本文主要是介绍Learning to Learn: 点击率预测模型与网络结构搜索相结合的研究进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
© 作者|田震
研究方向 | 推荐系统
深度学习技术的发展为点击率预测任务带来了巨大变革,并且在商品推荐、计算广告等工业场景中取得了丰富成果。然而,基于深度学习的CTR模型在提升预测表现的同时需要消耗更多的计算资源,冗余结构的存在也严重限制了模型表现的进一步提升。基于此,研究者重新聚焦于特征工程与模型结构优化,利用网络结构搜索技术设计了兼具表现与性能的CTR模型。笔者整理了近两年顶级会议与arXiv上的相关工作,文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
引言
在过去的发展历程中,CTR模型通过引入DNN,CIN,CrossNet等结构构造复杂的高阶交互特征显著地提升了模型预测的效果,并且在工业界取得了丰富的成果。然而,单纯地追求构造更加复杂的交互特征并不能持续地提高模型的预测表现,基于深度学习的点击率预测模型已经达到了瓶颈期,其面临的主要问题可以归结如下:
1. 性能问题:实时的工业推荐场景要求模型具有较低的时延来维持高QPS,而如XDeepFM等深度模型具有较高的计算复杂度而不能满足此类实时推荐任务。
2. 噪声问题:传统的CTR模型通过人工设计特征表示与特征交互结构,而这些模型往往存在较多的冗余结构,这些冗余结构不仅会浪费计算资源而且还会严重地降低模型的预测效果。模型的冗余结构主要来源于:
特征表示:传统的CTR模型为所有的特征赋予相同的embedding维数,这种处理方式具有明显缺陷:从特征粒度来看,特征往往呈现长尾分布,对低频特征使用高维度向量表示会导致过拟合;从特征域粒度来看,不同的特征域的特征基数差异非常大,对基数较小的特征域用高维度向量表示同样会导致过拟合。
特征交互:人工设计的CTR模型往往通过枚举的方式构造高阶交互特征,这种方式往往会引入大量的无关交互特征,这些冗余的交互特征会严重影响模型的预测表现。
基于此,近年来研究者重新聚焦于特征工程。通过NAS技术减少模型的冗余度来提高复杂模型的性能成为新的发展趋势。
笔者整理了近两年NAS技术结合点击率预测模型的部分研究进展,涵盖了特征表示搜索、特征交互搜索以及模型结构搜索等搜索类型,欢迎大家批评和交流!
论文解读
1. Neural input search for large scale recommendation models. (KDD 2020)
本文来自于谷歌,是特征表示搜索的开山之作。该工作提出了一种利用强化学习优化推荐模型的输入特征表示模块的方法,自动学习特征域的最优特征集合以及每个特征的最优embedding维数。该方法能够有效减少模型空间消耗并且提高模型表现。
本文首先指出特征表示与特征出现频率息息相关,如果为出现频率较低的特征分配较多的embedding维数不仅会导致降低模型的收敛速度还会导致模型过拟合,因此为所有特征分配统一的embedding维数(Single-size Embedding,SE)是十分低效的。基于此,本文提出了一种新的Embedding Layer结构,称为Multi-size Embedding(ME),ME为那些出现频率较高的特征分配较大的embedding size,而为出现频率较低的特征分配较小的embedding size。
该方法对于每个特征域首先按照特征的出现频率降序排列,并且提出了MES的数据结构对embedding table进行划分。具体来说,MES可以表示为一个序列: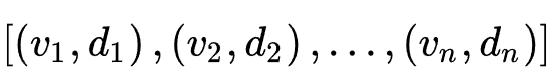 ,表示前
,表示前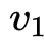 个特征的embedding size为
个特征的embedding size为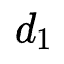
,第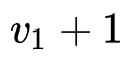 至第
至第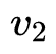 个特征的embedding size为
个特征的embedding size为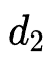 ,以此类推。并且保证
,以此类推。并且保证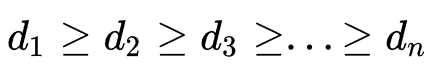 来保证对高频出现的特征分配较大的embedding size。
来保证对高频出现的特征分配较大的embedding size。
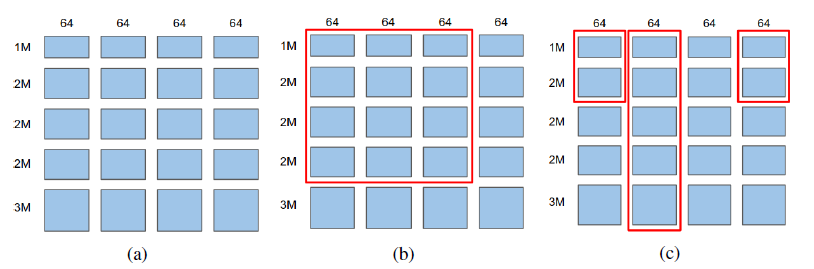
搜索空间:本文对原始embedding table进行分块处理,如上图(a)所示,将规模为10M*256的embedding table分为20个block。在此处理下,controller选择的一个SE子结构(图中红色矩形框)可以表示为一个序偶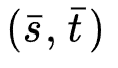 ,表示block
,表示block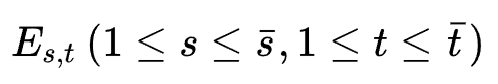 被选中,如上图(b)所示,选择表示为(4, 3)。而对于ME,controller的选择可以表示为长度为
被选中,如上图(b)所示,选择表示为(4, 3)。而对于ME,controller的选择可以表示为长度为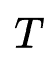 (划分block的列数)的序列,如上图(c)所示,选择表示为[2, 5, 0, 2]。由于最终的特征交互网络的输入为一个固定长度的embedding,因此,本文对于不同的矩形区域设置了投影矩阵来统一embedding维度。可以看到,无论是SE还是ME,每一个选择表示都对应着一个唯一的MES,例如图(b)为
(划分block的列数)的序列,如上图(c)所示,选择表示为[2, 5, 0, 2]。由于最终的特征交互网络的输入为一个固定长度的embedding,因此,本文对于不同的矩形区域设置了投影矩阵来统一embedding维度。可以看到,无论是SE还是ME,每一个选择表示都对应着一个唯一的MES,例如图(b)为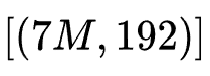 ,图(c)为
,图(c)为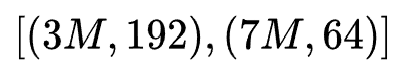 。
。
Reward:本文将奖励函数表示为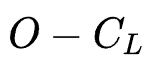 。其中
。其中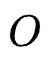 代表模型表现,对于召回任务,
代表模型表现,对于召回任务, 可以为Sampled Recall@1;对于排序任务,
可以为Sampled Recall@1;对于排序任务,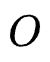 可以为AUC。而
可以为AUC。而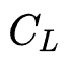 代表内存代价。假设给定的存储负载为
代表内存代价。假设给定的存储负载为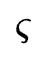 ,embedding table的参数量为
,embedding table的参数量为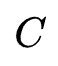 ,那么
,那么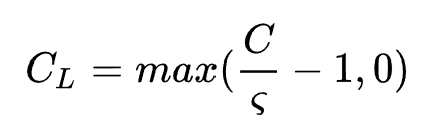 。
。
通过这种定义可以在保证满足内存负载要求的情况下(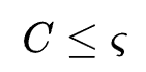 ) 搜索最佳的特征表示。最终作者采用A3C算法训练controller,最终模型对比基线模型在召回任务提升了6.8%的Recall@1,在排序任务提升了1.8%的AUC。
) 搜索最佳的特征表示。最终作者采用A3C算法训练controller,最终模型对比基线模型在召回任务提升了6.8%的Recall@1,在排序任务提升了1.8%的AUC。
2. AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations. (ICDM 2021)
本文主要探索用户与物品出现频率(即流行度)与embedding size的关系,提出了利用DARTS技术搜索每个用户和物品最佳embedding表示的方法。
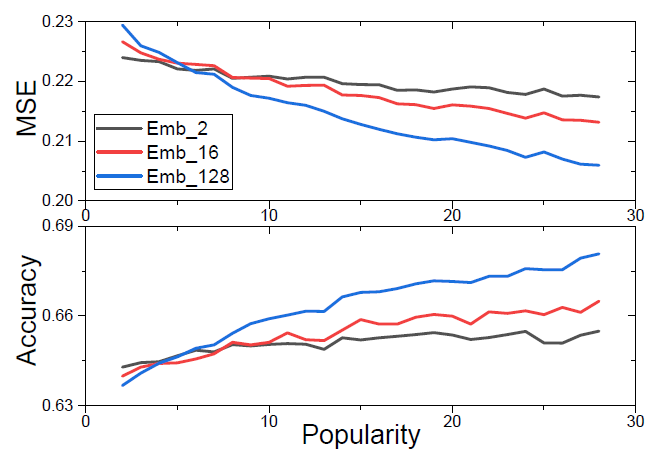
作者首先通过实验说明了高流行度的特征适合维度较大的embedding表示,而低流行度的特征适合维度较小的embedding表示。因此,用户和物品的流行度是决定特征embedding维数的重要因素。
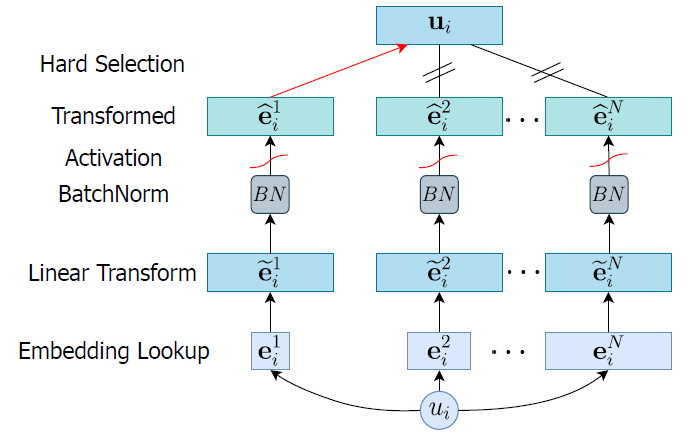
搜索结构如图所示,作者为每个user设置N个候选embedding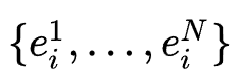 ,它们的维度满足
,它们的维度满足 。由于后续的特征交互结构要求所有的embedding具有相同维度,这里需要统一所有的候选embedding维度,具体做法是对所有候选embedding做投影操作:
。由于后续的特征交互结构要求所有的embedding具有相同维度,这里需要统一所有的候选embedding维度,具体做法是对所有候选embedding做投影操作: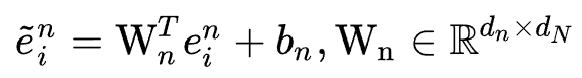 。作者发现经过投影之后的embedding往往变化的幅度非常大,因此这里对其作batch normalization进行归一化,并且经过tanh激活后得到最终的候选embedding序列
。作者发现经过投影之后的embedding往往变化的幅度非常大,因此这里对其作batch normalization进行归一化,并且经过tanh激活后得到最终的候选embedding序列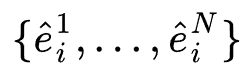 。为了基于特征流行度从候选embedding序列中选择一个最优的embedding,作者设计了一个controller生成搜索权重。
。为了基于特征流行度从候选embedding序列中选择一个最优的embedding,作者设计了一个controller生成搜索权重。
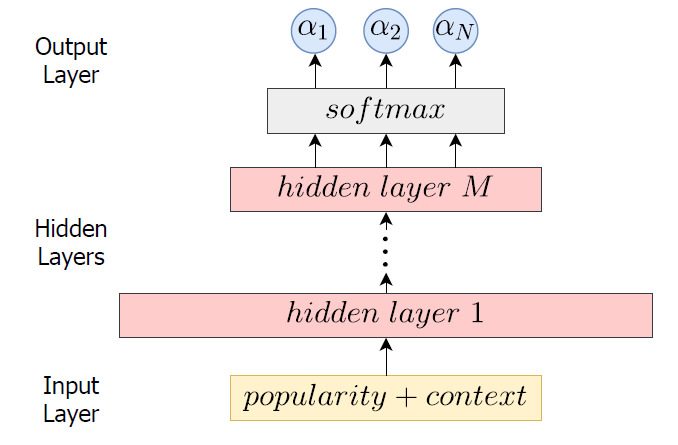
controller的结构如图所示,其中模型的输入为user流行度和上下文信息。其中上下文信息主要包含之前的网络选择参数与模型loss,它主要作为一个信号,如果模型之前表现良好,那么这一次生成的选择参数应该与之前相似。最后,模型使用controller生成的选择参数对之前的候选embedding作weighted sum pooling,即用户的最终embedding表示为: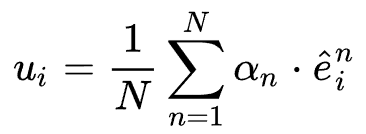 。物品的处理过程与用户相同,因此模型共有两个controller生成用户和物品的选择权重,用户和物品的最终embedding表示输入特征交互主模型(DNN)得到最终的预测结果。
。物品的处理过程与用户相同,因此模型共有两个controller生成用户和物品的选择权重,用户和物品的最终embedding表示输入特征交互主模型(DNN)得到最终的预测结果。
作者沿用DARTS的方式轮流训练主模型与controller,最终实验表明AutoEmb对比固定特征维度表现能够显著提高主模型的准确率,并且验证了模型为高流行度的特征倾向分配较大的embedding size,而为低流行度的特征倾向分配较小的embedding size。
3. Learnable embedding sizes for recommender systems. (ICLR 2021)
本文来自于清华大学,主要提出了一种端到端的特征表示搜索方法(PEP)。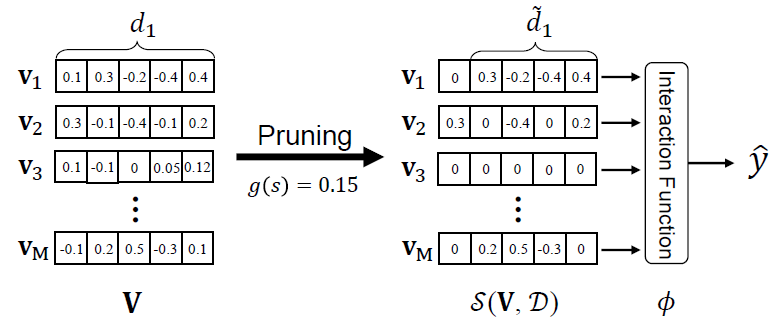
本文的核心思想是对特征表示的embedding table进行剪枝,具体可以分为剪枝和重训练两个阶段。
作者在剪枝阶段设置了可学习的参数对特征embedding值进行高通滤波来对特征表示重参化。剪枝重参化的公式可以表示如下:
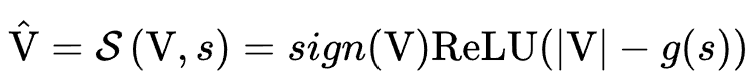
,其中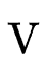 表示原始特征embedding,
表示原始特征embedding,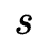 表示剪枝的阈值参数,
表示剪枝的阈值参数, 一般为sigmoid函数。之后,重参化的特征embedding
一般为sigmoid函数。之后,重参化的特征embedding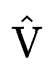 参与特征交互得到最终的预测结果并进行梯度下降训练。即在剪枝阶段,优化目标为:
参与特征交互得到最终的预测结果并进行梯度下降训练。即在剪枝阶段,优化目标为: 。这里阈值
。这里阈值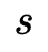 存在三种共享方式:1.Dimension Wise: 所有特征embddding的同一维度共享阈值,即
存在三种共享方式:1.Dimension Wise: 所有特征embddding的同一维度共享阈值,即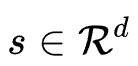 。2.Feature Wise: 每个特征的所有embedding维度共享阈值,即
。2.Feature Wise: 每个特征的所有embedding维度共享阈值,即 。3.Feature-Dimension Wise: 不存在共享权值,每个特征的所有embedding维度均有一个阈值参数控制剪枝,即
。3.Feature-Dimension Wise: 不存在共享权值,每个特征的所有embedding维度均有一个阈值参数控制剪枝,即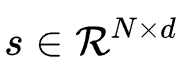 。
。
在剪枝阶段结束,我们可以根据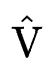 的值是否为0得到一个掩码矩阵
的值是否为0得到一个掩码矩阵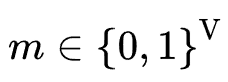 来决定embedding table的每个参数是否保留。在重训练阶段,根据Lottery Ticket Hypothesis,剪枝后的子网络在与原始网络的初始化方式相同时可以在有限的迭代步下逼近原网络,因此作者将特征embedding初始化为
来决定embedding table的每个参数是否保留。在重训练阶段,根据Lottery Ticket Hypothesis,剪枝后的子网络在与原始网络的初始化方式相同时可以在有限的迭代步下逼近原网络,因此作者将特征embedding初始化为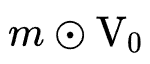 后进行重训练得到剪枝后的最终模型。
后进行重训练得到剪枝后的最终模型。
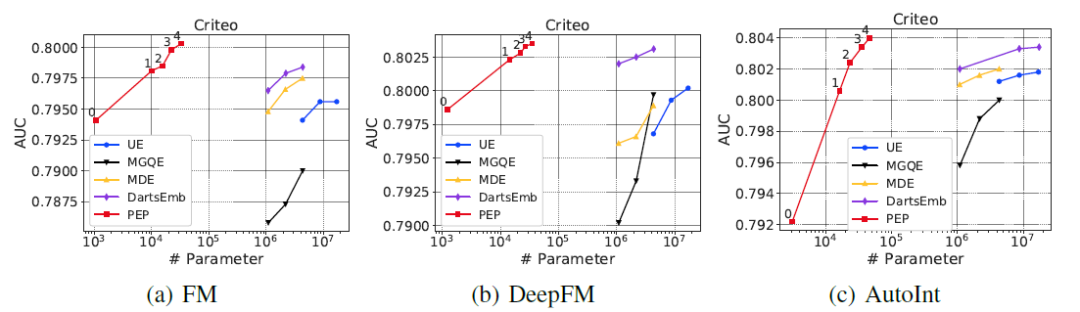
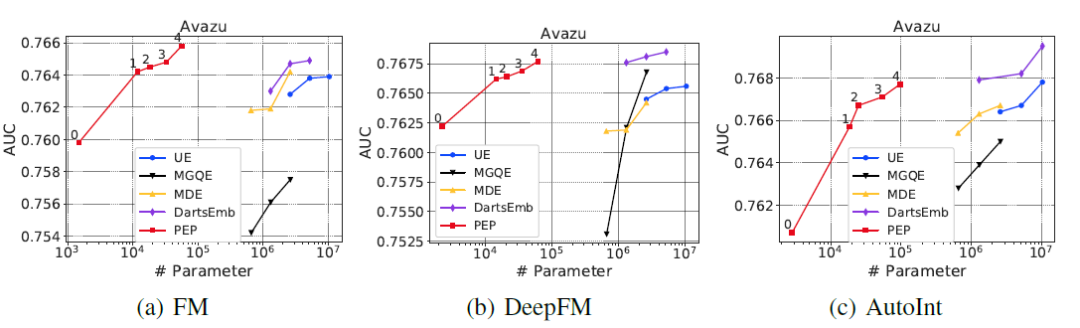
作者在Criteo与Avazu数据集上进行实验,可以看到PEP能够减少模型99.9%参数并且带来不错的精度提升。这也说明了CTR模型embedding table大部分参数都是冗余的,只有很少一部分参数在起作用。
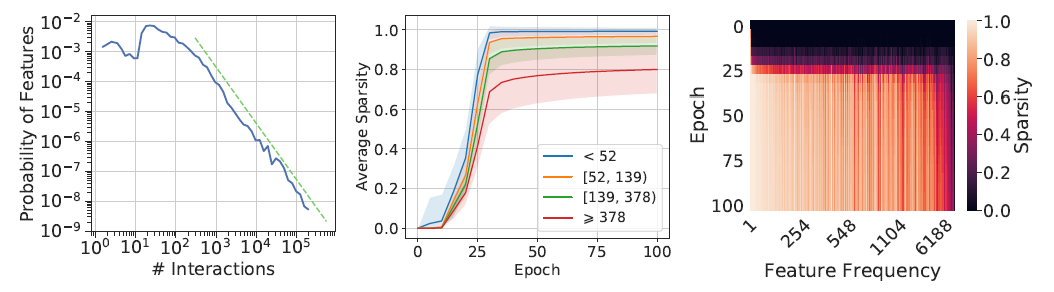
最终作者做了一个解释性实验,可以看到剪枝后那些出现频率较高的特征稀疏度较低,而出现频率较低的特征稀疏性较高,这也印证了NIS提到的特征embedding维度与特征出现频率的关系。
4. AutoDim: Field-aware Embedding Dimension Search in Recommender Systems. (WWW 2021)
本文提出了一种利用DARTS技术在特征域的粒度进行特征表示搜索的方法。本文首先指出不同的特征域的基数差异非常大,例如user id、item id这类特征域的基数可能达到百万级,而如性别、年龄这类特征域基数非常小,因此为它们统一的embedding维度并不合适。基于此,作者设计了一种端到端的可微分网络结构,为每个特征域设计多个可选embedding table进行网络搜索。
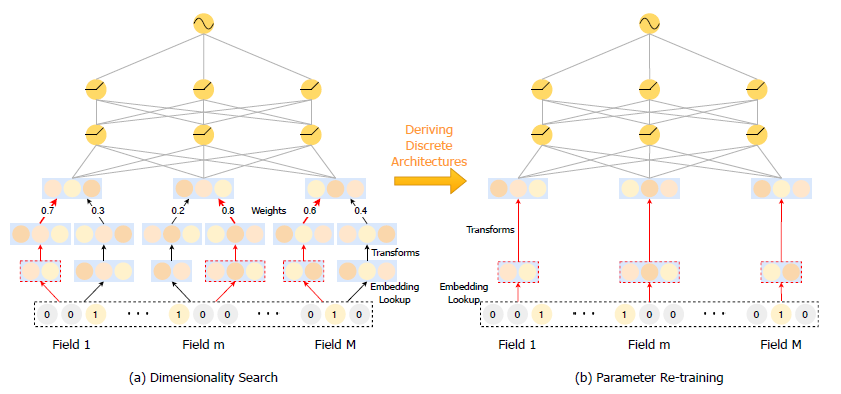
如图所示,该工作分为搜索阶段与重训练阶段。在搜索阶段,作者为每个特征域设置了N个候选embedding table,在对特征域m的特征实例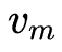 进行embedding时,对这N个embedding table进行lookup,得到一个候选embedding 序列
进行embedding时,对这N个embedding table进行lookup,得到一个候选embedding 序列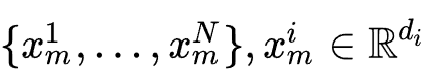 ,之后将所有候选embedding投影到相同维度,即
,之后将所有候选embedding投影到相同维度,即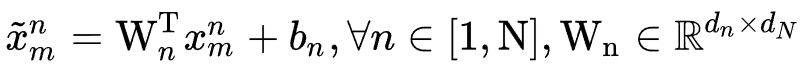 ,然后进行batch normalization后得到一个维度统一的归一化候选embedding序列
,然后进行batch normalization后得到一个维度统一的归一化候选embedding序列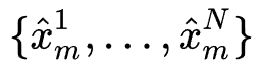 。为了使选择过程可导,作者对每个候选embedding设置一个搜索参数
。为了使选择过程可导,作者对每个候选embedding设置一个搜索参数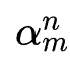 ,为了让选择序列逼近one-hot选择,这里采用了gumbel-softmax trick,即最终搜索参数的表达形式为:
,为了让选择序列逼近one-hot选择,这里采用了gumbel-softmax trick,即最终搜索参数的表达形式为:
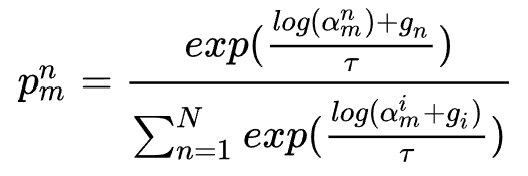
其中:
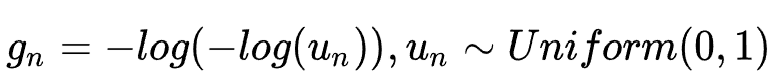
最终的特征表示为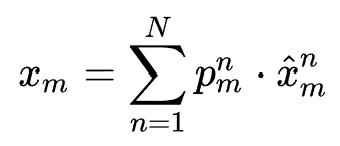 ,
,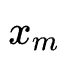 参与后续的特征交互得到模型最终的预测结果。后续沿用DARTS过程对搜索参数与模型参数轮流训练。
参与后续的特征交互得到模型最终的预测结果。后续沿用DARTS过程对搜索参数与模型参数轮流训练。
搜索结束后,每个特征域选取搜索参数最大的候选embedding,即
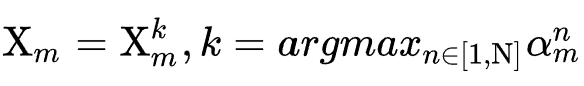
然后进行重训练,此阶段每个特征域只需查找最优的embedding table后进行投影即可得到最终的特征表示。
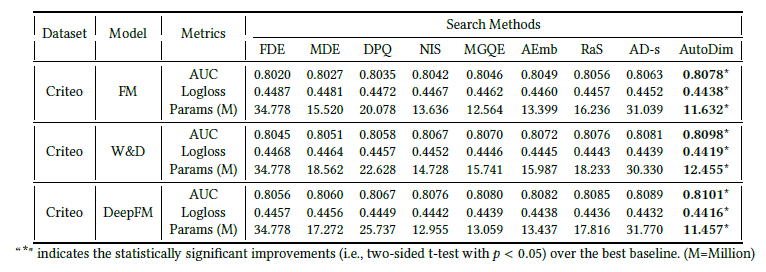
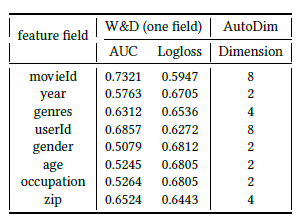
最终的实验结果表明此方法可以减少模型70%~80%的参数量。同时给出了movielens数据集的验证实验,证明此方法确实可以为那些基数较大的特征域分配较大的embedding size,而很大程度上决定模型表现的也往往是那些基数较大的特征域。
5. Autofis: Automatic feature interaction selection in factorization models for click-through rate prediction. (KDD 2020)
本文来自于华为。作者首先指出了大部分CTR模型的特征交互结构是通过手工设计或者枚举得到,这种交互结构不仅会占用大量的计算资源而且会引入大量无意义的特征交互,这些无效的特征交互会严重影响模型的推荐效果。基于此,作者提出了一种利用DARTS技术对FM及其衍生模型进行特征交互搜索的模型优化方法。
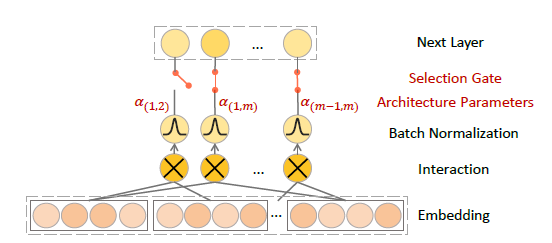
模型的搜索结构如上图所示。作者为FM枚举的每个二阶特征交互设计了一个selection gate的搜索参数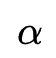 ,因此AutoFIS表示下的FM公式为:
,因此AutoFIS表示下的FM公式为:
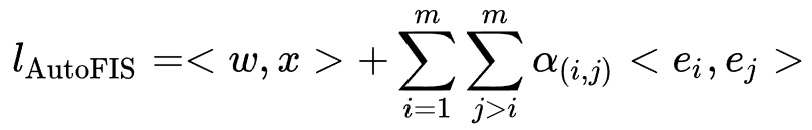
因为在训练过程中搜索参数直接与特征交互进行乘法操作,这样绑定训练会带来耦合问题:在训练过程无法区分参数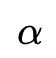 与特征内积的贡献情况,因为不重要的特征交互可以通过训练更小的特征embedding内积来赋予参数
与特征内积的贡献情况,因为不重要的特征交互可以通过训练更小的特征embedding内积来赋予参数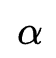 更大的值,因此
更大的值,因此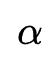 不能很好地反应特征交互的重要程度。为了解决这个问题,作者在进行特征交互选择前对所有的交互特征进行batch normalization,通过这种处理,
不能很好地反应特征交互的重要程度。为了解决这个问题,作者在进行特征交互选择前对所有的交互特征进行batch normalization,通过这种处理,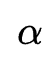 就可以反映对应交互特征的重要程度。
就可以反映对应交互特征的重要程度。
作者沿用DARTS技术对模型进行训练。但与传统DARTS不同的是,作者同时对网络搜索参数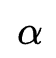 以及模型参数
以及模型参数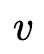 同时训练(one-level)。作者指出传统DARTS轮流训练
同时训练(one-level)。作者指出传统DARTS轮流训练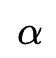 与
与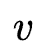 并且使用梯度下降近似表达模型最优的
并且使用梯度下降近似表达模型最优的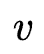 (two-level)会给特征交互搜索带来很大的误差,并且通过实验证明了one-level的优化方式明显优于two-level。
(two-level)会给特征交互搜索带来很大的误差,并且通过实验证明了one-level的优化方式明显优于two-level。
在搜索阶段结束后,作者根据搜索阶段的搜索结果得到一个Gate值来表示是否保留特定的交互特征,即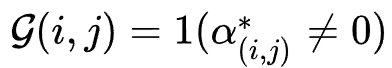 。之后进行重训练,在重训练阶段对于那些保留的特征交互同样保留参数
。之后进行重训练,在重训练阶段对于那些保留的特征交互同样保留参数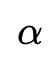 ,只不过这里的参数不再代表搜索权重,而是表示特征交互重要程度的注意力权重,模型重训练阶段的公式表达为:
,只不过这里的参数不再代表搜索权重,而是表示特征交互重要程度的注意力权重,模型重训练阶段的公式表达为:
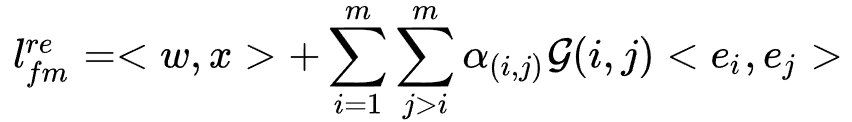
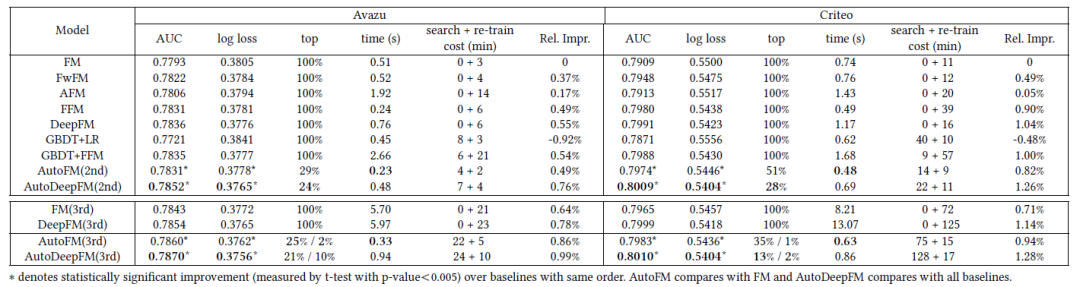
作者在Avazu以及Criteo两个公开数据集进行实验,结果表明AutoFIS能够在降低模型时延的情况下提升模型的预测精度,而且说明了传统CTR模型70%的二阶特征交互以及90%的三阶交互都是冗余的。
6. Autofeature: Searching for feature interactions and their architectures for click-through rate prediction. (CIKM 2020)
本文主要探索特征最佳特征交互以及特征交互运算,该工作提出了一种利用NBTree来搜索不同阶特征交互以及特征交互最佳运算操作的算法。
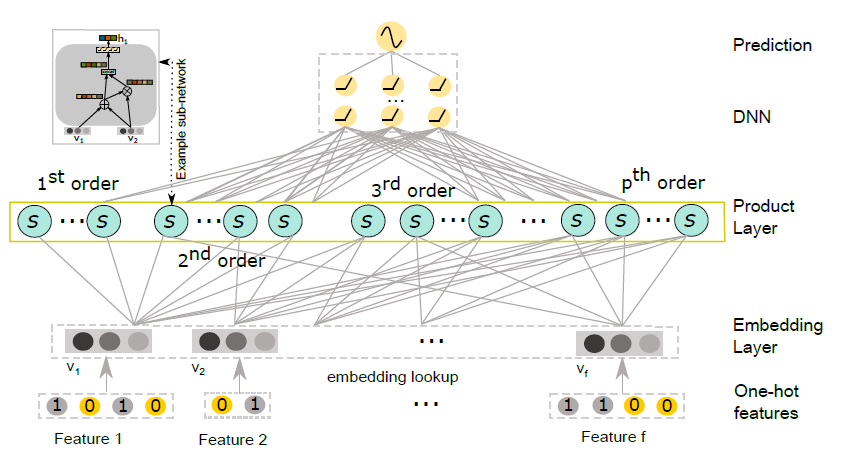
主模型的结构如图所示,其中Product Layer负责显式特征交互,是该工作主要搜索的结构,DNN负责隐式特征交互,整体构成单塔模型。待搜索的Product Layer主要由多个微网络构成(图中的绿色s圆圈),每个微网络负责特定阶数的特征交互,它的决定因素有:1.特征交互运算其顺序。2.特征交互阶数。为此,作者主要搜索以下5类运算:1.向量加。2.哈达玛积。3.拼接。4.哈达玛积+feed-forward。5.空操作(终止符)。并且将上述运算分别编码为1,2,3,4,0。并给每个微网络指定运算阶数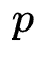 ,第
,第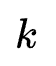 运算的输入为前
运算的输入为前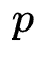 个运算的输出或者原始微网络的输入,整个微网络的运算过程可以构建一个DAG,并且每个微网络可以由一个string和
个运算的输出或者原始微网络的输入,整个微网络的运算过程可以构建一个DAG,并且每个微网络可以由一个string和 唯一确定,字符串的长度
唯一确定,字符串的长度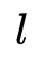 为这个微网络所允许的最大操作数。
为这个微网络所允许的最大操作数。
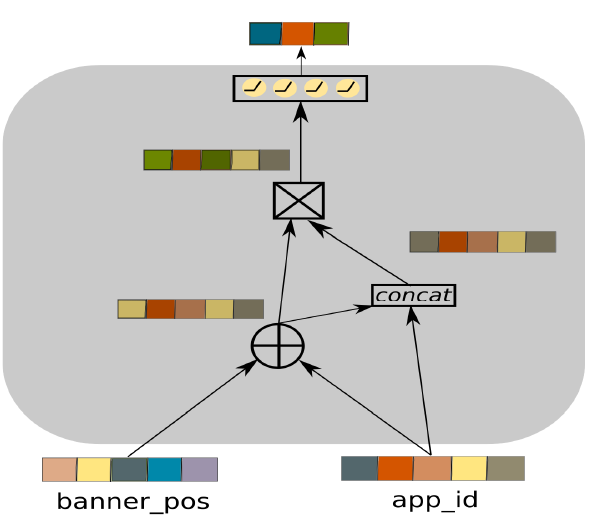
例如上图为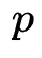 =2,
=2,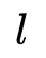 =4,banner_pos与app_id 对应的微网络,那么它的string表示为[1,3,4,0]。此外,以0为起始的string表示为需要舍弃特征交互,作者采用枚举的方式为每个特征交互分配一个待搜索的微网络,对于一个待搜索的最高阶交互为2的网络而言,它可以由一个长度为
=4,banner_pos与app_id 对应的微网络,那么它的string表示为[1,3,4,0]。此外,以0为起始的string表示为需要舍弃特征交互,作者采用枚举的方式为每个特征交互分配一个待搜索的微网络,对于一个待搜索的最高阶交互为2的网络而言,它可以由一个长度为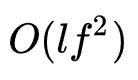 的string表示,其中
的string表示,其中 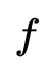 为特征域数量。
为特征域数量。

搜索过程如上图所示,作者利用NBTree进行网络结构搜索。
NBTree构建:树上的每个非叶子节点维护一个数据集 D,D中的一条记录为
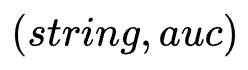 ,其中string表示网络结构,auc为string表现的auc,每个节点设置一个阈值
,其中string表示网络结构,auc为string表现的auc,每个节点设置一个阈值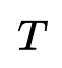 (作者采用D中第90%大的AUC),对于那些
(作者采用D中第90%大的AUC),对于那些 的记录分配到左子树(label=1),其余分配到右子树(label=0)。初始时刻,作者随机sample一些网络结构并且评估auc,构成根节点的数据集,并且按上述规则进行构建树,直到达到指定的最大深度。显然,树的最左节点对应的结构集合是表现最好的结构集合,而最右节点是表现最差的结构集合。
的记录分配到左子树(label=1),其余分配到右子树(label=0)。初始时刻,作者随机sample一些网络结构并且评估auc,构成根节点的数据集,并且按上述规则进行构建树,直到达到指定的最大深度。显然,树的最左节点对应的结构集合是表现最好的结构集合,而最右节点是表现最差的结构集合。网络搜索过程:首先sample叶子节点,即从所有叶子节点按CRP过程进行sample,选择叶子节点k的概率为
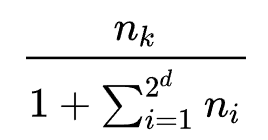 ,每次根据选中的叶子节点的数据集生成新的网络结构,并且评估auc,然后进行更新CRP权值
,每次根据选中的叶子节点的数据集生成新的网络结构,并且评估auc,然后进行更新CRP权值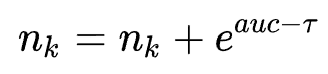 。这个过程会倾向于sample表现较好的节点,但也给了表现较差节点一些机会。从sample的叶子节点生成新网络结构的具体过程是将数据集的所有结构按auc降序排序,尝试从表现最好一对string(top2)进行string交叉操作,然后对交叉后得到的string进行多次变异操作得到一个新的string,然后判断此string是否属于NBTree的当前叶子节点,若属于则结束sample,否则继续尝试下一对string的交叉。然后评价生成string的auc并将其更新到当前叶子节点及其所有祖先节点的数据集中。经过一定迭代次数后,重新构建NBTree。重复这个过程直到找到大于desire auc的网络结构。
。这个过程会倾向于sample表现较好的节点,但也给了表现较差节点一些机会。从sample的叶子节点生成新网络结构的具体过程是将数据集的所有结构按auc降序排序,尝试从表现最好一对string(top2)进行string交叉操作,然后对交叉后得到的string进行多次变异操作得到一个新的string,然后判断此string是否属于NBTree的当前叶子节点,若属于则结束sample,否则继续尝试下一对string的交叉。然后评价生成string的auc并将其更新到当前叶子节点及其所有祖先节点的数据集中。经过一定迭代次数后,重新构建NBTree。重复这个过程直到找到大于desire auc的网络结构。
最后作者在Criteo,Avazu以及iPinYou三个数据集进行实验,搜索得到的模型不仅在排序任务表现上取得了很大提升,而且具有较低的参数量和Flops。
7. Autogroup: Automatic feature grouping for modelling explicit high-order feature interactions in ctr prediction. (SIGIR 2020)
本文来自华为,提出一种利用DARTS技术对特征进行分组来搜索最佳的特征交互结构的方法。
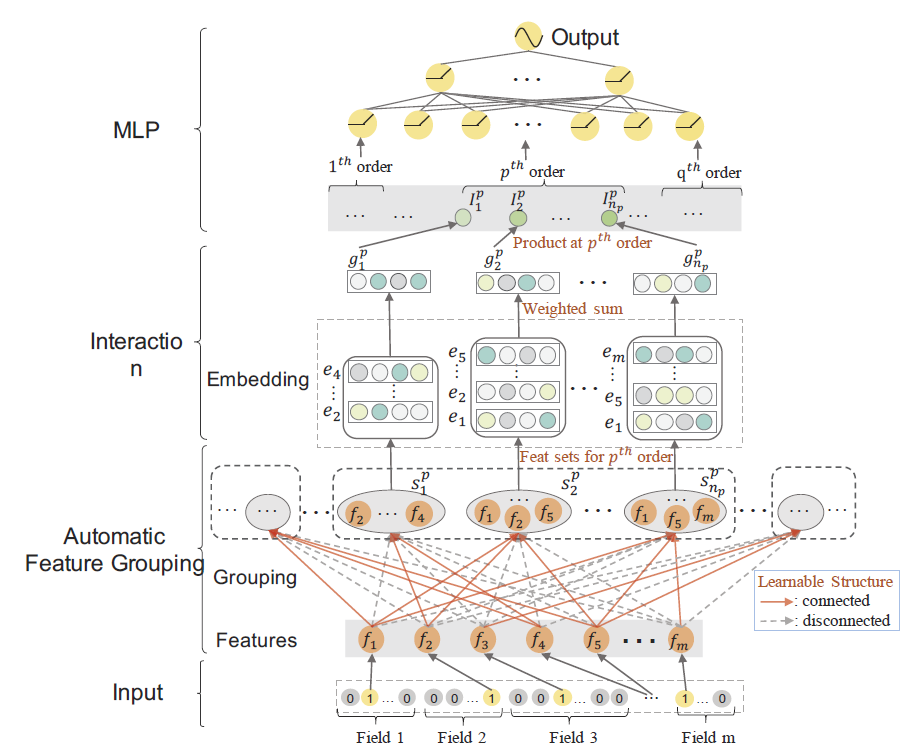
模型结构如图所示,作者为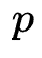 阶特征交互搜索
阶特征交互搜索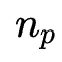 (超参)个特征组合
(超参)个特征组合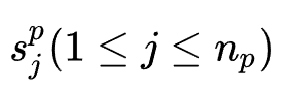 ,并且设计搜索变量
,并且设计搜索变量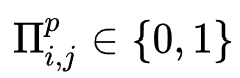 表示特征
表示特征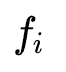 是否属于特征组合
是否属于特征组合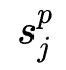 。为了使搜索过程可导,作者同样采用了Gumbel-Softmax trick,搜索变量的可导形式为:
。为了使搜索过程可导,作者同样采用了Gumbel-Softmax trick,搜索变量的可导形式为:
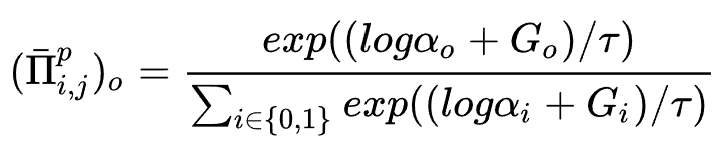 。
。
其中:
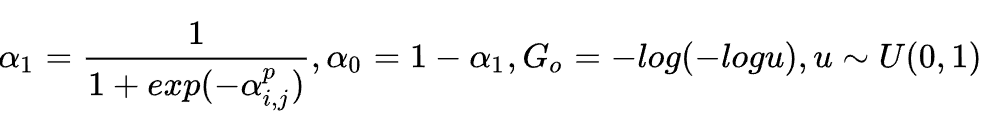
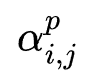 为网络学习的参数。
为网络学习的参数。
每一个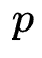 阶特征组合
阶特征组合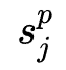 进行特征交互生成一个
进行特征交互生成一个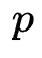 阶交互特征,受到FM多项式优化的启发,作者首先对所有特征作weighted sum pooling,即
阶交互特征,受到FM多项式优化的启发,作者首先对所有特征作weighted sum pooling,即
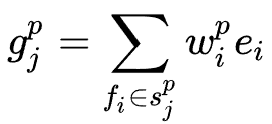
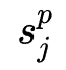 的特征交互形式为:
的特征交互形式为:
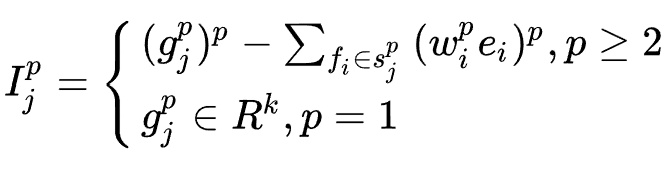
最终MLP的输入为:
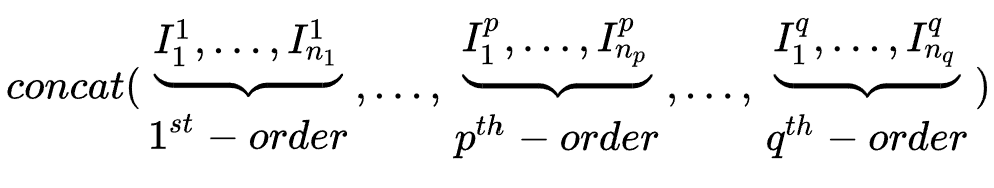
在搜索阶段,与传统DARTS处理过程不同的是,作者用同一mini-batch训练数据轮流训练搜索参数与网络参数。在test阶段,在特征组合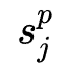 中,根据每个特征的搜索变量
中,根据每个特征的搜索变量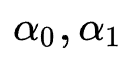 (由搜索参数
(由搜索参数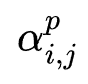 得出)的相对大小决定是否允许特征
得出)的相对大小决定是否允许特征  参与特征交互。
参与特征交互。
作者在Criteo,Avazu以及iPinYou三个数据集进行离线实验,对比传统模型取得了很大提升,并且在华为的线上系统进行10天的A/B test,对比一些优势baseline提升了10%。
8. AIM: Automatic Interaction Machine for Click-Through Rate Prediction. (arXiv:2111)
该工作来自上海交通大学,该工作是对AutoFIS的扩展,同时对特征组合以及不同特征组合交互的运算进行搜索,并且还包含了特征表示搜索,提出了一种利用DARTS技术进行特征表示搜索与特征交互搜索的统一搜索框架。
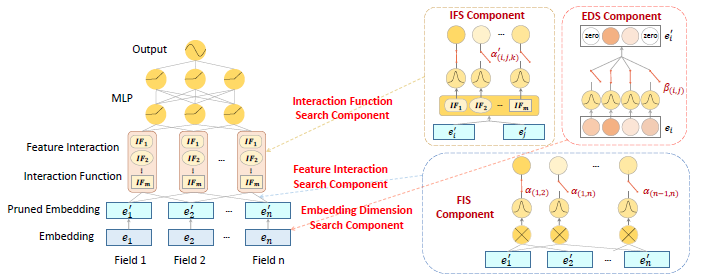
主模型的结构如图所示,主要搜索结构由三部分构成:FIS,IFS,EDS。其中IFS以及FIS负责特征交互搜索,EDS负责特征表示搜索。FIS负责搜索特征交互的组合,可以看到FIS的结构与AutoFIS一致,但基本的FIS结构只能探索特征间的二阶交互,这里作者设计了P阶特征交互的搜索算法:

作者采用自底向上的方式搜索高阶特征交互:每轮迭代枚举上一轮搜索好的低阶交互特征与原始特征进行二阶交互组合输入FIS进行此轮搜索训练,然后取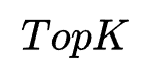 搜索权重对应的特征交互组合作为此轮迭代搜索的高阶特征交互。这里体现了一个贪心假设:任意一个重要的高阶交互特征,它的低阶子结构同样是重要的。
搜索权重对应的特征交互组合作为此轮迭代搜索的高阶特征交互。这里体现了一个贪心假设:任意一个重要的高阶交互特征,它的低阶子结构同样是重要的。
再看IFS结构,它为每个特征交互组合设计了不同的运算选择,具体而言,本文设计了inner,outer与kernel product三种运算。它同样以一个搜索权重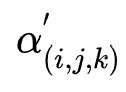 表示特征组合
表示特征组合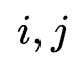 进行运算
进行运算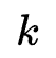 的权重。但是以这种方式进行搜索会导致不同运算反向传播梯度到同一embedding产生冲突,很难学习最优运算。为了避免这个问题,作者为每个运算单独设计了一个embedding。
的权重。但是以这种方式进行搜索会导致不同运算反向传播梯度到同一embedding产生冲突,很难学习最优运算。为了避免这个问题,作者为每个运算单独设计了一个embedding。
IFS的总体公式为: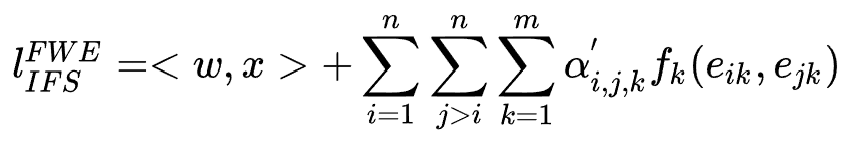
在搜索阶段,IFS与FIS同时进行搜索,因为不同特征组合与组合间的运算是紧密联系的,具体而言,以IFS结构作为FIS结构的特征交互运算模块而不是原有的内积运算。因此特征交互搜索在自底向上的搜索过程中同时完成了特征组合搜索与特征组合间的运算搜索。
再来看EDS结构,它为特征embedding的每个值分配一个剪枝搜索权重β,重参化后的embedding为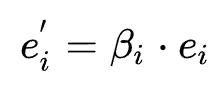 。然后同样以DARTS的方式进行训练,最后根据搜索非0权重位置构建embedding table的稀疏表示。
。然后同样以DARTS的方式进行训练,最后根据搜索非0权重位置构建embedding table的稀疏表示。
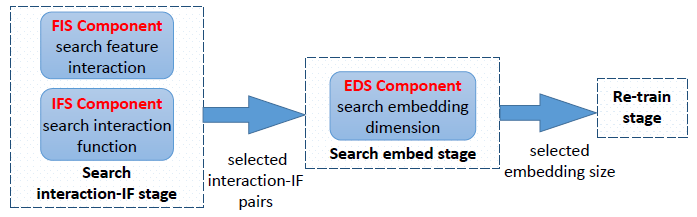
如上图所示,整体搜索过程分为三个阶段:特征交互搜索,特征表示搜索以及重训练。最终作者在Avazu,Criteo和Huawei三个数据集进行实验,结果表明AIM不仅相比于传统CTR模型有较大提升,而且超过AutoFeature,AutoGroup以及AutoFIS等仅进行特征交互搜索的搜索方法。
9. Towards automated neural interaction discovery for click-through rate prediction. (KDD 2020)
本文来自FaceBook,提出了一种搜索整体CTR模型结构的方法(AutoCTR),作者通过将网络结构模块化为积木,并将这些积木放入一个有向无环图的空间中,并且使用多目标进化算法探索、学习到最有效的网络交互结构。
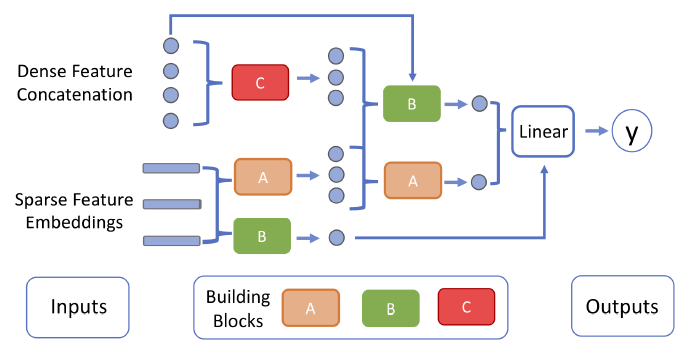
如图所示是设计的搜索空间DAG的一个概要示意图。每一个矩形代表一个待搜索的积木,积木可由一个四元组来唯一确定:(积木类型,原始输入特征选择,积木之间的连接,积木补充超参数)。其中积木类型主要包括内积,MLP以及FM三种类型,使用one-hot encoding;原始特征选择分为仅稠密特征、仅稀疏特征、二者均选以及二者均不选四种类型,使用one-hot encoding;积木之间的连接用于构建DAG,使用multi-hot encoding;积木补充的超参数为MLP隐层节点数量。所有的积木四元组按拓扑排序拼接成一个序列表示一个候选模型。
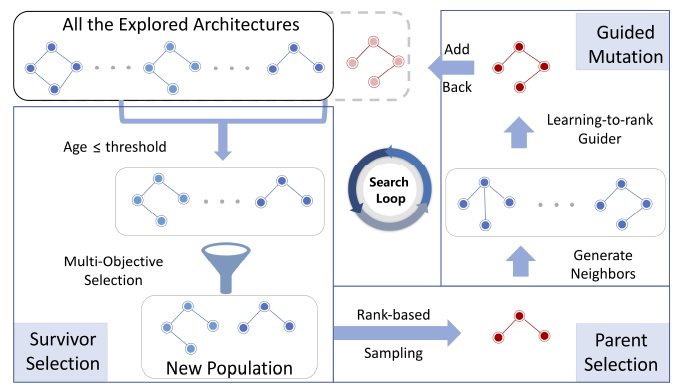
搜索过程如上图所示,每次迭代分为多目标幸存者选择、父结构的选取以及引导变换三个过程。
作者维护一个候选池,按顺序记录了所有已经搜索到的网络结构。
1. 在多目标幸存者选择阶段,作者首先按照候选池中网络结构的存在时间(年龄)进行筛选确定幸存者,为了方便表示,网络结构的年龄在每次迭代过程会初始化,其值为候选池的逆序。然后,作者根据年龄、模型表现以及模型复杂度三个因素评价幸存者的适应值,并给出了其量化公式:
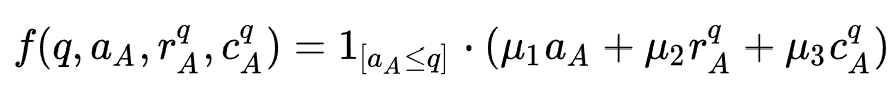
其中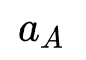 代表网络年龄,
代表网络年龄,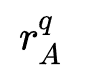 代表模型表现(例如AUC),
代表模型表现(例如AUC),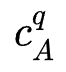 代表模型复杂度(例如FLops)。
代表模型复杂度(例如FLops)。
2. 在父结构选择阶段,作者按照模型的适应值对幸存者进行排序,并且按照分布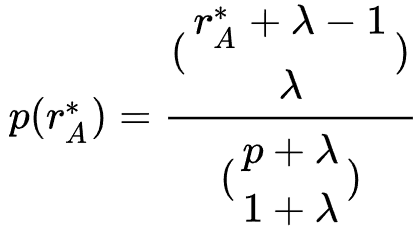 sample一个幸存者作为父结构,式中
sample一个幸存者作为父结构,式中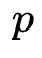 为幸存者总数,
为幸存者总数,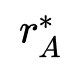 为rank,λ为偏向参数。
为rank,λ为偏向参数。
3. 引导变换过程根据sample的父结构生成一个子结构。首先由父结构经过随机变异生成一系列的子结构,然后由一个Guider对这些子结构进行排序,选取最优结构加入到候选池。这里作者选取GBDT作为Guider,用维护的候选池作为数据集,采用LambdaRank算法学习候选池模型的偏序关系。
作者在Criteo、Avazu以及KDD三个数据集进行实验,AutoCTR相比于随机搜索以及强化学习等NAS方法有一定提升,并且搜索得到模型的Flops相对较小。
10. AMER: automatic behavior modeling and interaction exploration in recommender system. (IJCAI 2021)
本文来自北京大学,主要提出了一种以one-shot NAS方式同时进行序列特征与非序列特征的表示搜索、非序列特征的特征交互搜索以及MLP的结构搜索的方法。
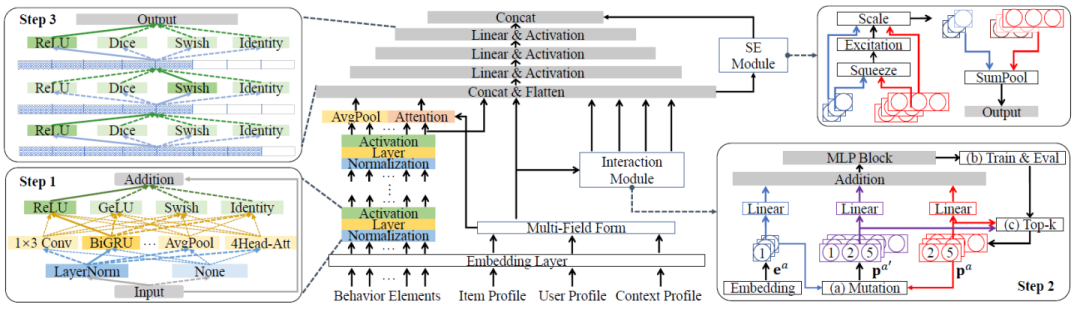
模型的结构如上图所示,搜索过程主要包括用户行为的序列特征交互搜索(Step1)、非序列特征的高阶特征交互搜索(Step2)以及负责特征聚合的MLP结构搜索(Step3)。
1. 用户行为序列建模搜索过程:作者设计多个stack起来的block作为搜索对象,每个block依次进行归一化、Layer函数以及激活函数三个操作。每个block的三个操作的搜索空间为:
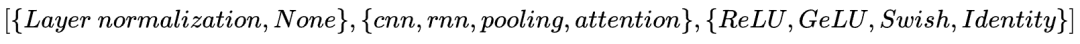
设初始序列特征的表示为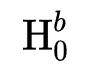 ,每个block的变换为:
,每个block的变换为:
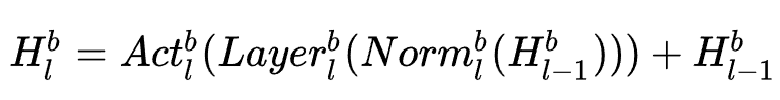
作者stack了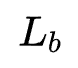 个block,并且对最后一个block的输出作sum-pooling:
个block,并且对最后一个block的输出作sum-pooling: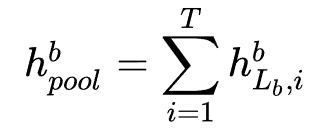 ,以及DIN的激活操作:
,以及DIN的激活操作: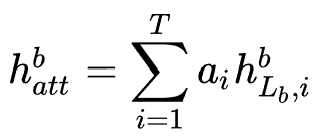 ,结合最后一个隐层
,结合最后一个隐层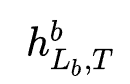 得到最终的序列特征表示:
得到最终的序列特征表示: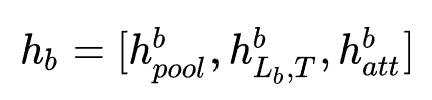 。为了避免耦合问题,作者使用预训练的MLP进行one-shot NAS。
。为了避免耦合问题,作者使用预训练的MLP进行one-shot NAS。
2. 非序列特征交互的搜索过程:此过程作者自底向上地搜索高阶特征交互。初始时刻设置一个候选池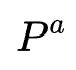 ,并将其初始化为所有非序列特征的集合,每次迭代枚举
,并将其初始化为所有非序列特征的集合,每次迭代枚举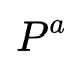 与所有非序列特征的二阶交互(交互操作为哈达玛积)加入
与所有非序列特征的二阶交互(交互操作为哈达玛积)加入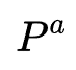 ,并且使用预训练的MLP完成特征聚合来进行one-shot NAS,最后保留在验证集效果最好的topK交互特征。
,并且使用预训练的MLP完成特征聚合来进行one-shot NAS,最后保留在验证集效果最好的topK交互特征。
3. MLP的搜索过程:此过程主要搜索MLP每个隐层的shape以及激活函数。为了优化搜索过程,作者借鉴single-path NAS的思想:将每个隐层的权重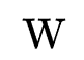 初始化为最大shape
初始化为最大shape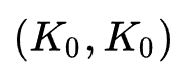 ,设置搜索变量
,设置搜索变量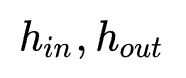 ,以共享权值
,以共享权值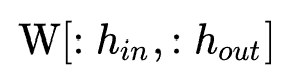 的方式进行搜索。
的方式进行搜索。
作者在Amazon Beauty、Steam两个sequential dataset以及Criteo、Avazu两个non-sequential dataset进行实验,用户行为序列特征建模表现优于BERT4Rec等强势模型,非序列特征交互建模表现相比xDeepFM、FibiNet有较大提升。
小结
利用NAS技术优化特征工程以及模型结构是目前CTR方向的热点,此类方法的核心在于确定合适的搜索目标并且设计高效的搜索算法。从搜索目标来看,目前大部分工作集中于特征表示搜索、特征交互搜索以及整体网络结构搜索三个方面。这些工作的搜索技术比较灵活,涵盖了强化学习、DARTS,贝叶斯优化以及进化算法等方法,并且这些技术需要设计灵活的数据结构来表示搜索目标。总体而言,通过NAS能够有效地去除CTR模型的冗余结构,提升模型的预测表现。
参考文献
[1] Neural input search for large scale recommendation models. [2] AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations. [3] Learnable embedding sizes for recommender systems. [4] AutoDim: Field-aware Embedding Dimension Search in Recommender Systems. [5] Autofis: Automatic feature interaction selection in factorization models for click-through rate prediction. [6] Autofeature: Searching for feature interactions and their architectures for click-through rate prediction. [7] Autogroup: Automatic feature grouping for modelling explicit high-order feature interactions in ctr prediction. [8] AIM: Automatic Interaction Machine for Click-Through Rate Prediction. [9] Towards automated neural interaction discovery for click-through rate prediction. [10] AMER: automatic behavior modeling and interaction exploration in recommender system.
这篇关于Learning to Learn: 点击率预测模型与网络结构搜索相结合的研究进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







