本文主要是介绍pytorch实战——气温预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- year,month,day,week 分别表示具体的时间
- temp_2:前天的最高温度值
- temp_1:昨天的最高温度值
- average:在历史中,每年这一天的平均最高温度值
- actual:这就是我们的标签值,当天的真实最高温度
- friend:你的朋友猜测的可能值
#coding=utf-8
from ast import increment_lineno
from cProfile import label
from pickletools import optimize
from pyexpat import features
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
import warnings
import datetime
from sklearn import preprocessing
# ***************************************读入数据********************************************#
#读入数据
data=pd.read_csv('temps.csv')
#展示前几行数据
print(data.head())
#数据维度,列表示特征值
# print("data_dim:",data.shape)
# ******************************************************************************************## *******************************************处理时间数据************************************#
#处理时间数据
years =data['year']
months = data['month']
days = data['day']#datetime格式
#必须把str转换为datetime。转换方法是通过datetime.strptime()实现
#datetime.datetime.strptime:万能的日期格式转
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day))
for year, month, day in zip(years, months, days)]dates = [datetime.datetime.strptime(date,'%Y-%m-%d') for date in dates]
#输出时间
# print(dates[:5])
# 将week转为独热编码
data = pd.get_dummies(data)
print(data.head(5))
# **************************************************************************************## ****************************************************画图******************************#
#准备画图 指定默认风格
# plt.style.use('fivethirtyeight')# #设置布局
# fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2,ncols=2,figsize=(15, 15))
# #X轴上旋转45度并且右对齐
# fig.autofmt_xdate(rotation=45)# #第一幅图
# ax1.plot(dates,data['actual'])#画图 x轴为时间 y轴为真实温度
# ax1.set_xlabel('')
# ax1.set_ylabel('Temperature')
# ax1.set_title('Max Temp')# #第二幅图
# ax2.plot(dates, data['temp_1']) # 昨天
# ax2.set_xlabel('')
# ax2.set_ylabel('Temperature')
# ax2.set_title('Previous Max Temp')# #第三幅图
# ax3.plot(dates, data['temp_2']) # 前天
# ax3.set_xlabel('Date')
# ax3.set_ylabel('Temperature')
# ax3.set_title('Two Days Prior Max Temp')# #第四幅图
# ax4.plot(dates, data['friend']) # friend
# ax4.set_xlabel('Date')
# ax4.set_ylabel('Temperature')
# ax4.set_title('Friend Estimate') #tight_layout会自动调整子图参数,使之填充整个图像区域#会自动调整子图参数,使之填充整个图像区域。这是个实验特性,可能在一些情况下不工作。它仅仅检查坐标轴标签、刻度标签以及标题的部分。
# plt.tight_layout(pad=2)
#显示图片
# plt.show()
# **************************************************************************************## **********************************数据预处理******************************************##标签
labels=np.array(data['actual'])#将标签去除掉
data=data.drop('actual',axis=1)#名字单独保存一下
datas=list(data.columns)#转换格式
data=np.array(data)#将数据标准化
#fit_transform是fit和transform的组合,既包括了训练又包含了转换。
inputs = preprocessing.StandardScaler().fit_transform(data)
# **************************************************************************************## **************************************构建网络模型*************************************#
# x=torch.tensor(inputs,dtype=float)
# y=torch.tensor(labels,dtype=float)# #初始化权重参数
# #(14,128)表示将14个特征 转为 隐层的128个特征 weights权重参数
# weights = torch.randn((14, 128), dtype=float, requires_grad=True)
# #biases 偏置参数 对128个特征做微调
# biases = torch.randn(128, dtype=float, requires_grad=True)# #将128个特征转为一个特征作为输出
# weights2 = torch.randn((128, 1), dtype=float, requires_grad=True)
# biases2 = torch.randn(1, dtype=float, requires_grad=True)# #设置学习率
# learning_rate=0.005#若偏差较大则改变学习率
# #损失值
# losses=[]# for i in range(1000):
# #计算隐层
# hidden=x.mm(weights) + biases# #加入激活函数:除了最后一层,都会连权重层(后连接激活函数)
# hidden=torch.relu(hidden)# #预测结果
# pre=hidden.mm(weights2)+biases2# #计算损失
# loss = torch.mean((pre - y) **2)
# losses.append(loss.data.numpy())# #打印损失值
# if i % 100==0:
# print('loss',loss)# #反向传播
# loss.backward()# #更新参数
# #更新参数,-号表示反方向,梯度下降任务
# weights.data.add_(-learning_rate * weights.grad.data)
# biases.data.add_ (-learning_rate * biases.grad.data)
# weights2.data.add_(-learning_rate * weights2.grad.data)
# biases2.data.add_(-learning_rate * biases2.grad.data)# # 每次迭代都得记得清空
# weights.grad.data.zero_()
# biases.grad.data.zero_()
# weights2.grad.data.zero_()
# biases2.grad.data.zero_()# **************************************************************************************## **************************************构建简单网络模型**********************************#
input_size=inputs.shape[1]
hidden_size=128
output_size=1
batch_size=16
Mynn=torch.nn.Sequential(torch.nn.Linear(input_size,hidden_size),torch.nn.Sigmoid(),torch.nn.Linear(hidden_size,output_size),)Loss = torch.nn.MSELoss(reduction='mean')
# reduction='mean'
optimizer=torch.optim.Adam(Mynn.parameters(),lr=0.01)#训练网络
Losses=[]
for i in range(1000):batch_loss=[]#使用Mini-Batch 方法来进行训练for start in range(0, len(inputs), batch_size):end = start + batch_size if start + batch_size < len(inputs) else len(inputs)xx = torch.tensor(inputs[start:end],dtype = torch.float,requires_grad = True)yy = torch.tensor(labels[start:end],dtype = torch.float,requires_grad = True)yy = yy.reshape(-1, 1)#计算预测值prediction=Mynn(xx)# print(yy.shape)#计算预测值和真实值的差值l=Loss(prediction,yy)#清空迭代optimizer.zero_grad()#反向传播l.backward(retain_graph=True)#更新参数optimizer.step()#将损失值存储batch_loss.append(l.data.numpy())#打印一下if i%100==0:Losses.append(np.mean(batch_loss))print(i,np.mean(batch_loss))# # **************************************************************************************## # ************************************预测模型和真实值 画图*******************************#
dx=torch.tensor(inputs,dtype=torch.float)
predict=Mynn(dx).data.numpy()#创建一个表格来存日期和其对应的标签数据
true_data=pd.DataFrame(data={'data':dates,'actual':labels})#创建时间用于对预测模型的使用
months=data[:,datas.index('month')]
days = data[:, datas.index('day')]
years =data[:,datas.index('year')]test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day))for year, month, day in zip(years, months, days)
]test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates
]
#predict.reshape(-1) 要一列的值,不能为矩阵
predit_data=pd.DataFrame(data={'data':test_dates,'predction':predict.reshape(-1)})#画图
plt.plot(true_data['data'],true_data['actual'],'b-',label='actiual')
plt.plot(predit_data['data'],predit_data['predction'],'ro',label='predction')plt.xticks(rotation=60)
plt.legend()
plt.xlabel('Data')
plt.ylabel('Maximum Temperature')
plt.title('Actual and Predicted')plt.show()# # **************************************************************************************#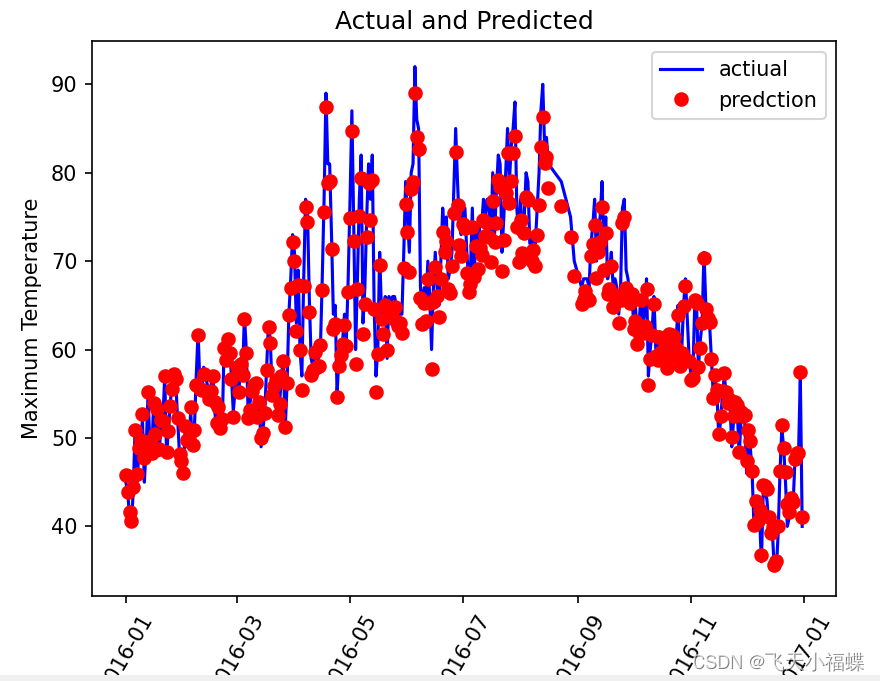
这篇关于pytorch实战——气温预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




