本文主要是介绍工业界常用的推荐系统模型有哪些?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

最近收到很多同学的提问,目前工业界常用的推荐系统模型有哪些?CTR和推荐算法有什么本质区别?推荐系统中如何做 User Embedding?橙子邀请了淘系技术部的豆苗同学对以上问题进行解答,也欢迎大家一起交流。
Q:工业界推荐系统采用什么架构?
豆苗:
一般来说,工业界推荐系统采用召回->排序两阶段的架构。
召回阶段从海量内容池中召回数千条内容生成候选集,排序阶段利用用户、内容侧丰富的特征、上下文信息和复杂的模型对候选集中的内容进行打分排序,最终为用户返回数十条内容。
本人主要工作在召回侧,所以下面简单列出召回相关的策略和模型。
▐ 召回环节优化通常经历三个阶段
基础个性化召回->深度个性化召回->多目标多策略召回
基础个性化召回
基于统计和传统模型(如swing、userCF、itemCF等)产出各种x2i数据,进行以i2i为主,c2i,、b2i补充,热门兜底的多路召回,各召回链路可单独优化。
深度个性化召回
将user、item转化为向量,通过向量检索技术召回topk,变“精确匹配”为“模糊查找”,提升召回的扩展性。首先需要尝试的是FM,可以参考:张俊林的《推荐系统召回四模型之:全能的FM模型》

阅读地址:
https://zhuanlan.zhihu.com/p/58160982
还有基于用户行为序列、基于多兴趣拆分的、基于graph embedding和和基于知识图谱融合的。
用户行为序列
这类模型代表性的方法是SASRec,这是18年的发表在ICDM上的一篇针对召回的工作,主要是借助transformer来对用户的历史行为序列建模,提取更为有价值的信息。整个模型基本上是套在transformer这个框架下的,所以有position embedding、block的stacking等等,需要注意的是作者也有作一些调整,比如只有当j > i 的时候Qi 和 kj 才会进行相关性的计算,并且采用非固定的Position embedding。
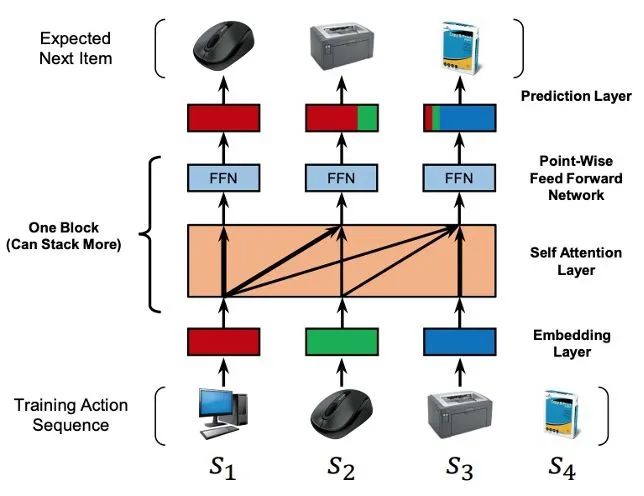

阅读地址:
https://cseweb.ucsd.edu/~jmcauley/pdfs/icdm18.pdf
用户多兴趣拆分
这类模型核心的思想就是认为单一的向量无法充分表征用户,从而采用多个向量表征用户的多峰兴趣,最为典型的就是MIND,它利用动态路由技术,对用户兴趣进行拆分。模型的输入包含三部分:用户属性特征、用户行为特征(例如点击过的商品/内容)和label特征。首先,所有的id类特征都经过embedding层,其中对于用户行为特征对应的embedding向量还会进行average pooling。接着,传递给multi-Interest extract layer,生成的interest capsules。最后将interest capsules与用户属性特征的embedding concate起来经过几层全连接网络,得到用户多个兴趣表达向量。值得注意的是,在模型的最后有设计一个label-aware attention层,用以针对每个用户从多个兴趣中挑选出与其下一次点击行为最相关的兴趣, 送入到后续的训练。
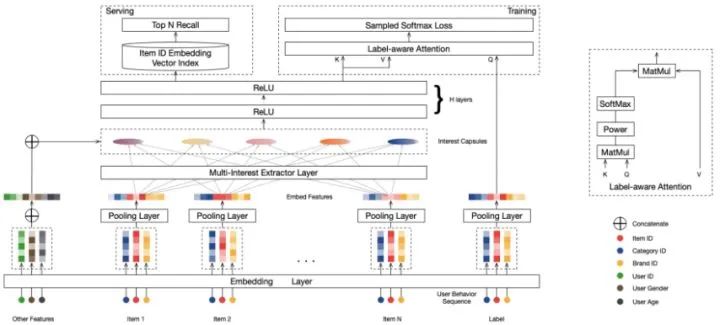

阅读地址:
https://arxiv.org/abs/1904.08030v1
其他相关的多兴趣拆分的方法有:
基于注意力机制

阅读地址:
https://dl.acm.org/doi/abs/10.1145/3394486.3403344
https://dl.acm.org/doi/abs/10.1145/3397271.3401088
基于层次凝聚聚类

阅读地址:
https://dl.acm.org/doi/10.1145/3394486.3403280
Graph Embedding
这类模型是近期推荐系统召回环节较为热门的研究方法,并且也在线上拿到了收益。例如EGES、PinSAGE、PinnerSAGE等。
多目标多策略召回
在以点击率为优化目标的基础上,尝试优化发现性、成交率等其他目标。以及将积累的各种召回模型,根据业务实际需求实行多策略召回。
Q:CTR和推荐算法有什么本质区别?
豆苗:
一般来说,一个完整的推荐算法包含召回、粗排、精排和重排这四个环节,而ctr预估只是在排序时的一个重要参考依据。
借用一张经典的图来抛下观点:
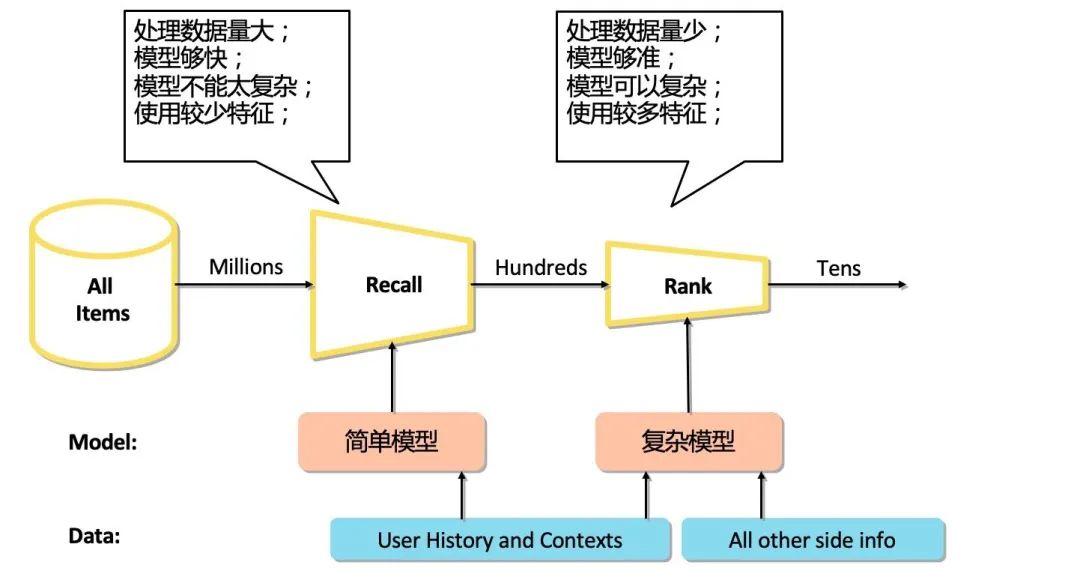
▐ 召回有没有必要?——有必要!
召回环节的设定是对推荐算法效率和效果综合考虑的产物。
它的任务是从全网的item池中筛选与用户相关的item集合,其目标是拉高推荐算法的上限、提高用户粘性,守住相关性的下界,保障用户拥有一个良好的体验。基于上述两点,我们希望召回具备处理数据量大、模型够快的特点。
因而,这也限定了它不能用太多的特征和太复杂的模型。
主流的召回方法主要有两大类:
基于统计的启发式召回
如协同过滤、swing i2i,利用item 共现性,进行相关召回。
基于深度学习的向量召回方法
如MIND、DSSM、GNN等将user、item表示成向量,利用设定好的距离度量方法,通过向量检索召回top-K item。为了满足不同的业务需求,我们通常会设置多路召回,有针对user冷启动的、针对item冷启动的、针对个性化的等在守住相关性的同时完成其他的业务目标。
所以说,在现有的条件下,舍弃召回环节,直接排序未必是一件容易的事。(此处,仍可参考张俊林的《推荐系统召回四模型之:全能的FM模型》

阅读地址:
https://zhuanlan.zhihu.com/p/58160982
▐ 推荐系统仅有ctr预估打分排序就够了吗?——不够!
首先,对于新的user、item,ctr模型预估未必足够准确,我们需要另外的策略机制去解决冷启动。
其次,把ctr分高的item展示给用户,用户就买账吗?一直看同类型的item用户很快会产生疲劳感。因此根据业务场景的不同,我们有时还要考虑item的多样性,例如通过用MMR、DPP等手段去平衡好相关性和多样性。
最后,实际业务场景中,推荐算法是个多目标优化的任务,除了考虑ctr,还需要考虑停留时长、互动率等指标。
最后总结下,召回和排序两个环节各司其职。
虽然排序,特别是精排,处于整个推荐算法链条的最后一环,方便直接对业务指标发力,加之候选集较小,可以使用复杂模型,如各种NN,各种Attention。而召回处于整个推荐链路的前端,其结果经过粗排、精排、重排的筛选,最终作用于业务指标时,影响力已经大大减弱了,但是召回决定了排序效果的上限,是值得我们好好研究的。
Q:推荐系统中如何做 User Embedding?
豆苗:
推荐系统的主要任务是预测实体间会不会存在某种关系。在大部分以用户为主导的推荐系统中,一般会存在两类实体:user和item,相应的就存在两种实体对:user-user和user-item。
user-user间关系:社交关系、行为相似、兴趣相似等
user-item间关系:点击、收藏、加购、点赞、评论等
针对预测关系的不同,首先要构建描述实体间对应关系的训练数据,其次是选择合适的embedding模型。
常用的embedding模型有:
▐ 传统的MF模型
通过对user-item交互矩阵进行分解,从而获取user和item的embedding。代表性的方法有biasSVD、SVD++、PMF、NMF等,MF模型的优势是实现简单、可扩展性强,预测精度也比较好,但是训练速度慢。具体可参考:张小磊的《推荐系统之矩阵分解家族》

阅读地址:
https://zhuanlan.zhihu.com/p/35262187
▐ 端到端DNN-embedding模型
模型中接入embedding层,通过与目标loss联合训练,得到embedding。例如DSSM、youtube双塔结构、NCF等。
▐ Graph embedding模型
学习node或entire(sub) graph的低维embedding,使得embedding间的关系能够反映原始网络的结构信息。将user和item视为网络中的node,通过node embeding技术得到user/item-embedding。
▐ 浅层模型
在由item-item组成的网络中进行随机游走,产生item序列库。将item序列库当做NLP中语料库作为训练样本输入word2vec进行训练,得到item的embedding。例如:DeepWalk、Node2vec、EGES。具体可参考王喆的《深度学习中不得不学的Graph Embedding方法》

阅读地址:
https://zhuanlan.zhihu.com/p/64200072
▐ 深层模型
目前广泛使用的方法是Graph Convolutional Networks(GCN)。GCN将卷积从图像和NLP领域拓展到Graph Embedding,每个节点单独encode,但encode的时候,会利用卷积操作来汇聚邻域节点的属性信息,并叠加多层网络,形成节点的embedding表示。相比较于浅层模型,卷积核参数或网络的参数是所有节点之间共享的,因此能够有效减少参数量,同时能够泛化到新的节点。例如:GraphSAGE、GAT、NGCF、LightGCN等。更多论文可参考:

阅读地址:
https://github.com/thunlp/GNNPapers
通常情况下,user和item处在相互对等的位置。
所以在建模user-user关系得到user embedding的任务中可尝试将item-item的建模模型迁移过来;在建模user-item关系得到user embedding的任务中,可尝试端到端的双塔模型或异构网络表示模型。
????橙子说
大家还有什么话题想要了解,欢迎评论区留言,我们下期见~
✿ 拓展阅读



作者|豆苗
编辑|橙子君
出品|阿里巴巴新零售淘系技术


这篇关于工业界常用的推荐系统模型有哪些?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





