上一篇介绍了单机版的搭建,现在来介绍集群版的搭建
什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud满足这些需求。
SolrCloud不同于redis集群自带集群,SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
SolrCloud结构 SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基与zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
下图是一个SolrCloud应用的例子:
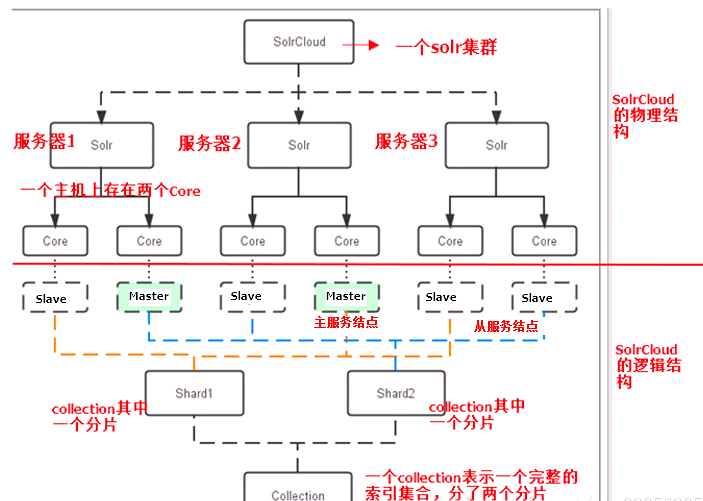
物理结构:
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
逻辑结构:
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
core:
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
Master&Slave:
Master是master-slave构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的
SolrCloud搭建
1.先从hadoop-001复制已经配置好的Tomcat和solrhome到hadoop-002,hadoop-003,如下图


搭建环境
OS:CentOS 6.5
JDK:jdk 1.8.0
Tomcat:tomcat 8.5
zookeeper:zookeeper 3.4.6
solr:solr 7.7.2
让每一台solr和zookeeper关联:
修改每一份solr的tomcat的bin目录下的catalina.sh文件,加入DzkHost指定zookeeper服务器地址,将zookeeper地址列表作为参数传过去:
JAVA_OPTS="-DzkHost=hadoop-001:2181,hadoop-003:2181,hadoop-002:2181"
注:JAVA_OPTS赋值的位置一定要放在引用该变量之前,可以使用vim查找功能查找到JAVA_OPTS的定义位置,然后添加
分别对hadoop-001、hadoop-002、hadoop-003,修改solrhome中的solr.xml!!!!!!!!!!!巨坑
<str name="host">${host:hadoop-001}</str>
<int name="hostPort">8080</int>
<str name="hostContext">${hostContext:solr}</str>

访问solrCloud
访问集群中的任意一台solr均可,可以看到相较于单机版,多了一个Cloud:

在solrhome下·建立new_core文件夹
把/home/hadoop/solr-7.7.2/server/solr/configsets/_default/conf复制到该文件夹下面
cp -r /home/hadoop/solr-7.7.2/server/solr/configsets/_default/conf /home/hadoop/solrhome/new_core

在solrconfig.xml上添加如下配置
<requestHandler name="/dataimport" class="solr.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
新建data-config.xml文件如下
<?xml version="1.0" encoding="UTF-8" ?><dataConfig><dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://hadoop-001:3306/solr" user="root" password="123456" /><document><entity name="product" query="select * from product"><field column="pid" name="id" /><field column="pname" name="pname" /><field column="catalog" name="catalog" /><field column="catalog_name" name="catalog_name" /><field column="price" name="price" /><field column="description" name="description" /> <field column="picture" name="picture" /></entity> </document> </dataConfig>
在managed-schema上添加以下配置
<!-- Product --><!--配置从数据库导入到sorl中的数据的字段内容,所以每次要从数据库导入什么就需要配置什么--><field name="pname" type="text_ik" indexed="true" stored="true"/><field name="price" type="pfloat" indexed="true" stored="true"/><field name="description" type="text_ik" indexed="true" stored="false"/><field name="picture" type="string" indexed="false" stored="true"/><field name="catalog_name" type="string" indexed="true" stored="true"/><field name="keywords" type="text_ik" indexed="true" stored="false" multiValued="true" /><copyField source="pname" dest="keywords" /><copyField source="description" dest="keywords" />
solrCloud集群配置
使用zookeeper统一管理solr配置文件:
使用zookeeper统一管理solr的配置文件(主要是schema.xml、solrconfig.xml),solrCloud各各节点使用zookeeper管理的配置文件,由于这里是直接复制的之前单机版配置好的solrhome(添加了一个中文分词器,定义了业务域)所以配置文件就不需要再修改了,直接交给zookeeper管理就好了。
进入/home/hadoop/solr-7.7.2/server/scripts/cloud-scripts目录下:
/home/hadoop/solr-7.7.2/server/scripts/cloud-scripts/zkcli.sh -zkhost hadoop-001:2181,hadoop-002:2181,hadoop-003:2181 -cmd upconfig -confdir /home/hadoop/solrhome/new_core/conf -confname productconf

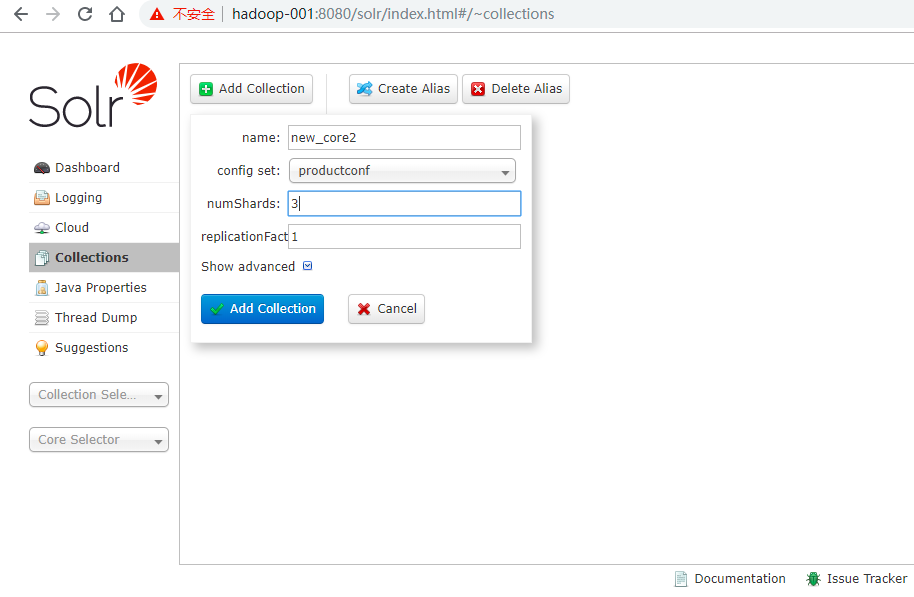
如下图,即可创建collection
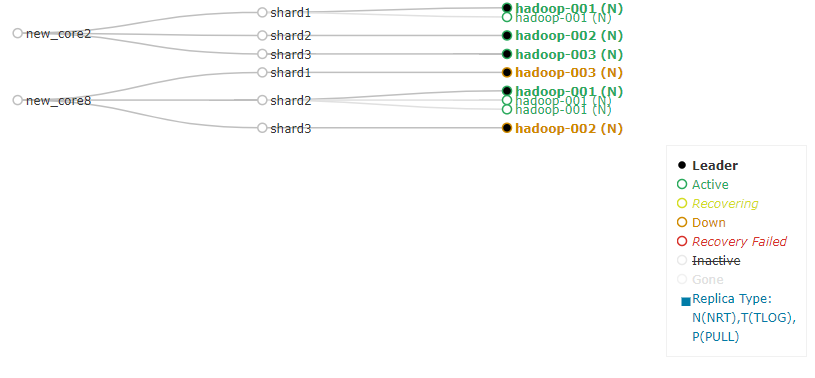
如下图·,关于new_core2,有三个shard分片,而shard1有一个主节点和一个备份节点
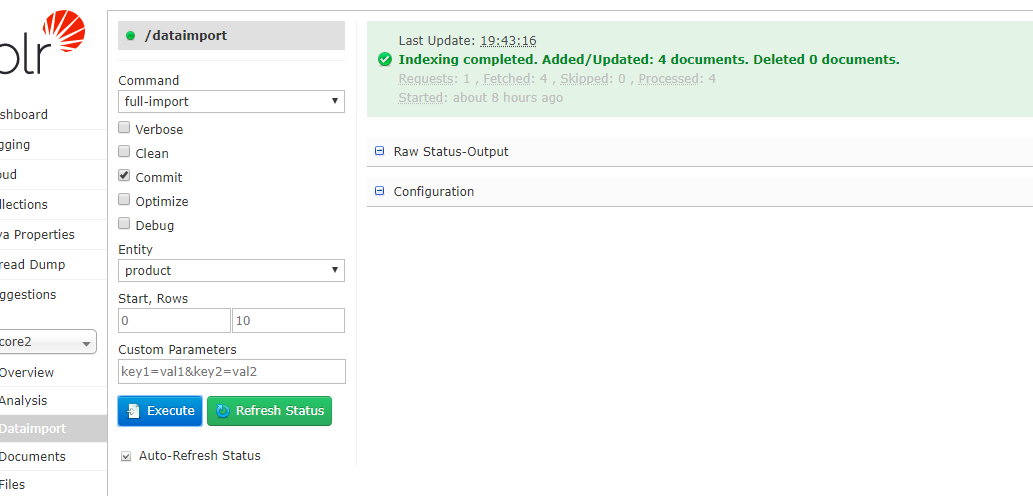
进行DIH操作
数据库数据文件如下
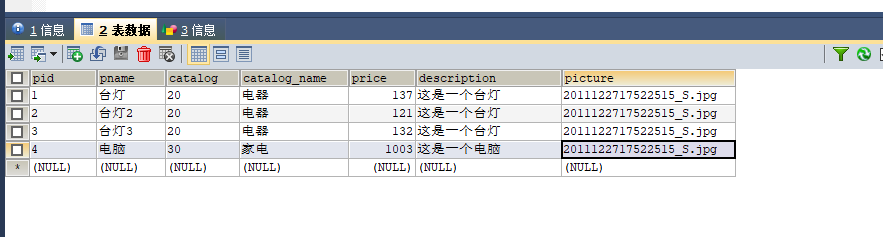
导入数据
查询如下: