本文主要是介绍从原理聊JVM(三):详解现代垃圾回收器Shenandoah和ZGC,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一、Shenandoah
Shenandoah一词来自于印第安语,十九世纪四十年代有一首著名的航海歌曲在水手中广为流传,讲述一位年轻富商爱上印第安酋长Shenandoah的女儿的故事。后来美国有一条位于Virginia州西部的小河以此命名,所以Shenandoah的中文译名为“情人渡”。
Shenandoah首次出现在Open JDK12中,是由Red Hat开发,主要为了解决之前各种垃圾回收器处理大堆时停顿较长的问题。
相比较G1将低停顿做到了百毫秒级别,Shenandoah的设计目标是将停顿压缩到10ms级别,且与堆大小无关。它的设计非常激进,很多设计点在权衡上更倾向于低停顿,而不是高吞吐。
“G1的继承者”
Shenandoah是OpenJDK中的垃圾处理器,但相比较Oracle JDK中根正苗红的ZGC,Shenandoah可以说更像是G1的继承者,很多方面与G1非常相似,甚至共用了一部分代码。
总的来说,Shenandoah和G1有三点主要区别:
G1的回收是需要STW的,而且这部分停顿占整体停顿时间的80%以上,Shenandoah则实现了并发回收。
Shenandoah不再区分年轻代和年老代。
Shenandoah使用连接矩阵替代G1中的卡表。
关于G1的详细介绍请翻看前一篇:从原理聊JVM(二):从串行收集器到分区收集开创者G1
连接矩阵(Connection Matrix)
G1中每个Region都要维护卡表,既耗费计算资源还占据了非常大的内存空间,Shenandoah使用了连接矩阵来优化了这个问题。
连接矩阵可以简单理解为一个二维表格,如果Region A中有对象指向Region B中的对象,那么就在表格的第A行第B列打上标记。
比如,Region 1指向Region 3,Region 4指向Region 2,Region 3指向Region 5:
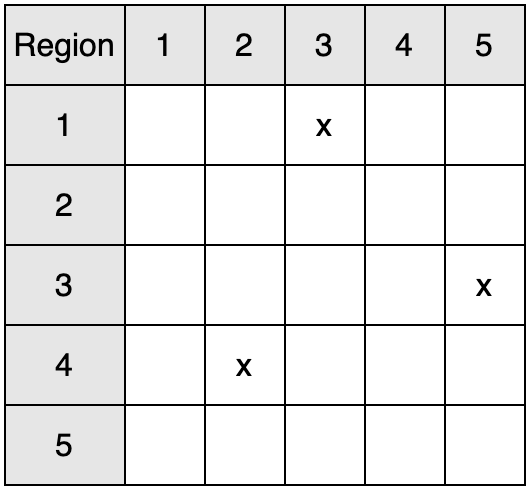
相比G1的记忆集来说,连接矩阵的颗粒度更粗,直接指向了整个Region,所以扫描范围更大。但由于此时GC是并发进行的,所以这是通过选择更低资源消耗的连接矩阵而对吞吐进行妥协的一项决策。
转发指针
转发指针的性能优势
想要达到并发回收,就需要在用户线程运行的同时,将存活对象逐步复制到空的Region中,这个过程中就会在堆中同时存在新旧两个对象。那么如何让用户线程访问到新对象呢?
此前,通常是在旧对象原有内存上设置保护陷阱(Memory Protection Trap),当访问到这个旧对象时就会发生自陷异常,使程序进入到预设的异常处理器中,再由处理器中的代码将访问转发到复制后的新对象上。
自陷是由线程发起来打断当前执行的程序,进而获得CPU的使用权。这一操作通常需要操作系统参与,那么就会发生用户态到内核态的转换,代价十分巨大。
所以Rodney A.Brooks提出了使用转发指针来实现通过旧对象访问新对象的方式:在对象头前面增加一个新的引用字段,在非并发移动情况下指向自己,产生新对象后指向新对象。那么当访问对象的时候,都需要先访问转发指针看看其指向哪里。虽然和内存自陷方案相比同样需要多一次访问转发的开销,但是前者消耗小了很多。
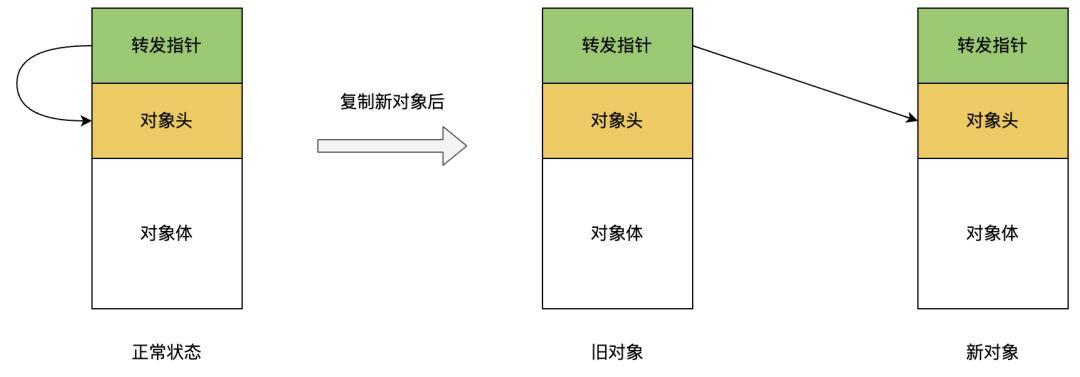
转发指针的问题
转发指针主要存在两个问题:修改时的线程安全问题和高频访问的性能问题。
对象体增加了一个转发指针,这个指针的修改和对象本身的修改就存在了线程安全问题。如果通过被访问就可能发生复制了新对象后,转发对象修改之前发生了旧对象的修改,这就存在两个对象不一致的问题了。对于这个问题,Shenandoah是通过CAS操作来保证修改正确性的。
转发指针的加入需要覆盖所有对象访问的场景,包括读、写、加锁等等,所以需要同时设置读屏障和写屏障。尤其读操作相比单纯写操作出现频率更高,这样高频操作带来的性能问题影响巨大。所以Shenandoah在JDK13中对此进行了优化,将内存屏障模型改为引用访问屏障,也就是说,仅仅在对象中引用类型的读写操作增加屏障,而不去管原生对象的操作,这就省去了大量的对象访问操作。
Shenandoah的运行步骤
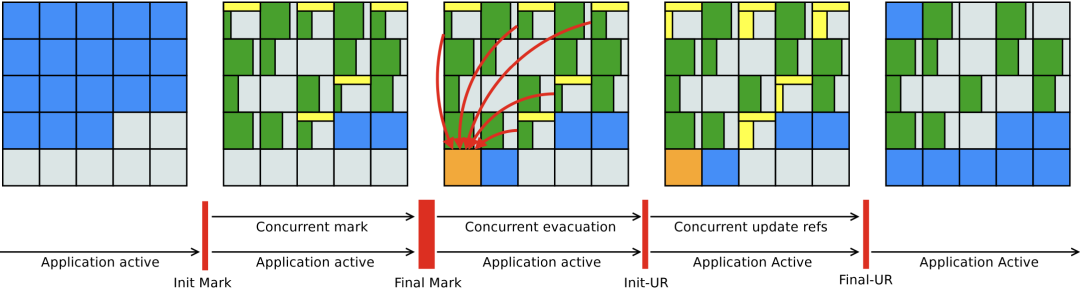
1. 初始标记(Init Mark)[STW] [同G1]
标记与GC Roots直接关联的对象。
2. 并发标记(Concurrent Marking)[同G1]
遍历对象图,标记全部可达对象。
3. 最终标记(Final Mark)[STW] [同G1]
处理剩余的SATB扫描,并在这个阶段统计出回收价值最高的Region,将这些Region构成一组回收集。
4. 并发清理(Concurrent Cleanup)
回收所有不包含任何存活对象的Region(这类Region被称为Immediate Garbage Region)。
5. 并发回收(Concurrent Evacuation)
将回收集里面的存货对象复制到一个其他未被使用的Region中。并发复制存活对象,就会在同一时间内,同一对象在堆中存在两份,那么就存在该对象的读写一致性问题。Shenandoah通过使用转发指针将旧对象的请求指向新对象解决了这个问题。这也是Shenandoah和其他GC最大的不同。
6. 初始引用更新(Init Update References)[STW]
并发回收后,需要将所有指向旧对象的引用修正到新对象上。这个阶段实际上并没有实际操作,只是设置一个阻塞点来保证上述并发操作均已完成。
7. 并发引用更新(Concurrent Update References)
顺着内存物理地址线性遍历堆空间,更新并发回收阶段复制的对象的引用。
8. 最终引用更新(Final Update References)[STW]
堆空间中的引用更新完毕后,最后需要修正GC Roots中的引用。
9. 并发清理(Concurrent Cleanup)
此时回收集中Region应该全部变成Immediate Garbage Region了,再次执行并发清理,将这些Region全部回收。
二、ZGC
ZGC是Oracle官方研发并JDK11中引入,并于JDK15中作为生产就绪使用,其设计之初定义了三大目标:
支持TB级内存
停顿控制在10ms以内,且不随堆大小增加而增加
对程序吞吐量影响小于15%
随着JDK的迭代,目前JDK16及以上版本,ZGC已经可以实现不超过1毫秒的停顿,适用于堆大小在8MB到16TB之间。
ZGC的内存布局
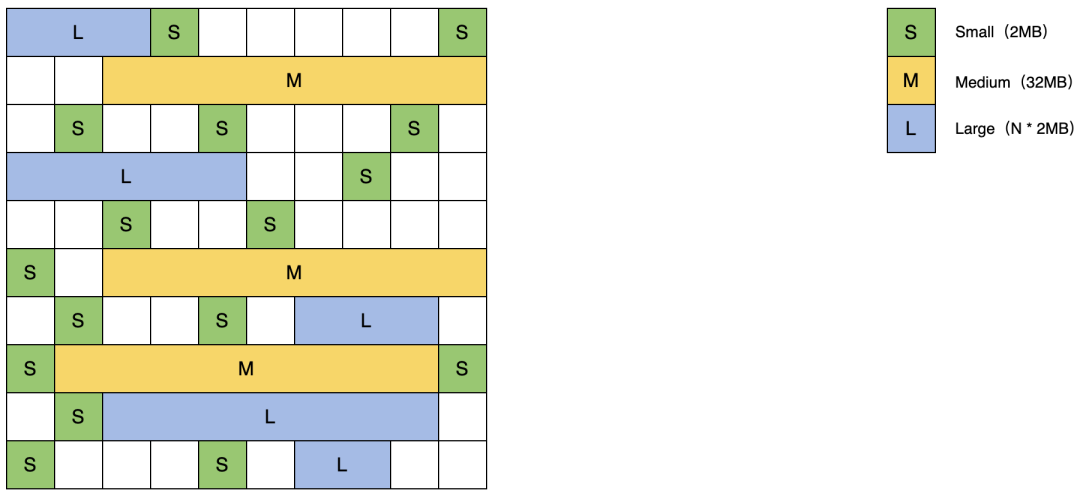
ZGC和G1一样也采用了分区域的堆内存布局,不同的是,ZGC的Region(官方称为Page,概念同G1的Region)可以动态创建和销毁,容量也可以动态调整。
ZGC的Region分为三种:
小型Region容量固定为2MB,用于存放小于256KB的对象。
中型Region容量固定为32MB,用于存放大于等于256KB但不足4MB的对象。
大型Region容量为2MB的整数倍,存放4MB及以上大小的对象,而且每个大型Region中只存放一个大对象。由于大对象移动代价过大,所以该对象不会被重分配。
重分配集(Relocation Set)
G1中的回收集用来存放所有需要G1扫描的Region,而ZGC为了省去卡表的维护,标记过程会扫描所有Region,如果判定某个Region中的存活对象需要被重分配,那么就将该Region放入重分配集中。
通俗的说,如果将GC分为标记和回收两个主要阶段,那么回收集是用来判定标记哪些Region,重分配集用来判定回收哪些Region。
染色指针
和Shenandoah相同,ZGC也实现了并发回收,不同的是前者是使用转发指针来实现的,后者则是采用染色指针的技术来实现。
三色标记本质上与对象无关,仅仅与引用有关:通过引用关系判定对像存活与否。HotSpot虚拟机中不同垃圾回收器有着不同的处理方式,有些是标记在对象头中,有些是标记在单独的数据结构中,而ZGC则是直接标记在指针上。
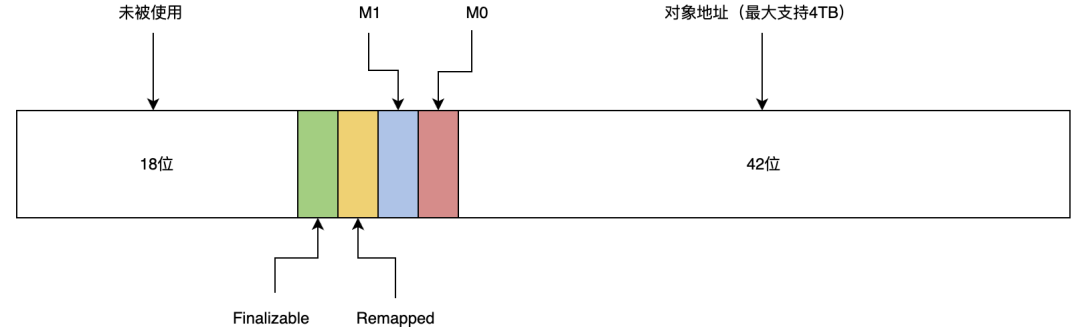
64位机器指针是64位,Linux下64位中高18位不能用来寻址,剩下46位中,ZGC选择其中4位用来辅助GC工作,另外42位能够支持最大内存为4T,通常来说,4T的内存完全够用。
具体来说,ZGC在指针中增加了4个标志位,包括Finalizable、Remapped、Marked 0和Marked 1。
源码注释如下:
6 4 4 4 4 4 03 7 6 5 2 1 0
+-------------------+-+----+-----------------------------------------------+
|00000000 00000000 0|0|1111|11 11111111 11111111 11111111 11111111 11111111|
+-------------------+-+----+-----------------------------------------------+
| | | |
| | | * 41-0 Object Offset (42-bits, 4TB address space)
| | |
| | * 45-42 Metadata Bits (4-bits) 0001 = Marked0
| | 0010 = Marked1
| | 0100 = Remapped
| | 1000 = Finalizable
| |
| * 46-46 Unused (1-bit, always zero)
|
* 63-47 Fixed (17-bits, always zero)Finalizable标识表示对象是否只能通过finalize()方法访问到,Remapped、Marked 0和Marked 1用作三色标记(后面简称为M0和M1)。
为什么既有M0还有M1呢?
因为ZGC标记完成后并不需要等待对象指针重映射就可以进行下一次垃圾回收循环,也就是说两次垃圾回收的全过程是有重叠的,所以使用两个标记位分别用作两次相邻GC过程的标记,M0和M1交替使用。
染色指针的在GC过程中的作用
我们通过红蓝黄三个颜色分别表示三种标记状态:

1.第一次标记开始时所有的指针都处于Remapped状态
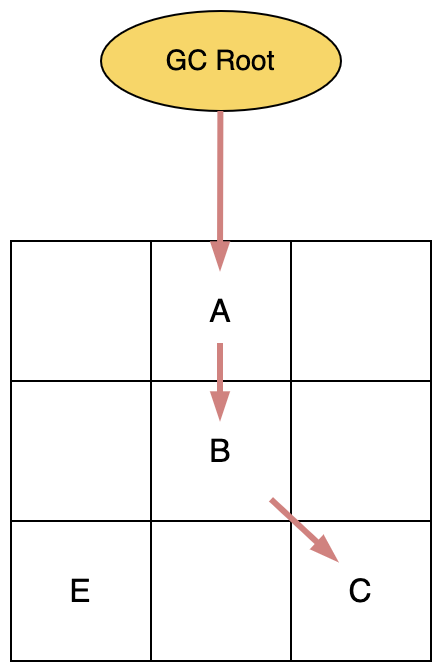
2. 从GC Root开始,顺着对象图遍历扫描,存活对象标记为M0
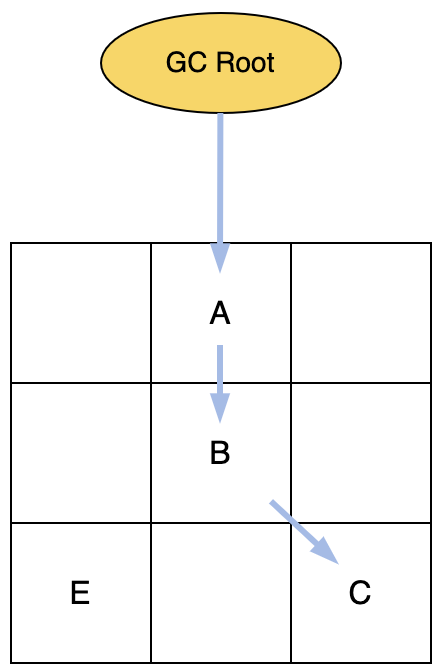
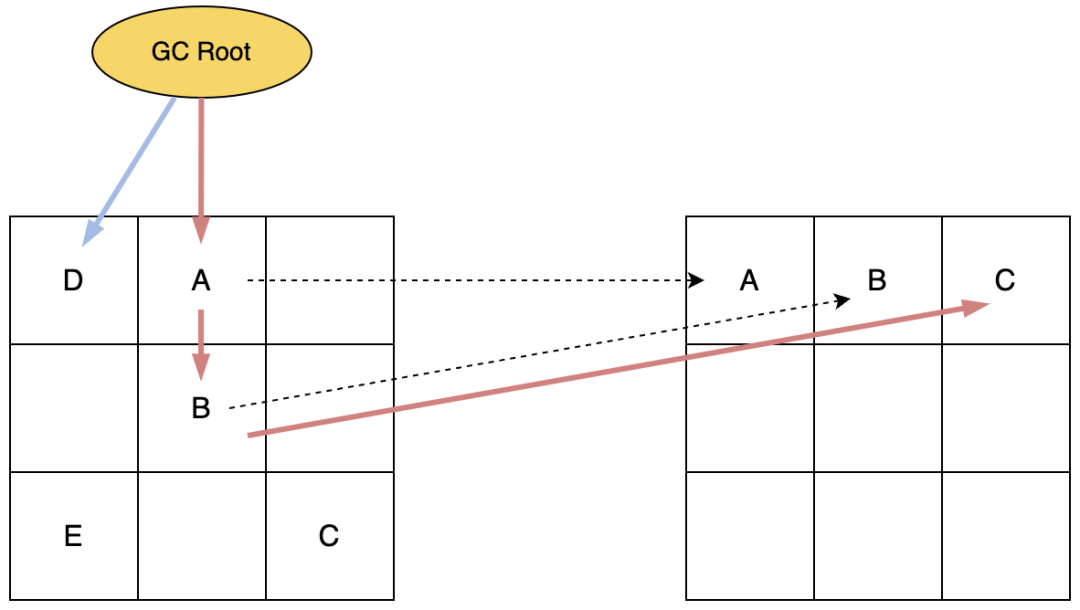
3. 标记完成后,开始进行并发重分配。最终目标是将A、B、C三个存活对象都移动到新的Region中去。
整个标记过程中新分配到对象都被直接标记为M0,比如对象D。
复制完成的对象,指针就可以由M0改为Remapped,并将旧对象到新对象到映射关系保存到转发表中。
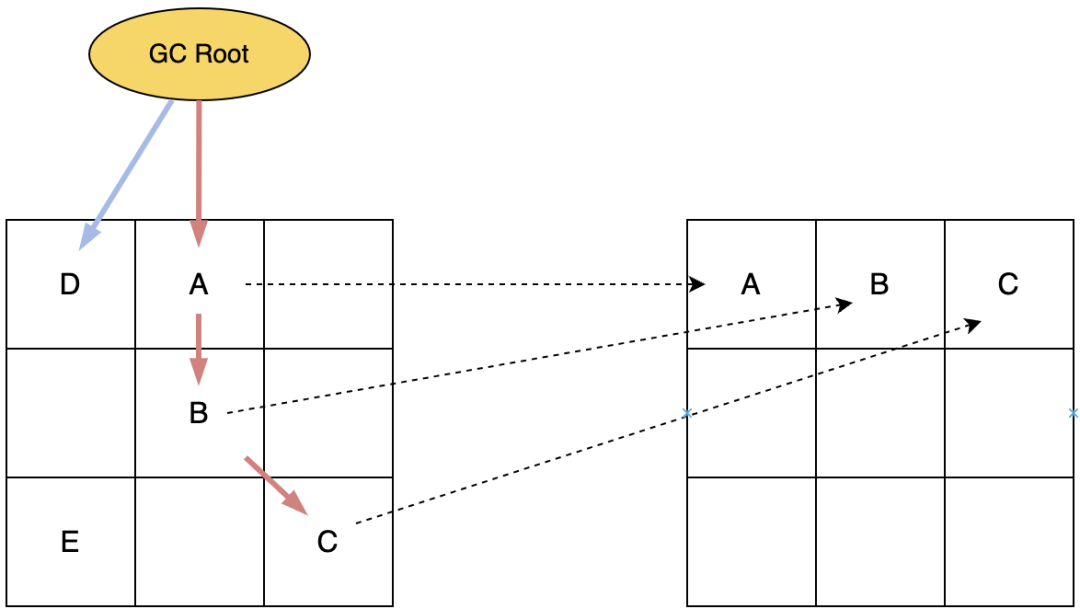
4. 如果此时系统访问对象C,会触发读屏障,将原引用修正到新的对象C的地址上去,并转发访问,最后删除转发表的记录。
这个行为称为指针的“自愈”。
实际上,如果没有对象D的存在,在上一步所有存货对象转移完成后,旧的Page就可以被回收了,依靠指针和转发表就可以将所有访问转发到新的Page中去。
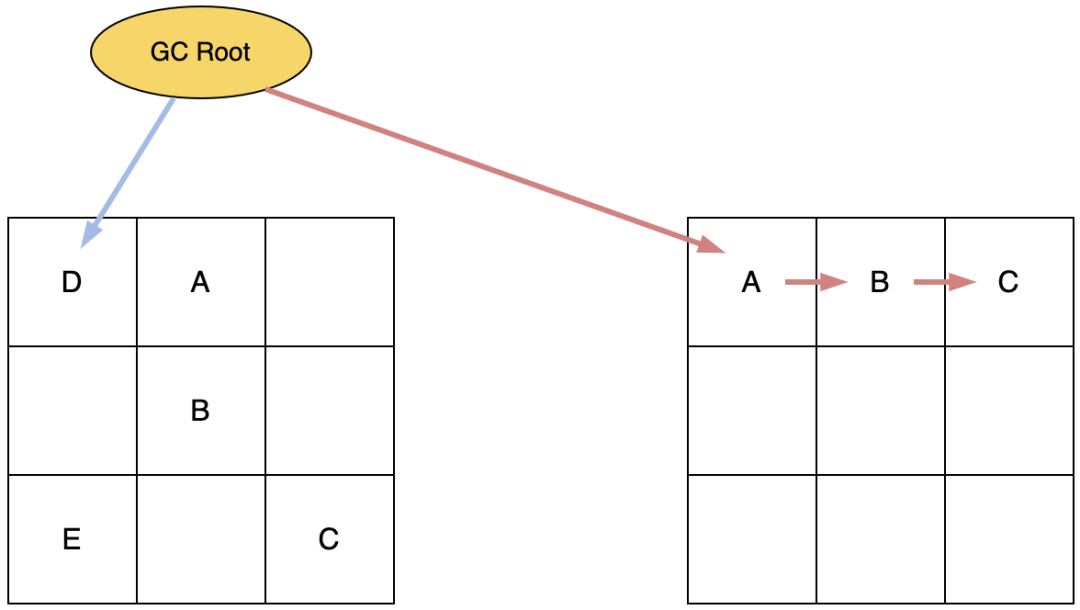
5. 并发重映射阶段会把所有引用修正,并删除转发表的记录。
6. 下一次并发标记开始后,由于上一次垃圾回收循环并没有完成,所以Remapped指针被标记为M1,用来和上一次的存活对象标记作区分。
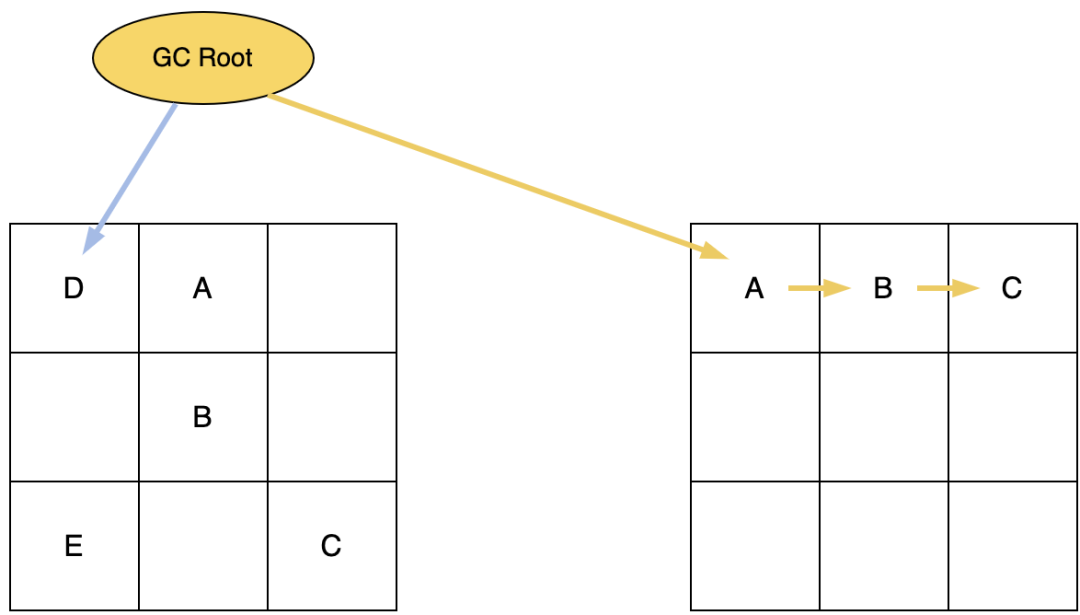
可以看出,并发标记的过程中,ZGC是通过读屏障来保证访问的正确转发,并且由于染色指针采用惰性更新的策略,相比Shenandoah每次都要先访问转发指针的两次寻址来说快上不少。
染色指针的三大优点
由于染色指针提供的“自愈”能力,当某个Page被清除后可以立刻被回收,而无需等待修正全部指向该Page的引用。
ZGC完全不需要使用写屏障,原因有二:由于使用染色指针,无需更新对象体;没有分代所以无需记录跨代引用。
染色指针并未完全开发使用,剩下的18位提供了非常大的扩展性。
而染色指针有一个天然的问题,就是操作系统和处理器并不完全支持程序对指针的修改。
多种内存映射
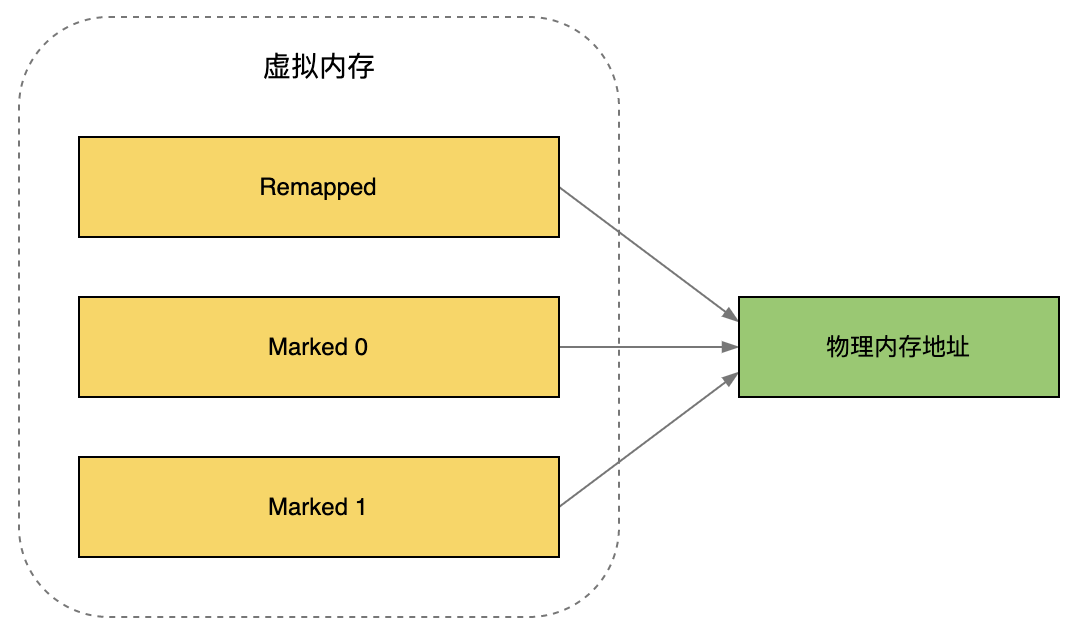
染色指针只是JVM定义的,操作系统、处理器未必支持。为了解决这个问题,ZGC在Linux/x86-64平台上采用了虚拟内存映射技术。
ZGC为每个对象都创建了三个虚拟内存地址,分别对应Remapped、Marked 0和Marked 1,通过指针指向不同的虚拟内存地址来表示不同的染色标记。
分代
ZGC没有分代,这一点并不是技术权衡,而是基于工作量的考虑。所以目前来看,整体的GC效率还有很大提升空间。
读屏障
ZGC使用了读屏障来完成指针的“自愈”,由于ZGC目前没有分代,且ZGC通过扫描所有Region来省去卡表使用,所以ZGC并没有写屏障,这成为ZGC一大性能优势。
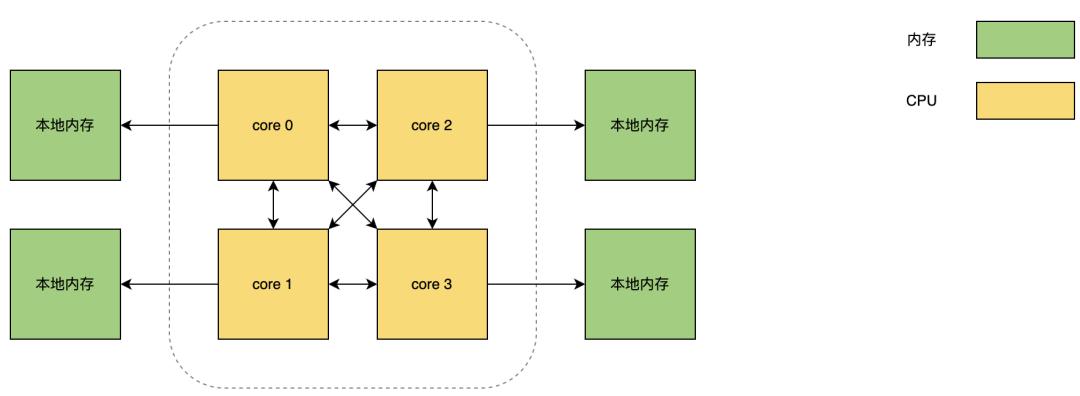
NUMA
多核CPU同时操作内存就会发生争抢,现代CPU把内存控制系统器集成到处理器内核中,每个CPU核心都有属于自己的本地内存。
在NUMA架构下,ZGC会有现在自己的本地内存上分配对象,避免了内存使用的竞争。
在ZGC之前,只有Parallet Scavenge支持NUMA内存分配。
ZGC的运行步骤
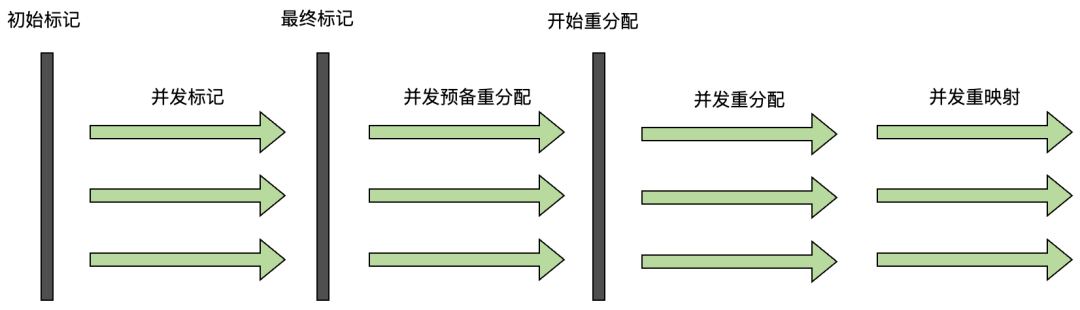
ZGC和Shenadoah一样,几乎所有运行阶段都和用户线程并发进行。其中同样包含初始标记、重新标记等STW的过程,作用相同,不再赘述。重点介绍以下四个并发阶段:
并发标记
并发标记阶段和G1相同,都是遍历对象图进行可达性分析,不同的是ZGC的标记在染色指针上。
并发预备重分配
在这个阶段,ZGC会扫描所有Region,如果哪些Region里面的存活对象需要被分配的新的Region中,就将这些Region放入重分配集中。
此外,JDK12后ZGC的类卸载和弱引用的处理也在这个阶段。
并发重分配
ZGC在这个阶段会将重分配集里面的Region中的存货对象复制到一个新的Region中,并为重分配集中每一个Region维护一个转发表,记录旧对象到新对象的映射关系。
如果在这个阶段用户线程并发访问了重分配过程中的对象,并通过指针上的标记发现对象处于重分配集中,就会被读屏障截获,通过转发表的内容转发该访问,并修改该引用的值。
ZGC将这种行为称为自愈(Self-Healing),ZGC的这种设计导致只有在访问到该指针时才会触发一次转发,比Shenandoah的转发指针每次都要转发要好得多。
另一个好处是,如果一个Region中所有对象都复制完毕了,该Region就可以被回收了,只要保留转发表即可。
并发重映射
最后一个阶段的任务就是修正所有的指针并释放转发表。
这个阶段的迫切性不高,所以ZGC将并发重映射合并到在下一次垃圾回收循环中的并发标记阶段中,反正他们都需要遍历所有对象。
三、总结
现代的垃圾回收器为了低停顿的目标可谓将“并发”二字玩到极致,Shenandoah在G1基础上做了非常多的优化来使回收阶段并行,而ZGC直接采用了染色指针、NUMA等黑科技,目的都是为了让Java开发者可以更多的将精力放在如何使用对象让程序更好的运行,剩下的一切交给GC,我们所做的只需享受现代化GC技术带来的良好体验。
参考资料:
[1] OpenJDK 17 中的 Shenandoah:亚毫秒级 GC 停顿【译】 - 知乎 (zhihu.com)
[2] https://shipilev.net/talks/devoxx-Nov2017-shenandoah.pdf
[3] https://openjdk.java.net/jeps/333
-end-
这篇关于从原理聊JVM(三):详解现代垃圾回收器Shenandoah和ZGC的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








