需求进行更改。
2.2基于ResNet18项目代码解析
2.2.1包和模块导入
源代码中导入的包和模块有很多都用不到,经过精简后,得到下面的部分并进行注释:
import glob # 获取文件路径
import pandas as pd # 用于处理表格数据
import numpy as np # 用于数据计算
import torch # 用于导入torch矿建
import torchvision.models as models # 用于加载现有的模型
import torch.nn as nn # 用于构建模型
from torch.utils.data.dataset import Dataset # 用于加载数据集
import nibabel as nib # 用于处理nii格式的数据
import albumentations as A # 用于图像增强2.2.2自定义数据加载器
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = Truetrain_path = glob.glob('./脑PET图像分析和疾病预测挑战赛公开数据/Train/*/*')
test_path = glob.glob('./脑PET图像分析和疾病预测挑战赛公开数据/Test/*')np.random.shuffle(train_path)
np.random.shuffle(test_path) 首先,设置随机种子来确保代码的可重复性,然后torch.backends.cudnn.deterministic和torch.backends.cudnn.benchmark控制是否使用确定性算法和是否自动寻找适合当前配置的最佳算法。写入数据所在路径,然后将路径随机混洗,增加数据随机性。
DATA_CACHE = {}class XunFeiDataset(Dataset):def __init__(self, img_path, transform=None):self.img_path = img_pathif transform is not None:self.transform = transformelse:self.transform = Nonedef __getitem__(self, index):if self.img_path[index] in DATA_CACHE:img = DATA_CACHE[self.img_path[index]]else:img = nib.load(self.img_path[index])img = img.dataobj[:, :, :, 0]DATA_CACHE[self.img_path[index]] = img# 随机选择一些通道idx = np.random.choice(range(img.shape[-1]), 50)img = img[:, :, idx]img = img.astype(np.float32)if self.transform is not None:img = self.transform(image=img)['image']img = img.transpose([2, 0, 1])return img, torch.from_numpy(np.array(int('NC' in self.img_path[index])))def __len__(self):return len(self.img_path)先建立空字典DATA_CACHE,用于缓存已经加载的图像数据。然后设置一个数据设置类,输入为路径信息,图像增强两部分。在__getitem__方法中,实现了如果路径在缓存区中则取出对应数据,反之则将数据载入缓存区。之后随机选择选定的nii数据中的五十个通道数据作为输入数据,然后进行数据增强处理,最后返回转换为张量后的数据和标签。
train_loader = torch.utils.data.DataLoader(XunFeiDataset(train_path[:-10],A.Compose([A.RandomRotate90(),A.RandomCrop(120, 120),A.HorizontalFlip(p=0.5),A.RandomBrightnessContrast(p=0.5),])),batch_size=2, shuffle=True, num_workers=0, pin_memory=False
)val_loader = torch.utils.data.DataLoader(XunFeiDataset(train_path[-10:],A.Compose([A.RandomCrop(120, 120),])), batch_size=2, shuffle=False, num_workers=0, pin_memory=False
)test_loader = torch.utils.data.DataLoader(XunFeiDataset(test_path,A.Compose([A.RandomCrop(128, 128),A.HorizontalFlip(p=0.5),A.RandomContrast(p=0.5),])), batch_size=2, shuffle=False, num_workers=0, pin_memory=False
)这一步的操作设定好了训练、验证、测试三个数据加载器,其中训练集中train_pathp[:-10]参数是为了将除了最后十个路径下的数据作为训练集。同理,val中的则是将后十个路径下数据作为验证集,起到了分割数据集的作用。A.compose是数据增强操作,包含随机裁剪、水平垂直随机反转、亮度对比度随机调整提升模型泛化能力);batch_size是每个批次样本数量;shuffle决定是否进行打乱(提升模型泛化能力);num_works决定加载数据集的子进程数目(加快数据加载),pin_memory是否将数据储存在固定内存中(若为TRUE将加快速度)。
2.2.3模型定义
class XunFeiNet(nn.Module):def __init__(self):super(XunFeiNet, self).__init__()model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)model.conv1 = torch.nn.Conv2d(50, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)model.avgpool = nn.AdaptiveAvgPool2d(1)model.fc = nn.Linear(512, 2)self.resnet = modeldef forward(self, img):out = self.resnet(img)return out这部分较为简单,直接调用了ResNet12这个模型,并使用了预训练参数。下面改的部分为cnv1即第一层卷积时的参数,将输入通道改为了之前我们在2.2.3设定的50。最后一层全连接层输出通道设定为2,因为我们此次任务是一个二分类任务。最后前向传播返回输出结果。
2.2.4训练与验证
def train(train_loader, model, criterion, optimizer):# 开始训练model.train()train_loss = 0.0# 遍历数据加载器for i, (input, target) in enumerate(train_loader):input = input.cuda(non_blocking=True)target = target.cuda(non_blocking=True)output = model(input)loss = criterion(output, target)# 梯度清零,反向传播过程optimizer.zero_grad()loss.backward()optimizer.step()# 每二十轮打印一次损失函数if i % 20 == 0:print(loss.item())# 累加损失函数train_loss += loss.item()# 返回平均损失return train_loss / len(train_loader)首先定义训练方法,传入的参数为数据加载器,模型,损失函数,优化器。
- 将模型调至训练模式,并设置损失函数初始值为0
- 遍历数据加载器得到输入数据和标签,并将其送入GPU中
- 输入数据送入模型得到输出
- 损失函数计算损失值
- 优化器梯度清零,反向传播,更新参数
- 每二十轮打印一次损失值
- 损失函数累加
- 返回平均损失值
def validate(val_loader, model, criterion):model.eval()val_acc = 0.0with torch.no_grad():for i, (input, target) in enumerate(val_loader):input = input.cuda()target = target.cuda()# compute outputoutput = model(input)loss = criterion(output, target)# output.argmax(1)将输出值取最大值并返回索引# output.argmax(1) == target 与标签进行比较返回布尔值# sum().item() 是统计True的个数,即预测正确的样本数量val_acc += (output.argmax(1) == target).sum().item()# 返回验证集上的准确率return val_acc / len(val_loader.dataset)然后定义验证方法,传入的参数为数据加载器,模型,损失函数 。
- 将模型调整至验证模式,设置初始精确值为0
- 利用上下文管理器(with)停止梯度更新,开始遍历得到数据和标签
- 输入模型得到结果,计算损失函数
- 计算精确度
- 返回平均精确度
model = XunFeiNet()
model = model.to('cuda')
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.AdamW(model.parameters(), 0.001)for _ in range(3):train_loss = train(train_loader, model, criterion, optimizer)val_acc = validate(val_loader, model, criterion)train_acc = validate(train_loader, model, criterion)print(train_loss, train_acc, val_acc)- 模型实例化并送到GPU中,设置损失函数(交叉熵)送到GPU和优化器(AdamW)
- 训练三轮,打印训练损失函数、验证精确度、训练精确度
最后的到的结果如图,第一行为训练第20轮时的损失函数,第二行分别为上述值。
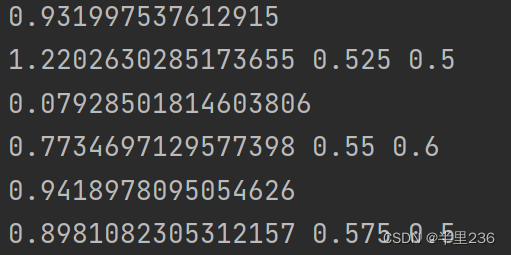
2.2.5预测并保存结果
def predict(test_loader, model, criterion):# 设置为测试模式model.eval()val_acc = 0.0# 创建预测值列表test_pred = []# 利用上下文管理器,实现停止梯度更新(优化)的过程with torch.no_grad():for i, (input, target) in enumerate(test_loader):input = input.cuda()target = target.cuda()output = model(input)# 添加预测值test_pred.append(output.data.cpu().numpy())# 返回垂直堆叠后的预测结果return np.vstack(test_pred)首先定义一个预测方法,输入参数有数据加载器,模型,损失函数。由于该方法和2.2.4中的验证方法基本一致不过多赘述。最后将垂直堆叠的预测结果返回。
pred = None
# 预测十轮,将多次预测结果累加
for _ in range(10):if pred is None:pred = predict(test_loader, model, criterion)else:pred += predict(test_loader, model, criterion)# 将预测结果保存为提交格式
submit = pd.DataFrame({# 对test_path中的路径名称按照‘/’划分为列表格式,[-1]表示取最后一个即1.nii,[:-4]即取.nii前方的字符'uuid': [int(x.split('/')[-1][:-4]) for x in test_path],'label': pred.argmax(1)})
# 利用map将对应的标签值0,1映射为NC和MCI
submit['label'] = submit['label'].map({1: 'NC', 0: 'MCI'})
# 按照uuid进行排序
submit = submit.sort_values(by='uuid')
submit.to_csv('submit2.csv', index=None)- 设置初始预测值为None
- 预测十轮,将多次预测结果累加
- 将预测结果保存为提交格式,具体单步操作解析已经注释。
提交后的结果为0.69444,远超任务一中的逻辑回归模型。
2.3一些问题与解决办法
2.3.1包、模块缺失
问题描述:在跑代码的过程中出现了tqdm包显示无法解析与引用的问题,笔者一开始认为是没有下载该包,于是在pycharm中重新下载了一次,但下载后并未解决问题,反而显示已经安装。
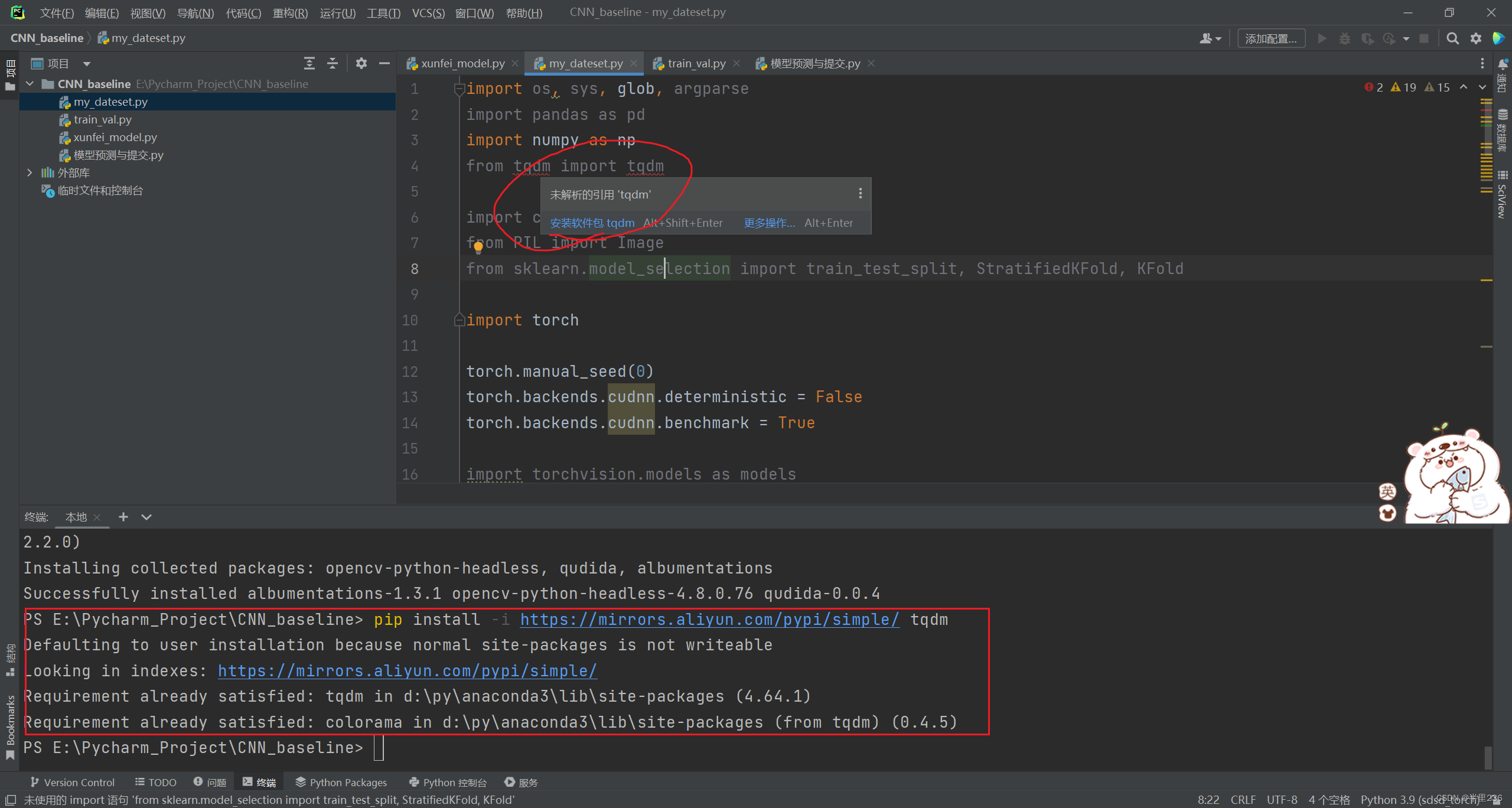
问题原因:我现在使用的是torch虚拟环境,该包仅仅安装在base环境中。
解决办法:在终端中激活当前环境,然后再进行安装,conda环境下可以使用这个的命令:
conda activate 环境名称
conda insatll 包名称2.3.2 多线程运行错误
报错信息:RuntimeError: DataLoader worker (pid(s) 14652) exited unexpectedly.
问题描述:通过gpt发现是因为在2.2.2中采用多线程,num_works设定为1,代表启动多线程。
问题原因:在Linux中可以直接启用多线程,但是在Windows中不行。
解决办法:在相应代码前加入下面的代码,或者将num_works设置为0,推荐采用后者。
if name == '__main__':2.3.3路径分隔错误
报错信息:ValueError: invalid literal for int() with base 10: 'Test\\23'
问题描述:int()期望一个有效的十进制数字作为参数,但'Test\23'不是一个有效的十进制数字。
问题原因:通过debug文件发现这个是属于win和linux之间使用不同的文件路径约定所导致的。
解决办法:将2.2.4中的相应代码进行修改,如下
'uuid': [int(x.split('\\')[-1][:-4]) for x in test_path]2.4 一些想法和尝试
2.4.1增加迭代次数
通过1.4.2的结果,我们可以看出通过增加迭代次数可以有效提升模型的拟合效果。因此,笔者再次做了一个简单的尝试,即将训练次数由3轮修改为10轮。
为了更明显的观察出不同方案对训练结果的影响,因此笔者在代码中增加了可视化部分,应用matplotlib库函数,做出了训练集上的损失函数和准确率图像,验证集上准确率图像。修改后的2.2.4训练方法代码如下,验证方法类似。
train_loss_history = []
train_accuracy_history = []
val_accuracy_history = []def train(train_loader, model, criterion, optimizer):model.train()train_loss = 0.0for i, (input, target) in enumerate(train_loader):input = input.cuda(non_blocking=True)target = target.cuda(non_blocking=True)output = model(input)loss = criterion(output, target.long())optimizer.zero_grad()loss.backward()optimizer.step()acc = (output.argmax(1) == target).sum().item()accuracy = acc / target.size(0)train_loss_history.append(loss.item())train_accuracy_history.append(accuracy)train_loss += loss.item()return train_loss / len(train_loader)训练十轮的结果图像:
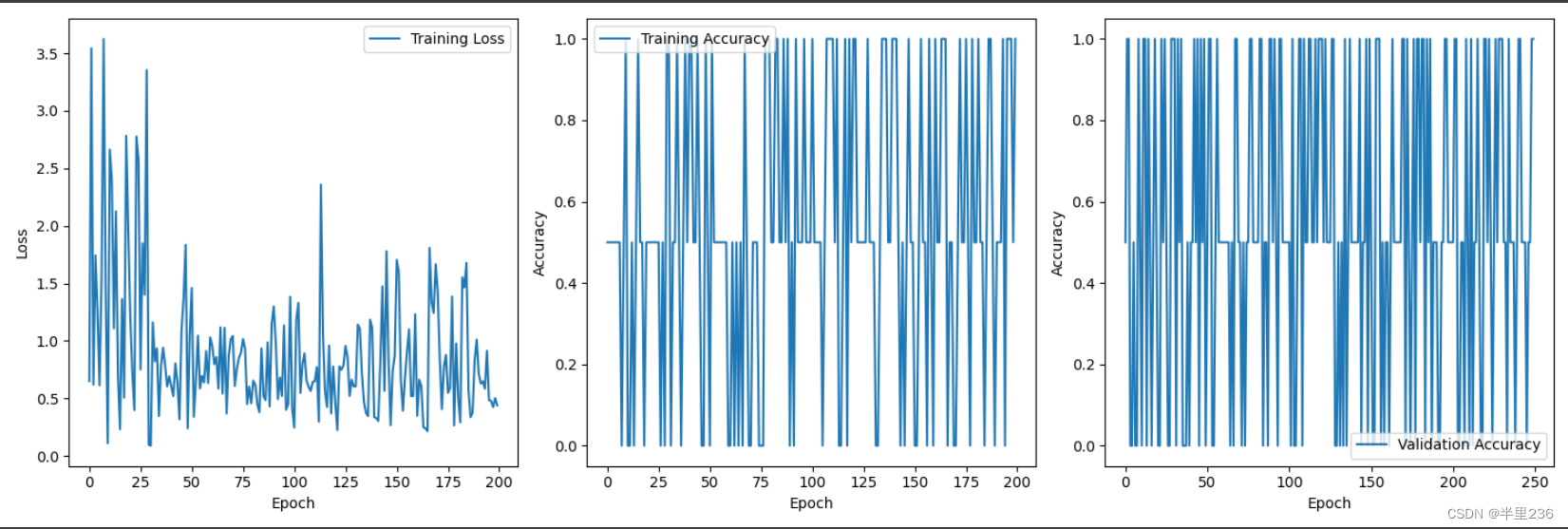
训练30轮的结果图像:

从图像可以看出,模型损失函数主要在0.7-0.8区间内波动,而准确率也在波动。可以看出模型基本收敛。提交结果后训练3轮结果为0.69444,10轮的结果0.70968,30轮为0.75159,还是有较为明显的提升。由于提交结果次数限制,笔者也只能减少实验次数。
2.4.2数据增强
正如笔者在1.4中提到的,合理采用数据增强方法可以有效提高模型的泛化能力。因此笔者计划采用albumentations包中的其余数据增强方法,来分别训练3轮和30轮。
在此处,笔者使用了A.Perspective(p=0.25),随机透射变换,为训练集和测试集进行数据增强。它可以通过平移、缩放元稹、旋转和剪切来改变图像的形状和姿态。它可以将图像投影到不同的视角上。但是很可惜得到的分数竟然下降到0.35052。具体原因并不清楚,但是笔者在这里提出两种猜测:
- 随机投射变化会导致图像中的物体形状出现扭曲,因此使得图像原本的特征信息丢失。
- 在测试集中也使用了随机投射变换,使得特征变换后难以被拟合出正确的结果。如果可以,也许通过删除测试集中投射变换部分更佳。
下面给出两张图像分别为测试集和训练集都有投射变换,和仅有训练集有的30轮损失函数。
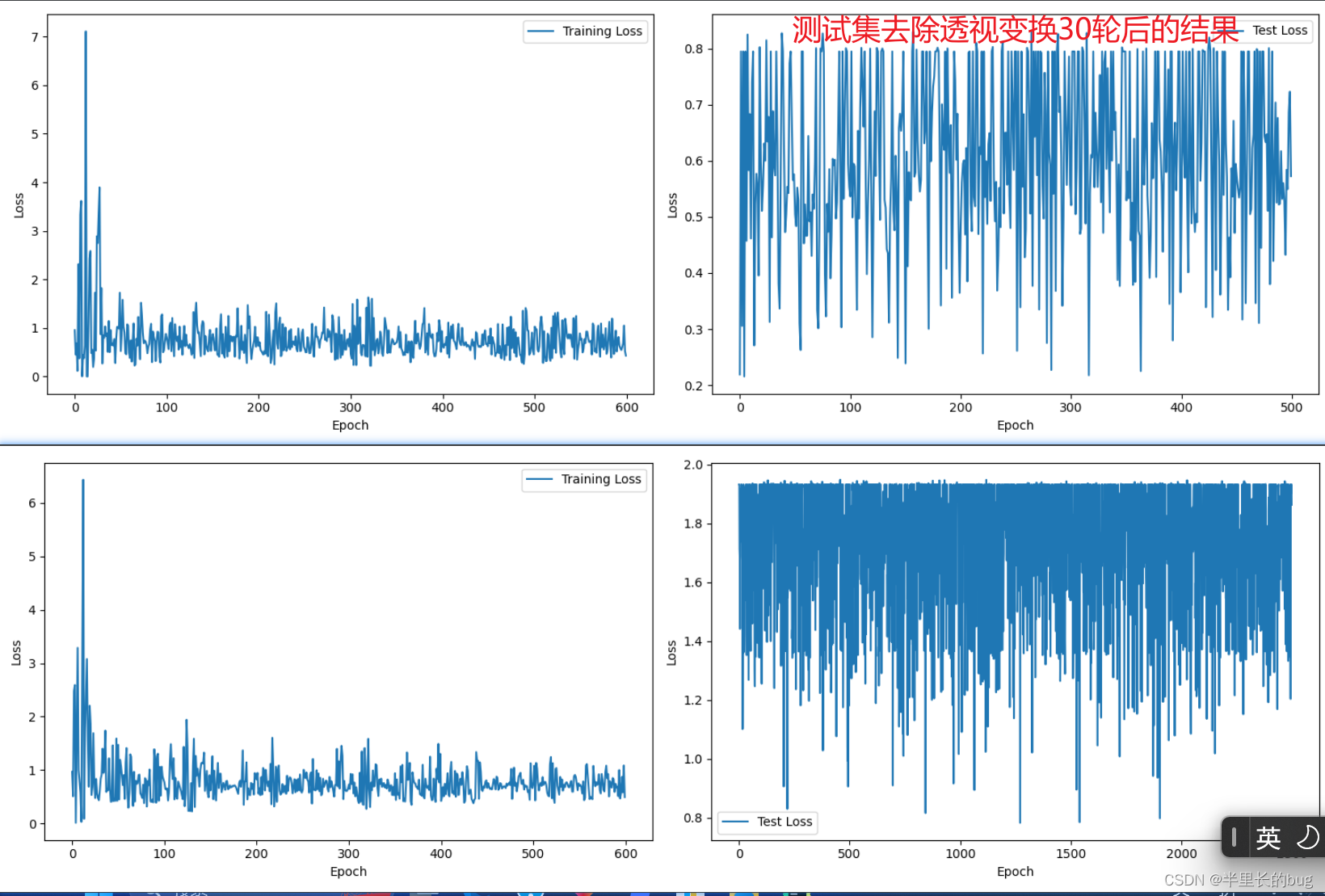
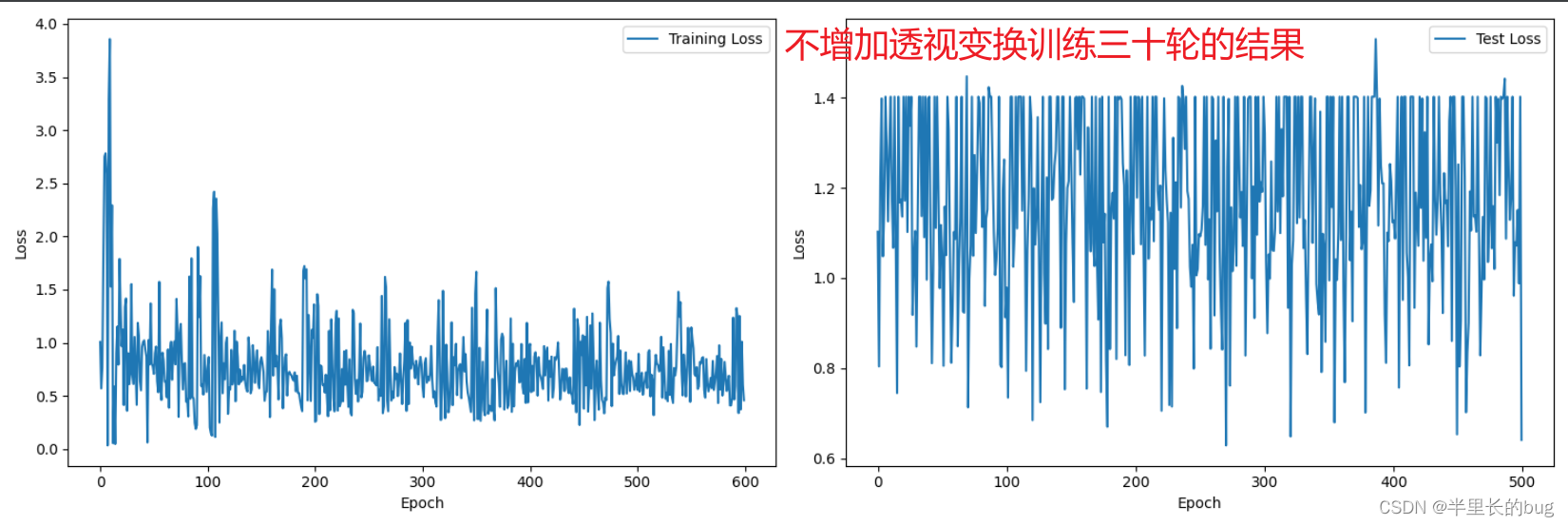
从中可以看出,去除测试集上透视变换后,测试机损失函数明显降低,这个问题得以解决。
再与不经过透视增强的训练集30轮的训练结果比较。发现测试集上的损失函数也明显降低,由此可以推断该次结果效果会更好。果然此时的分数达到了0.74214。
2.4.3提升预测轮数
由于本次预测的最终结果由投票的方式获得,因此笔者推测提升预测轮数也许能够提升最终结果的准确率。我们此时采用上述增强后效果最好的模型,即:训练三十轮,训练增加透视变换。在此基础上将预测轮数提升至50轮。提交结果后令人震惊的发现分数变为0,这很难评。
但抽象的是,该次训练在测试集上的损失函数相当好。
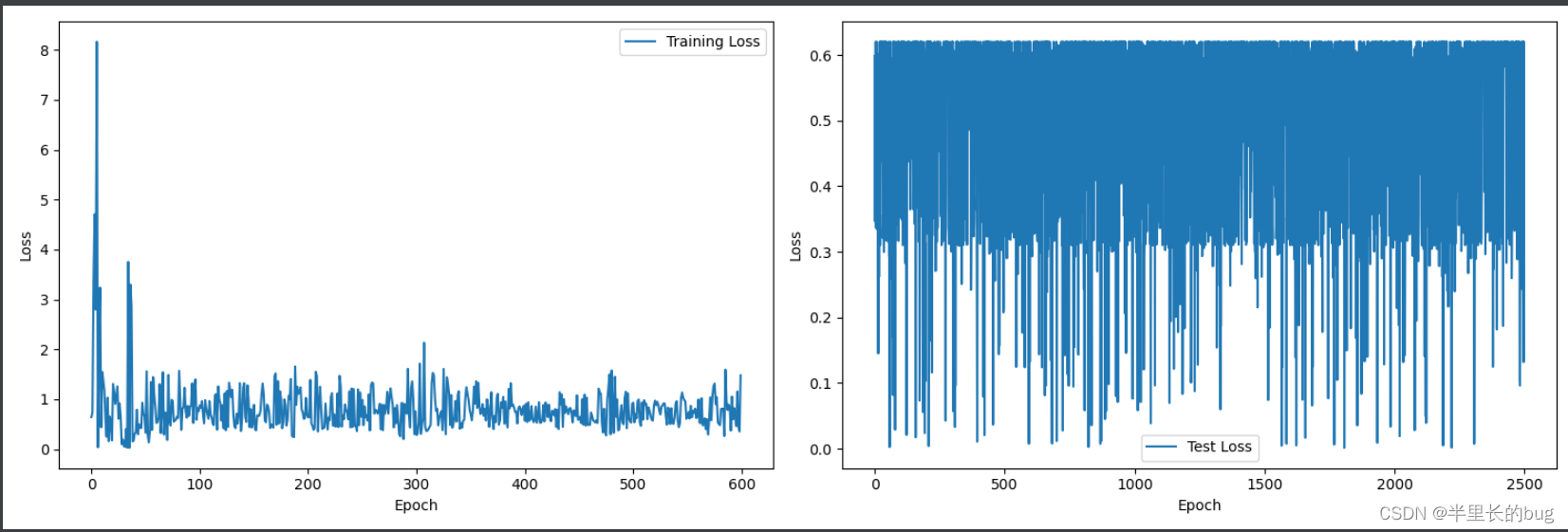
2.4.4一些并未尝试的想法
- 更换模型,ResNet18仅仅是ResNet系列网络中的一个,此外还有ResNet34/50等,选择更深的网络,也许训练效果更好。
- 更新参数,修改学习率,以及数据增强时的各种参数,更换优化器。
- 采用学习率策略,如使用学习率退火。
任务三:进阶提升准确率
概述:
在任务二的学习中,我们已经初步实现了比较完整的模型训练过程,并利用预训练的ResNet18(后面称R18)实现了PET脑图的二分类任务。甚至经过一些尝试后,最高准确率达到了0.75,因此,下一步的方向就是进一步提升模型准确率。夏令营给出了四个方向可以选择:更换预训练模型、训练集数据增强、交叉验证、测试集数据增强。
3.1更换预训练模型
3.1.1ResNet34
ResNet(Residual Network)是一个非常重要的深度学习架构,它在2015年由Kaiming He等人提出,并在ImageNet图像分类竞赛中获得了优异的成绩。ResNet解决了深度神经网络中出现的梯度消失和梯度爆炸等问题,使得训练非常深的神经网络变得可能。
在这里我们将利用更深层次的ResNet34(后面称R34),代替R18,训练3轮、10轮、30轮,观察训练集和测试集上的损失以及训练花费的时间。
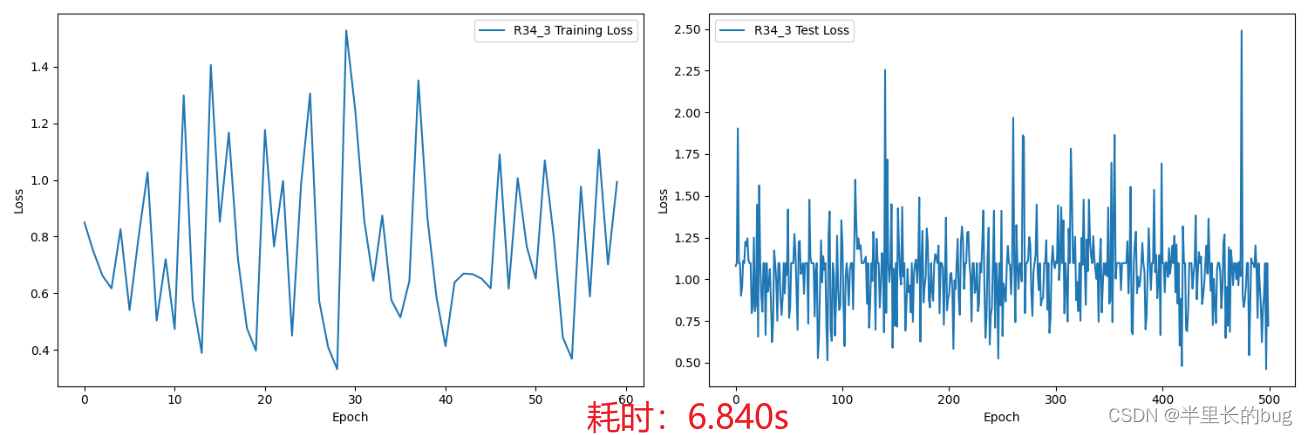
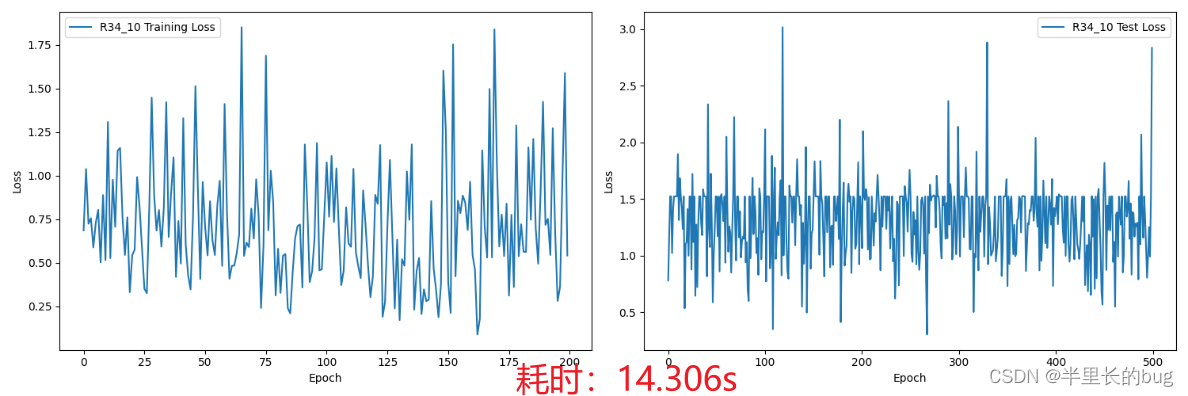
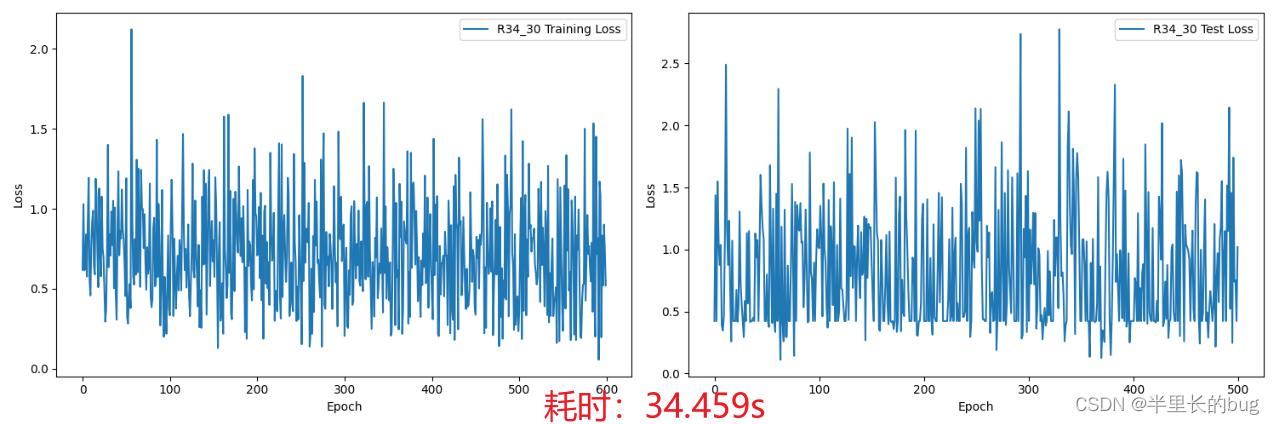
可以看出来其实效果并不好,进入提交文件后更是发现3、10轮的预测结果竟然全是NI或者全是MCI因此这个结果肯定是不行的,考虑原因应该是模型过拟合,但是三十轮又奇迹般的变好了。
3.1.2ResNet50
一如上文,我们直接上R50的数据:
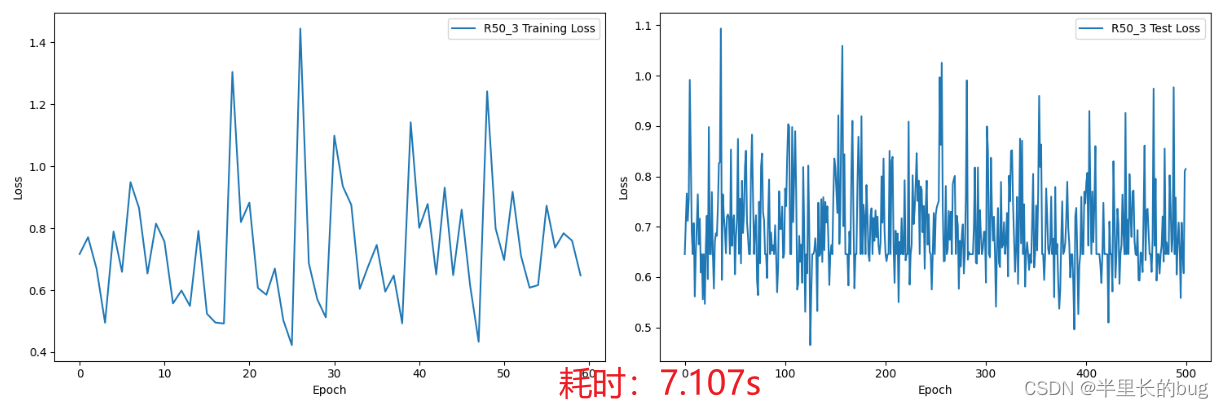
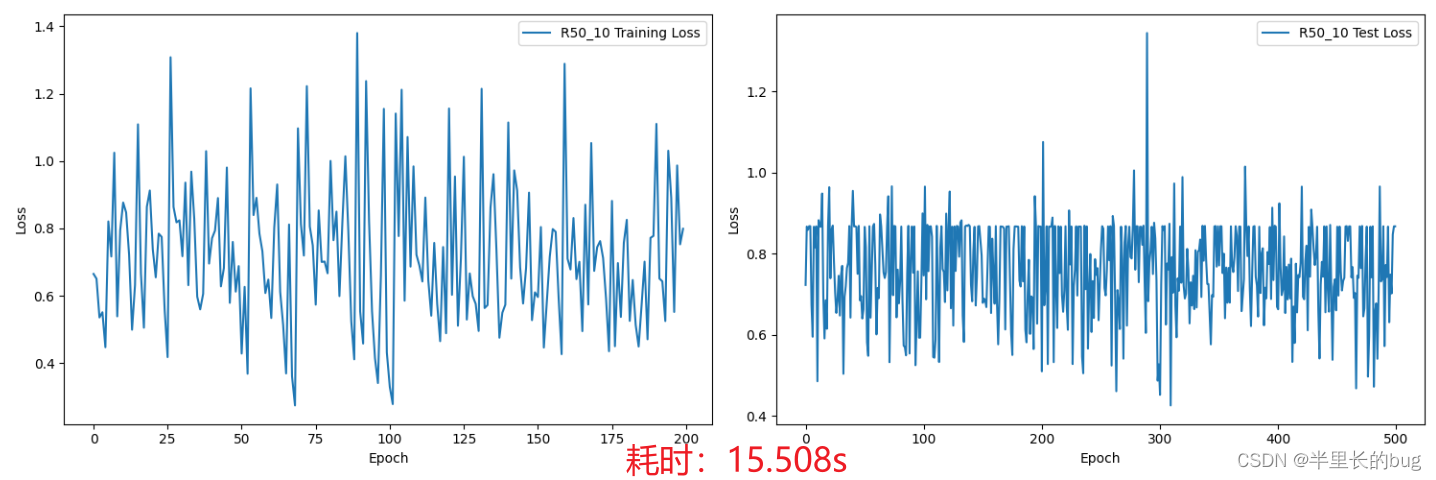
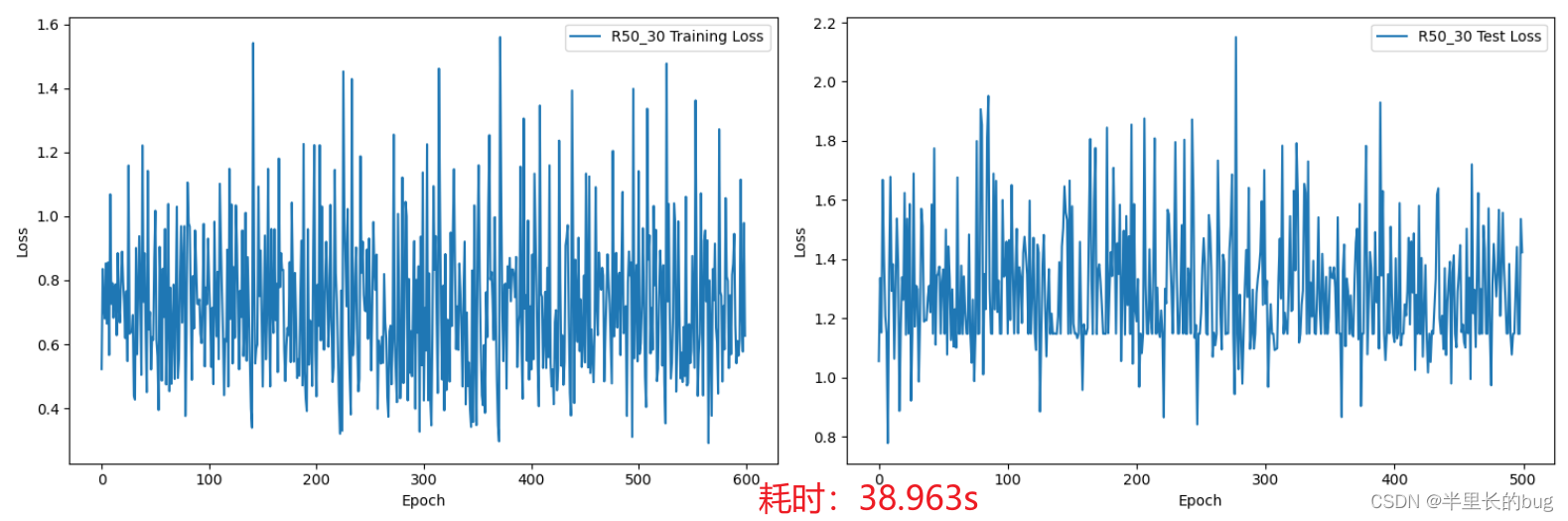 通过观察可以发现在训练轮数为3时模型在测试集上的损失最小,说明后面的模型可能过拟合了。并且由于模型深度的叠加,训练时间相较于R34变长。
通过观察可以发现在训练轮数为3时模型在测试集上的损失最小,说明后面的模型可能过拟合了。并且由于模型深度的叠加,训练时间相较于R34变长。
3.2数据增强
3.2.1使用模糊和随机变换
笔者增加了下面两种数据增强方法,希望能够得到更好的效果。shift_limit=0.1表示图像平移的最大距离是原图像尺寸的10%;scale_limit=0.2表示图像缩放的最大比例是原图像尺寸的20%;rotate_limit=45表示图像旋转的最大角度是45度;blur_limit=3表示模糊程度的范围是3。
A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.2, rotate_limit=45),
A.Blur(blur_limit=3)然后再3.1.2 R50_10的基础上进行训练,结果如下:
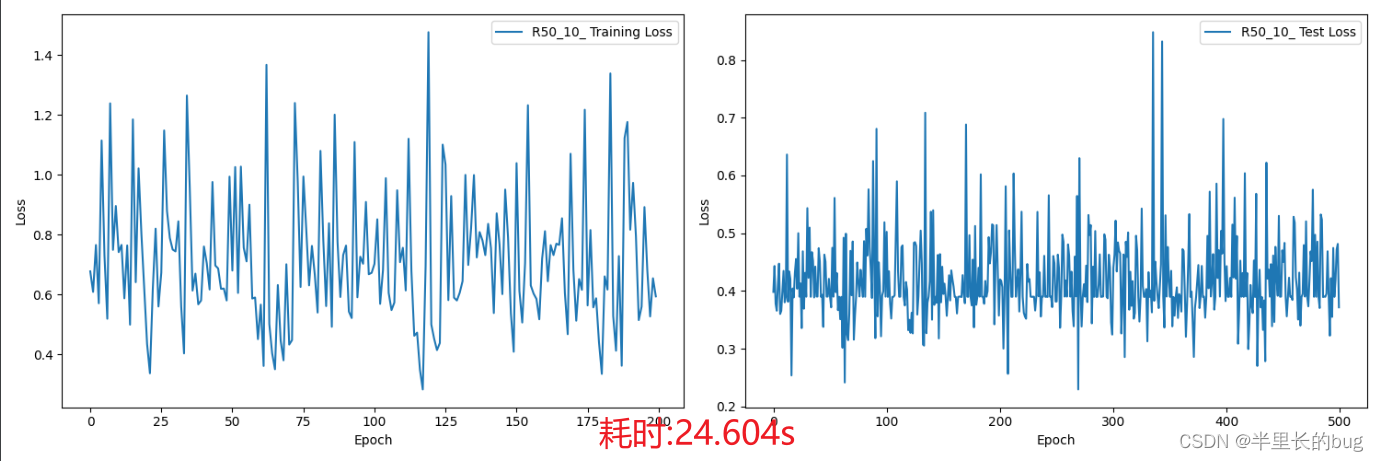
训练结果在测试集上的损失很低,但是预测中将所有的样本都预测为了MCI ,笔者经过实验后发现造成这个现象的原因与最终预测的投票轮数有关。
3.3使用jpg训练
3.3.1nii2jpg
考虑到原来的方案中,在数据采集的步骤中,baselin采用的方案是讲nii中随机选取50个通道组合后作为输入,虽然操作简单,但是这种方式产生的弊端很明显:随机性过高、数据量较少。而总所周知,深度学习本身对数据集的依赖性很强,大量的数据才能有效提高模型的拟合能力。因此,笔者考虑将nii格式的数据切片为三通道的jpg格式的图片数据,以此进行训练,分割后发现此时训练数据量达到了10255张图片,较原来的数据量有了很大的提升。
处理后的数据样本展示
3.3.2训练集、验证集划分
跟原来的方案不同,将数据格式转换为jpg以后,笔者采用单独的脚本将训练集与验证集进行划分,比例为4:1,将随机打乱后的路径名分别存储在train_list.txt和val_list.txt两个文件中,并在路径后标注了样本标签。
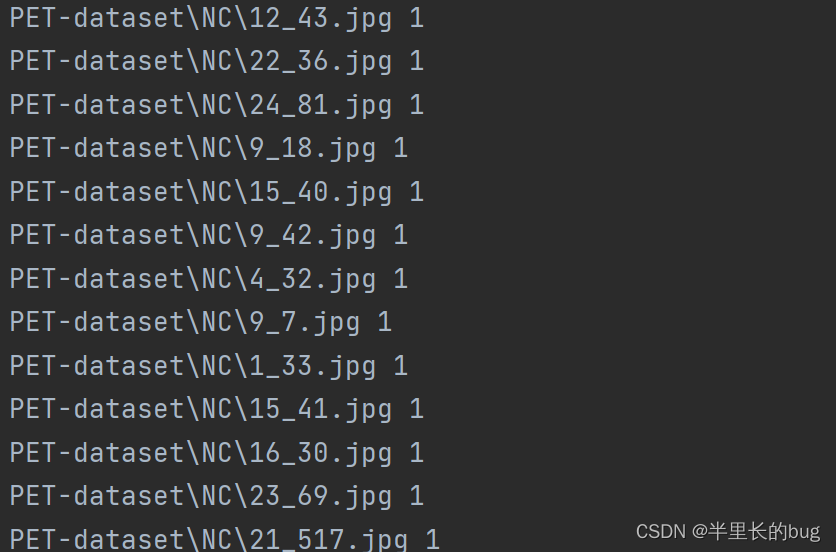
处理后的路径信息展示
3.3.3数据准备
由于更改了数据加载的方式,我们需要重新编写一个数据加载器,代码展示如下。
class MyDataset(torch.utils.data.Dataset):def __init__(self, file_list, transform=None):self.file_list = file_listself.transform = transformdef __len__(self):return len(self.file_list)def __getitem__(self, idx):image_path = self.file_list[idx][0]image = Image.open(image_path)img = np.array(image).astype(np.float32)if self.transform is not None:img = self.transform(image=img)['image']img = img.transpose([2, 0, 1])[:3]if len(self.file_list[idx]) == 2:label = int(self.file_list[idx][1])return img, torch.tensor(label)else:return img通过该段代码,我们可以通过读取文件路径,将对应的代码和标签加载好,并且能实现测试集部分由于没有标签,因此只返回对应的图片。 并且也能实现相应的数据增强功能。
3.3.4结果预测
同样地,由于更改了数据集,结果预测的部分也需要进行修改,在这里笔者采用的也是类似于投票的方式,因为单个样本被切片为了多个样本,因此模型将会对多个样本进行预测,预测出的结果无非只有两种:0 or 1,因此只需要将同一样本的预测结果相加求均值,若大于0.5则说明其预测结果为1(MCI),反之则为0(NC)。
综上,我们就得到了使用jpg格式数据训练的模型和预测结果,展示如下:
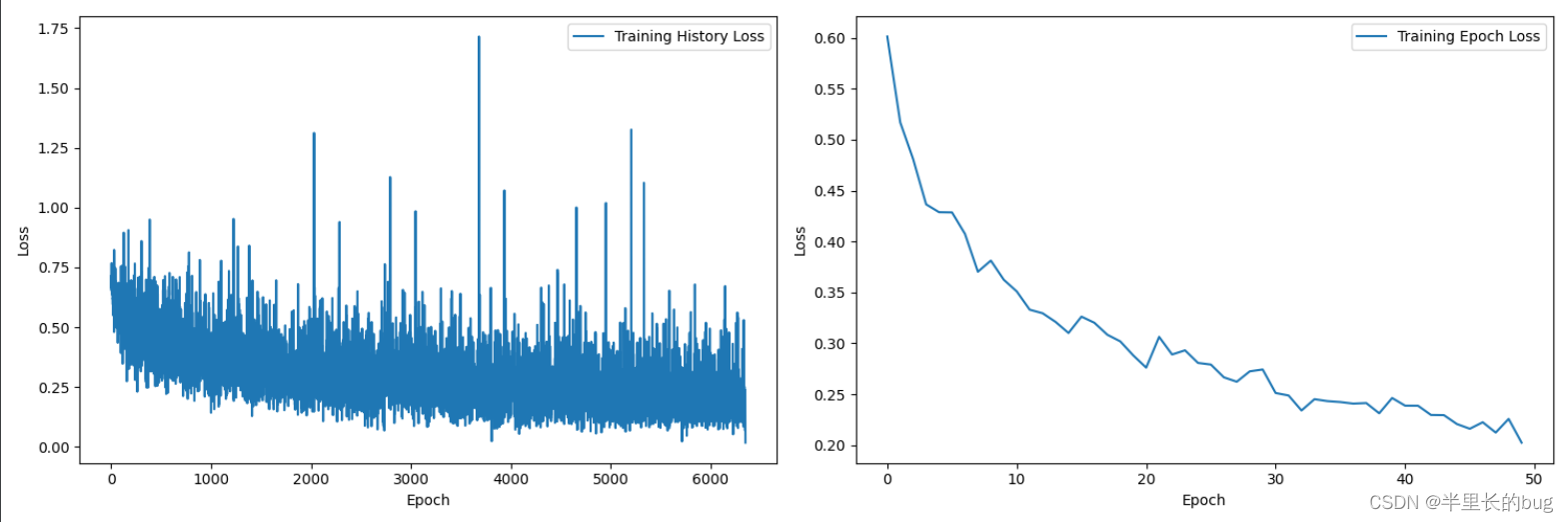
肉眼可见地,现在模型在训练集和验证集上的变现十分良好,因此提交结果后得到分数为:0.78146
这篇关于2023.8DataWhale_cv夏令营第三期笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







