本文主要是介绍静力触探数据智能预处理(4),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
静力触探数据智能预处理(4)
前言
数据处理方式已由手工1.0、计算机辅助2.0向人工智能3.0的趋势发展。机器学习是人工智能的基础,本文尝试应用机器学习中K均值聚类算法对孔压静力触探数据进行土的分类,分类结果不理想,非专业编写,代码仅供参考。
1、分类结果
某规范给出的分类标准:
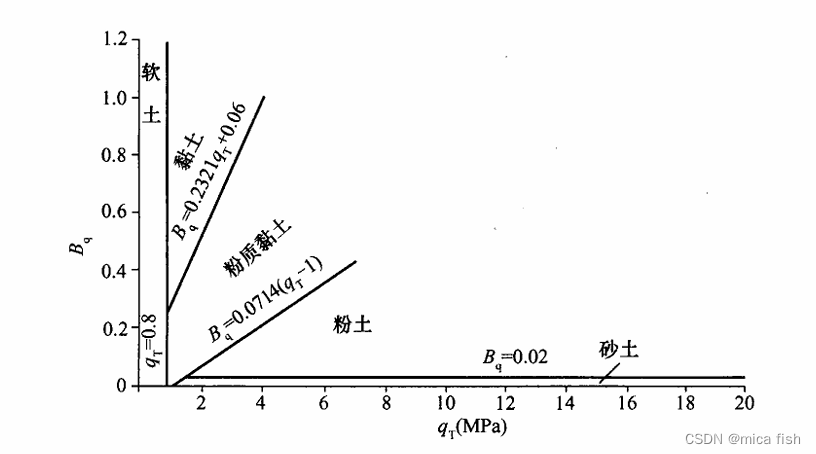
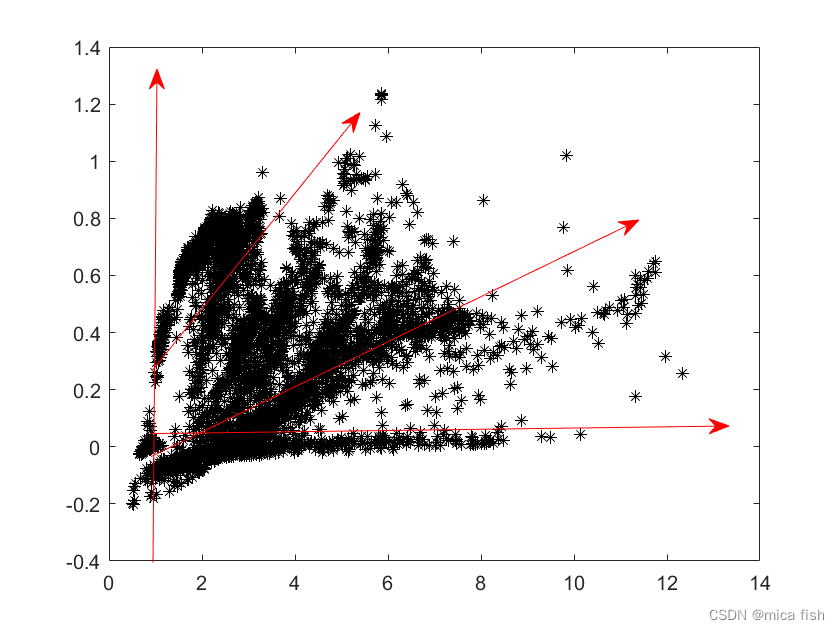
按照规范进行分类结果如下:
应用机器学习中K均值聚类算法分类如下:
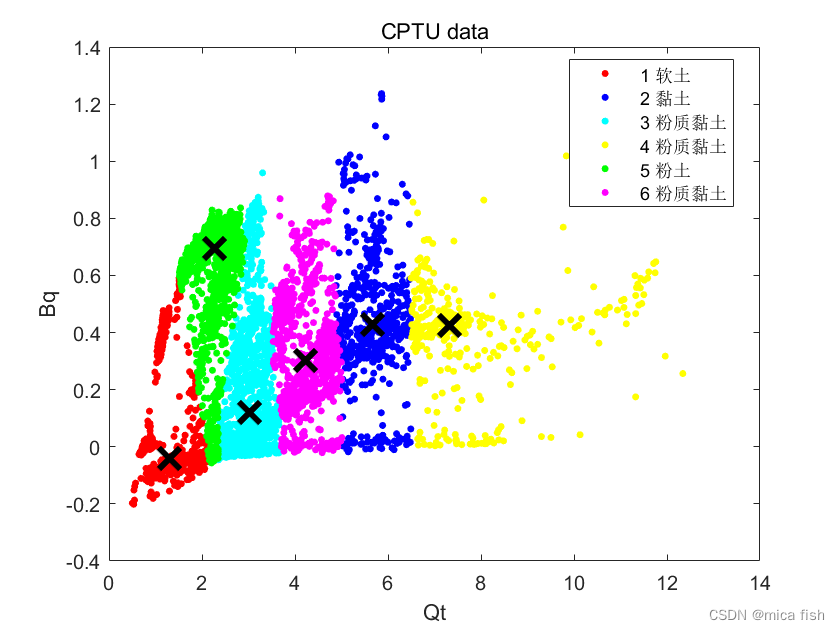
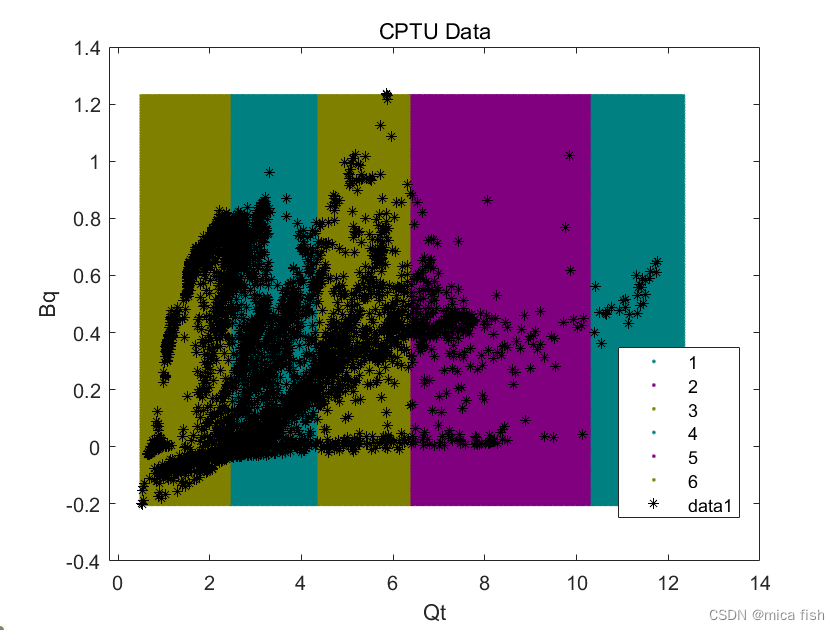
分类结果不理想,机器学习参数调试不正确。
2、聚类算法原理简介
机器学习中有两个重要的任务,即分类和聚类。
分类算法有逻辑回归、支持向量机、决策树、随机森林等。
聚类算法有K均值聚类、层次聚类、密度聚类、谱聚类、EM聚类、模糊聚类等。
K均值聚类是一种常用的无监督学习算法,用于将数据点划分为不同的簇,使得同一簇内的数据点彼此相似度较高,不同簇之间的数据点相似度较低。这个算法的目标是将数据点分为K个簇,其中K是用户定义的参数。K均值聚类的原理相对简单,主要思想是通过迭代寻找K个簇的中心点,将每个数据点分配给距离其最近的中心点,然后更新中心点的位置,直到满足停止条件为止。
实现步骤如下:
1、选择要分成的簇的数量K;
2、随机初始化K个中线点,这些中心点可以是从数据集中随机选择的数据点;
3、重复以下过程,直到满足迭代停止条件:
a、将每个数据点分配到距离其最近的中心点所属的 簇;
b、对每个簇,计算所有数据点的平均值,并将其作为新的中心点。
停止条件通常可以是以下之一:
(1)中心点不再改变或者改变非常小;
(2)数据点不再改变其所属簇。
3、机器学习库安装
scikit-learn是机器学习领域重要的开源库,包含目前流行的聚类算法。需要安装最新的Python版本和scikit-learn存储库,将conda添加至环境变量后,直接可以用pip安装,如下所示:
pip install scikit-learn
安装完毕后检查电脑中库的版本
import sklearn
print(sklearn.--version--)
即安装完成。
4、代码分享
实现本博文所示结果,完整代码如下:
close all
clear
clc[inFileName,PathName] = uigetfile('*.txt',...'选择静探数据文件','MultiSelect','on');filename = strcat(PathName,inFileName);% 将静探数据读取出来
data_jt = importdata(filename);% 剔除重复值
[data_jt01,ia] = unique(data_jt(:,1),'rows','stable');
data_jt = data_jt(ia,:);% 一共有五列数据,分别为深度、锥尖、侧壁、孔压、角度。
deepth = data_jt(:,1);% 单位为m
qc = data_jt(:,2); % 单位为mPa
fs = 0.1*data_jt(:,3); % 单位为0.01mPa
ut = 0.01*data_jt(:,4); % 单位为0.1mPau0 = 0.01*(deepth+18.5)*1.05*9.79363; % 单位为0.1mPa
Qt = qc + (1 - 0.75)*ut*10; % 孔压修正锥尖阻力,单位mPa
P = 2*10^3*deepth*9.79363*10^-6; % 土的总自重压力,单位mPa
Bq = (10*ut - 10*u0)./(qc - P); %孔隙压力参数比
% Bq(Bq<0) = 0.4; % 任意设的一个阈值
Bqpre1 = 0.2321*Qt + 0.06;
Bqpre2 = 0.0714*(Qt - 1);name = cell(length(Qt),1);
y_name = zeros(length(Qt),1);
y_color = cell(length(Qt),1);
for i = 1:length(Qt)if Qt(i) <= 0.8name(i) = cellstr('软土');
% y_name(i) = Bq(i);y_name(i) = Qt(i);y_color(i) = cellstr('r');elseif Bq(i) > Bqpre1(i)name(i) = cellstr('黏土');
% y_name(i) = Bq(i);y_name(i) = Qt(i);y_color(i) = cellstr('b');elseif (Bq(i) <= Bqpre1(i) ) & (Bq(i) >= Bqpre2(i))name(i) = cellstr('粉质黏土');
% y_name(i) = Bq(i);y_name(i) = Qt(i);y_color(i) = cellstr('g');elseif Bq(i) < Bqpre2(i) & Bq(i) > 0.02name(i) = cellstr('粉土');
% y_name(i) = Bq(i);y_name(i) = Qt(i);y_color(i) = cellstr('y');elsename(i) = cellstr('砂土');
% y_name(i) = Bq(i);y_name(i) = Qt(i);y_color(i) =cellstr( 'k');end
endX = [Qt/10,Bq/100];
[idx,C] = kmeans(X,6);
figure(1),plot(X(:,1),X(:,2),'k*');x1 = min(X(:,1)):0.01:max(X(:,1));
x2 = min(X(:,2)):0.01:max(X(:,2));
[x1G,x2G] = meshgrid(x1,x2);
XGrid = [x1G(:),x2G(:)]; % Defines a fine grid on the plotidx2Region = kmeans(XGrid,6,'MaxIter',100,'Start',C);figure(2);
gscatter(XGrid(:,1),XGrid(:,2),idx2Region,...[0,0.5,0.5;0.5,0,0.5;0.5,0.5,0],'..');
hold on;
plot(X(:,1),X(:,2),'k*','MarkerSize',5);
title 'CPTU Data';
xlabel 'Qt';
ylabel 'Bq';
% legend('Region 1','Region 2','Region 3','Data','Location','SouthEast');
hold off;% opts = statset('Display','final');
% [idx,C] = kmeans(X,6,'Distance','cityblock',...
% 'Replicates',100,'Options',opts);
%
% figure;
% plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',12)
% hold on
% plot(X(idx==2,1),X(idx==2,2),'b.','MarkerSize',12)
% plot(X(idx==3,1),X(idx==3,2),'c.','MarkerSize',12)
% plot(X(idx==4,1),X(idx==4,2),'y.','MarkerSize',12)
% plot(X(idx==5,1),X(idx==5,2),'g.','MarkerSize',12)
% plot(X(idx==6,1),X(idx==6,2),'m.','MarkerSize',12)
%
% plot(C(:,1),C(:,2),'kx',...
% 'MarkerSize',15,'LineWidth',3)
% legend('1 软土','2 黏土','3 粉质黏土','4 粉质黏土','5 粉土','6 粉质黏土',...
% 'Location','best')
% title 'CPTU data'
% xlabel 'Qt';
% ylabel 'Bq';
% hold off
编程水平有限,本代码尚不成熟,不足之处指出改正,勿作他用。
这篇关于静力触探数据智能预处理(4)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





