本文主要是介绍使用read_html爬取网页表哥,简单又强大的pandas爬虫 利用pandas库的read_html()方法爬取网页表格型数据...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、简介
一般的爬虫套路无非是发送请求、获取响应、解析网页、提取数据、保存数据等步骤。构造请求主要用到requests库,定位提取数据用的比较多的有xpath和正则匹配。一个完整的爬虫,代码量少则几十行,多则百来行,对于新手来说学习成本还是比较高的。
谈及pandas的read.xxx系列的函数,常用的读取数据方法为:pd.read_csv() 和 pd.read_excel(),而 pd.read_html() 这个方法虽然少用,但它的功能非常强大,特别是用于抓取Table表格型数据时,简直是个神器。无需掌握正则表达式或者xpath等工具,短短的几行代码就可以将网页数据快速抓取下来并保存到本地。
二、原理
pandas适合抓取Table表格型数据,先了解一下具有Table表格型数据结构的网页,举例如下:
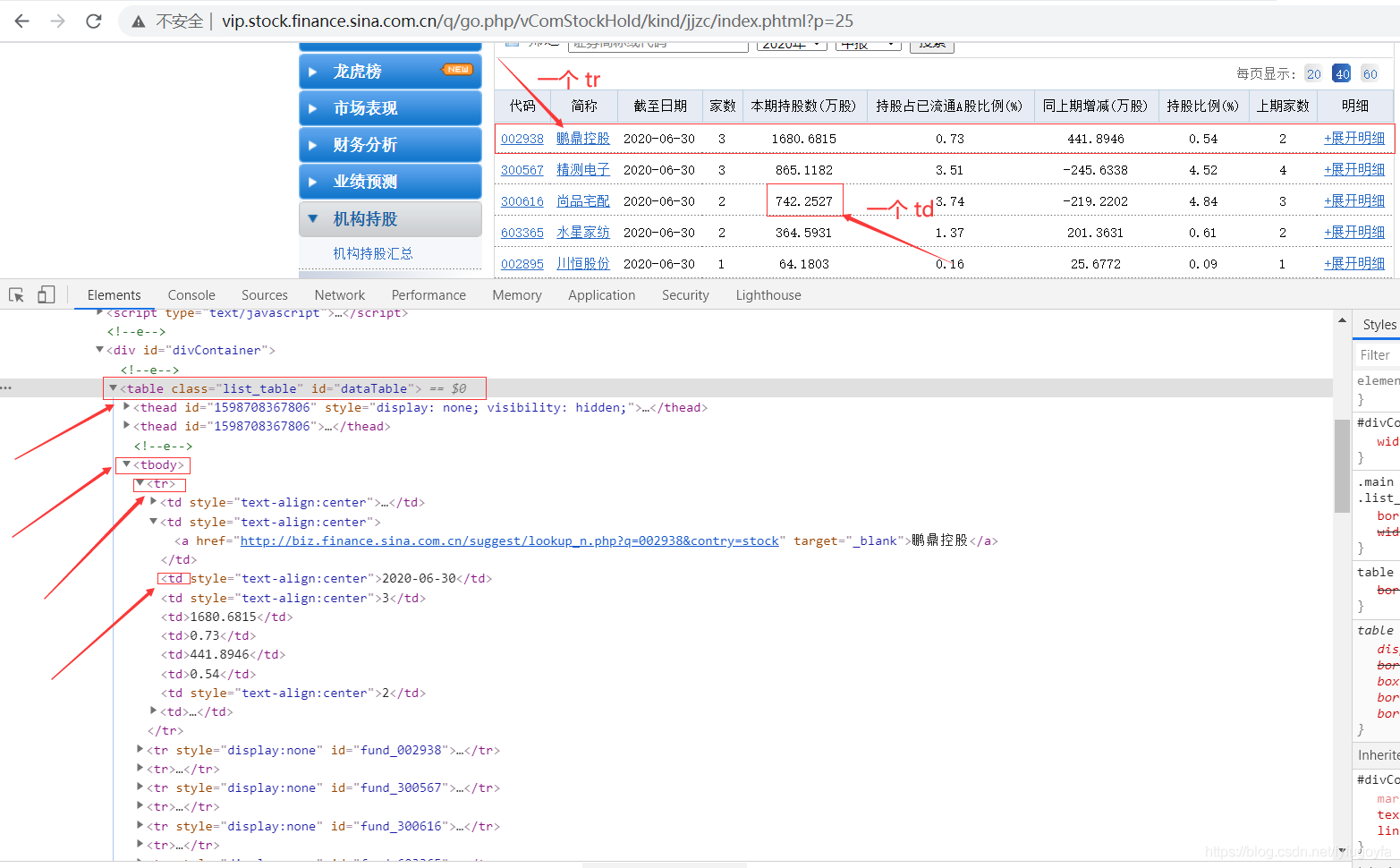
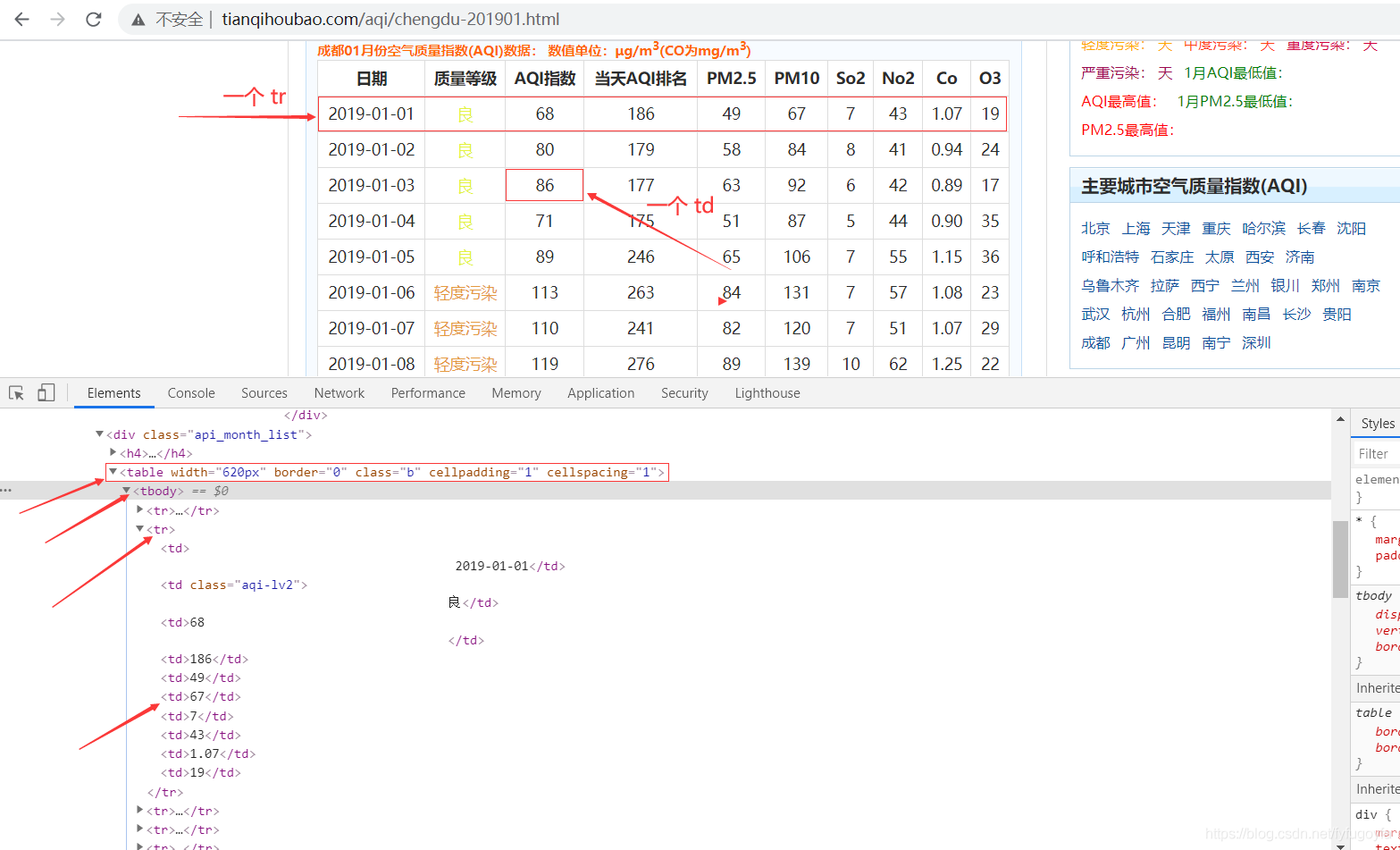
用Chrome浏览器查看网页HTML结构,会发现Table表格型数据有一些共同点,大致的网页结构如下表示。
...
..................
......1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
网页具有以上结构,我们可以尝试用pandas的 pd.read_html() 方法来直接获取数据。

pd.read_html() 的一些主要参数
io:接收网址、文件、字符串
header:指定列名所在的行
encoding:The encoding used to decode the web page
attrs:传递一个字典,用其中的属性筛选出特定的表格
parse_dates:解析日期
三、爬取实战
实例1
import pandas as pd
dates = pd.date_range('20190101', '20191201', freq='MS').strftime('%Y%m') # 构造出日期序列 便于之后构造url
for i in range(len(dates)):
df = pd.read_html(f'http://www.tianqihoubao.com/aqi/chengdu-{dates[i]}.html', encoding='gbk', header=0)[0]
if i == 0:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False) # 追加写入
i += 1
else:
df.to_csv('2019年成都空气质量数据.csv', mode='a+', index=False, header=False)
1
2
3
4
5
6
7
8
9
10
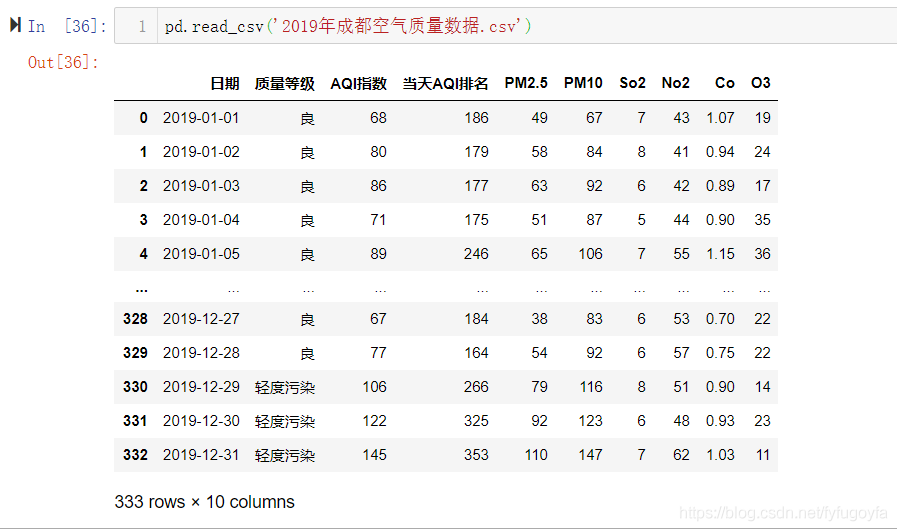
9行代码搞定,爬取速度也很快。
查看保存下来的数据
实例2
import pandas as pd
df = pd.DataFrame()
for i in range(1, 26):
url = f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={i}'
df = pd.concat([df, pd.read_html(url)[0].iloc[::,:-1]]) # 合并DataFrame 不要明细那一列
df.to_csv('新浪财经基金重仓股数据.csv', encoding='utf-8', index=False)
1
2
3
4
5
6
7
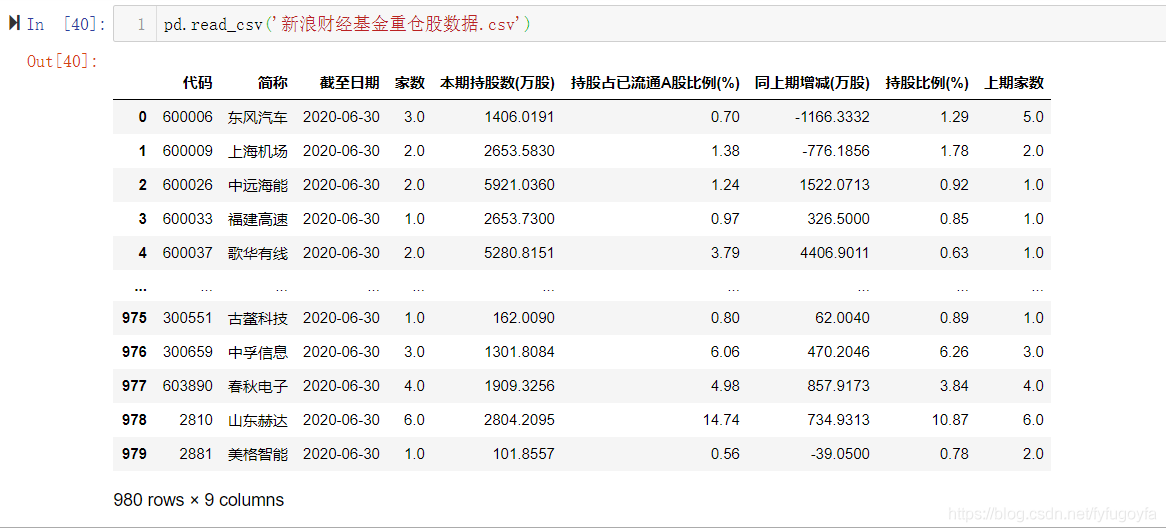
6行代码搞定,爬取速度也很快。
查看保存下来的数据:
之后在爬取一些小型数据时,只要遇到这种Table表格型数据,就可以先试试 pd.read_html() 大法。
这篇关于使用read_html爬取网页表哥,简单又强大的pandas爬虫 利用pandas库的read_html()方法爬取网页表格型数据...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




