本文主要是介绍基于python的电商运动服饰销售可视化分析系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
温馨提示:文末有 CSDN 平台官方提供的学长 Wechat / QQ 名片 :)
1. 项目背景
随着电⼦商务的蓬勃发展,⽹络服装销售已经逐渐成为消费者最为青睐的廉价购物渠道。本项目基于python网络爬虫从某电商平台抓取所有运动服饰的销售数据,分析不同品牌运动服装价格分布、主流品牌运动服装销售占比、不同标签的运动服装销售占比、男女款式运动服装销售占比等信息,多维度对比各类服装价格的高低。并利用 TensorFlow 构建深度学习模型,实现对运动服饰销售价格的建模和预测。
2. 功能组成
基于python的电商运动服饰销售分析与预测系统的功能主要包括:
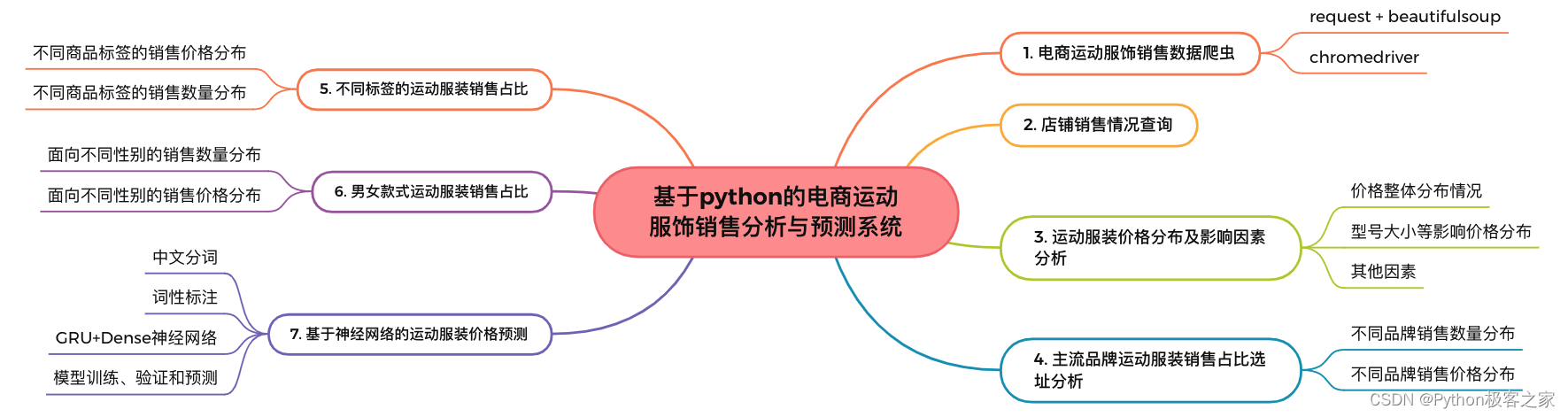
3. 电商运动服饰销售数据爬虫
利用 request + beautifulsoup 等工具,抓取某电商平台的运动服饰栏目的在售商品及店铺等信息:
options = Options()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
chrome_driver = 'path to chromedriver'
browser = webdriver.Chrome(chrome_options=options, executable_path=chrome_driver)base_url = 'https://list.xxxxx.com/list.html?cat=1318,12102,9765&page={}&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main'file_out = open('sports_wears.json', 'w', encoding='utf8')
page = 1
while page < 262:url = base_url.format(page)print('--> 抓取 {} 页:{}'.format(page, url))browser.get(url)soup = BeautifulSoup(browser.page_source, 'lxml')items = soup.find_all('li', class_='gl-item')item_infos = []for item in items:item_info = {}# 服装价格price = item.find('div', class_='p-price').i.text.strip()# 服装名称name = item.find('div', class_='p-name').a.em.text.strip()# 评论人数......# 店铺名称......item_info['comment'] = commentitem_info['shop'] = shopitem_info['tags'] = tagsprint(json.dumps(item_info, ensure_ascii=False))item_infos.append(json.dumps(item_info, ensure_ascii=False) + '\n')page += 1# 保存数据file_out.writelines(item_infos)file_out.flush()time.sleep(1.1)
browser.close()
4. 电商运动服饰销售分析与预测系统
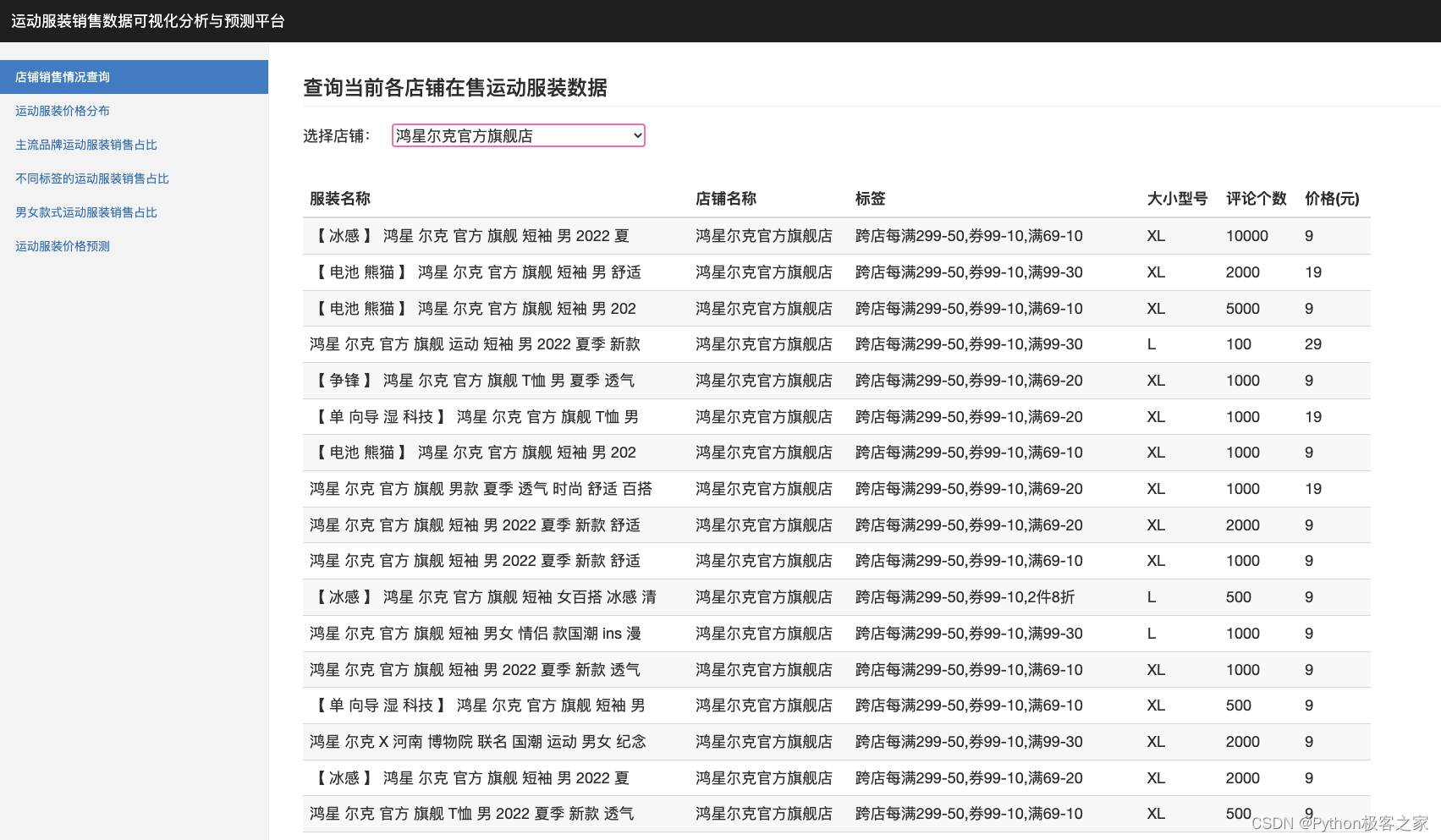
4.1 店铺销售情况查询
使用选择框进行店铺的选择,查询当前各店铺在售运动服装的数据,包括:服装名称、店铺名称、标签、大小型号、评论个数、价格(元):
4.2 运动服装价格分布及影响因素分析
为了更好的统计在售运动服装价格分布和大小型号之间的关系,设定了三类图,不同型号的运动服装在售件数(扇形图)、不同大小型号的运动服装的均价分布(条形图)、电商在售运动服装价格分布情况(散点图):
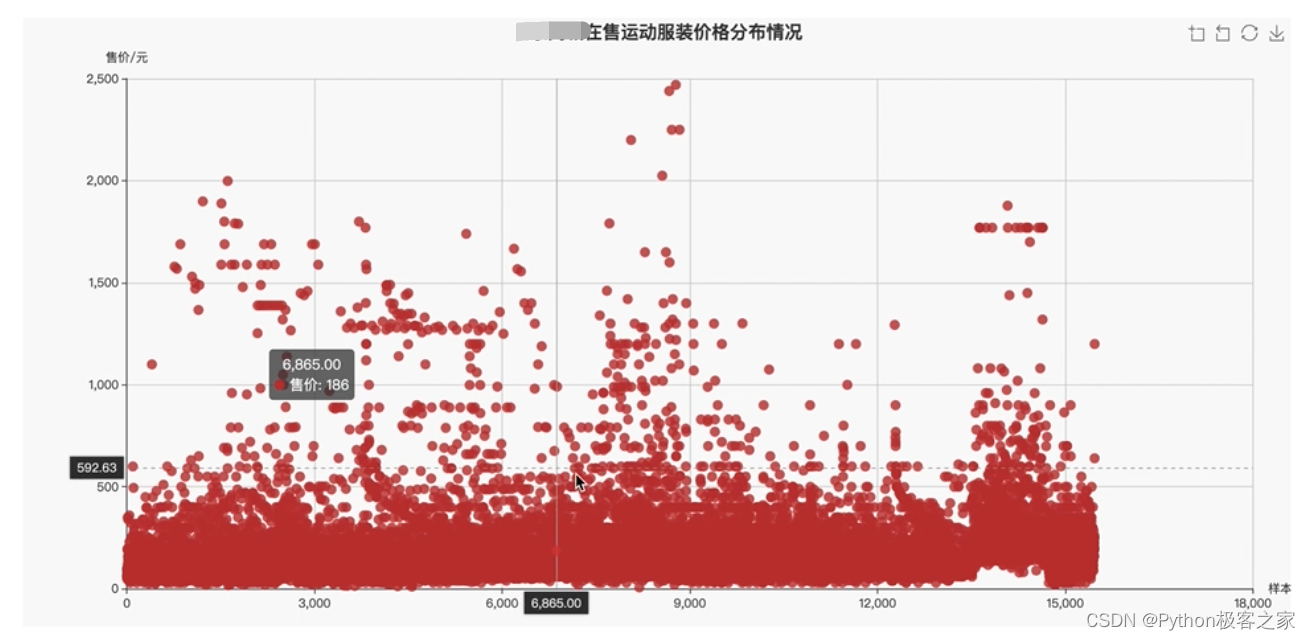
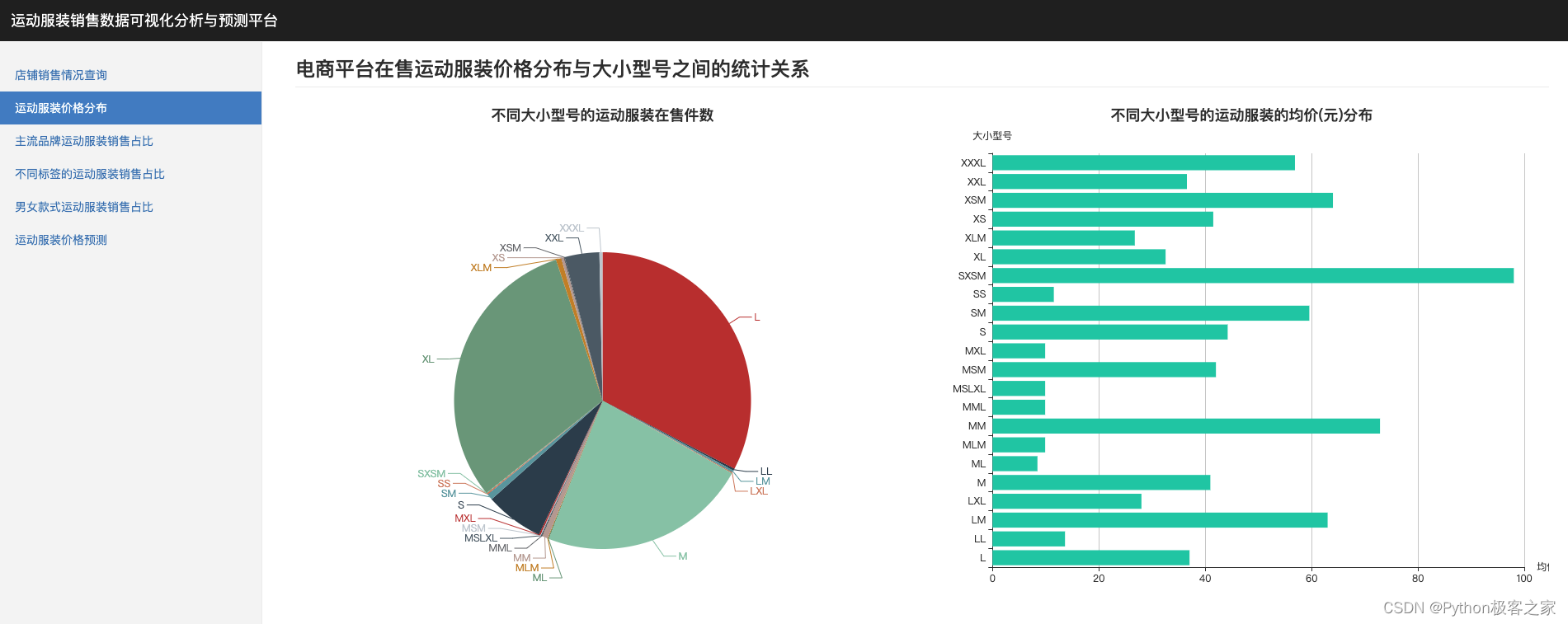
各种型号的运动服装在售件数都显示在了扇形图对应的区域中,当鼠标悬浮在相应的位置时,便会显示该型号的在售个数和占比信息,如图中显示M型号的在售个数为3901,占比25.2%。在第二张图中,显示了不同大小型号的运动服装的均价分布,当鼠标悬浮在相应的位置时,便会显示该型号的均价信息,如途中显示的SS均价在559.00元。可以看出,在0-500之间的是最多的。同时由于散点过于密集,在此图的右上角具备区域缩放、区域缩放还原、还原、下载的功能。通过图表,可以很清晰的看到在售运动服装价格分布与大小型号之间关系。
4.3 主流品牌运动服装销售占比
不同品牌的运动服饰,其销售价格、在售数量不同,也反应了品牌的受欢迎程度,对不同品牌运动服装销售占比就行统计分析:
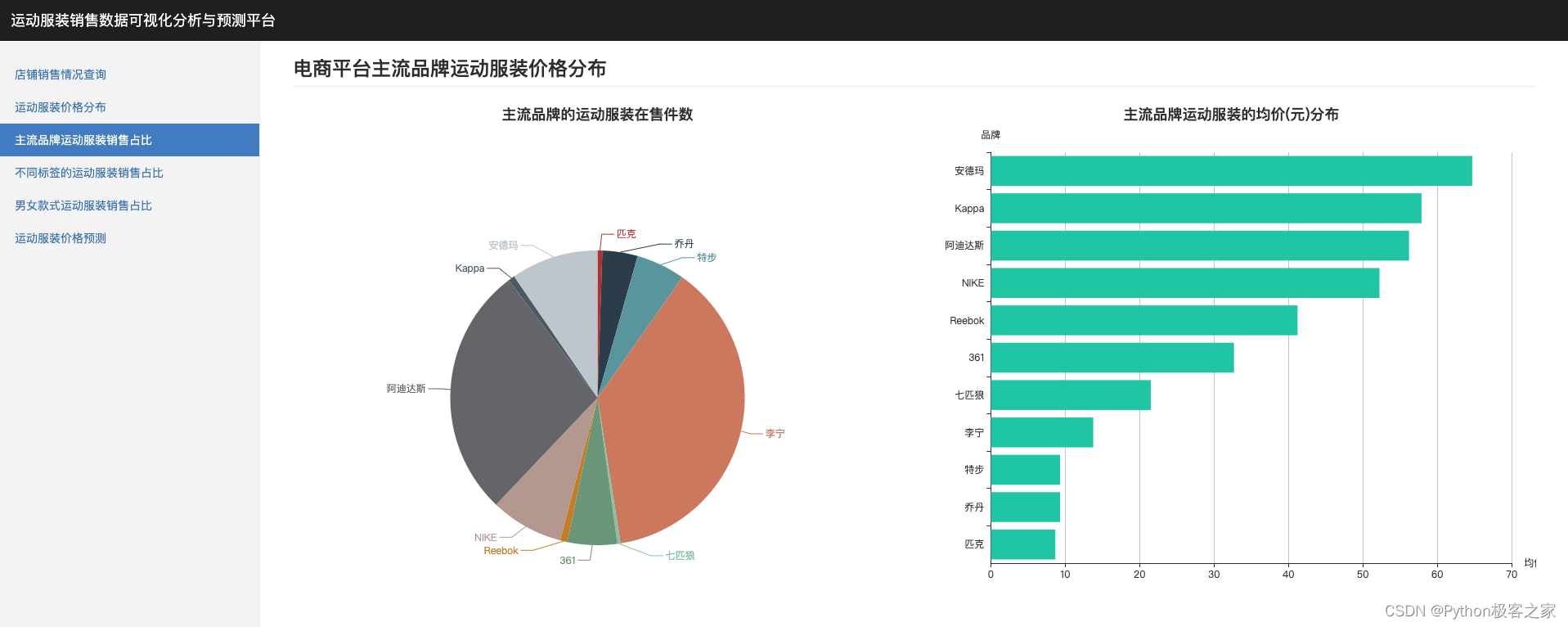
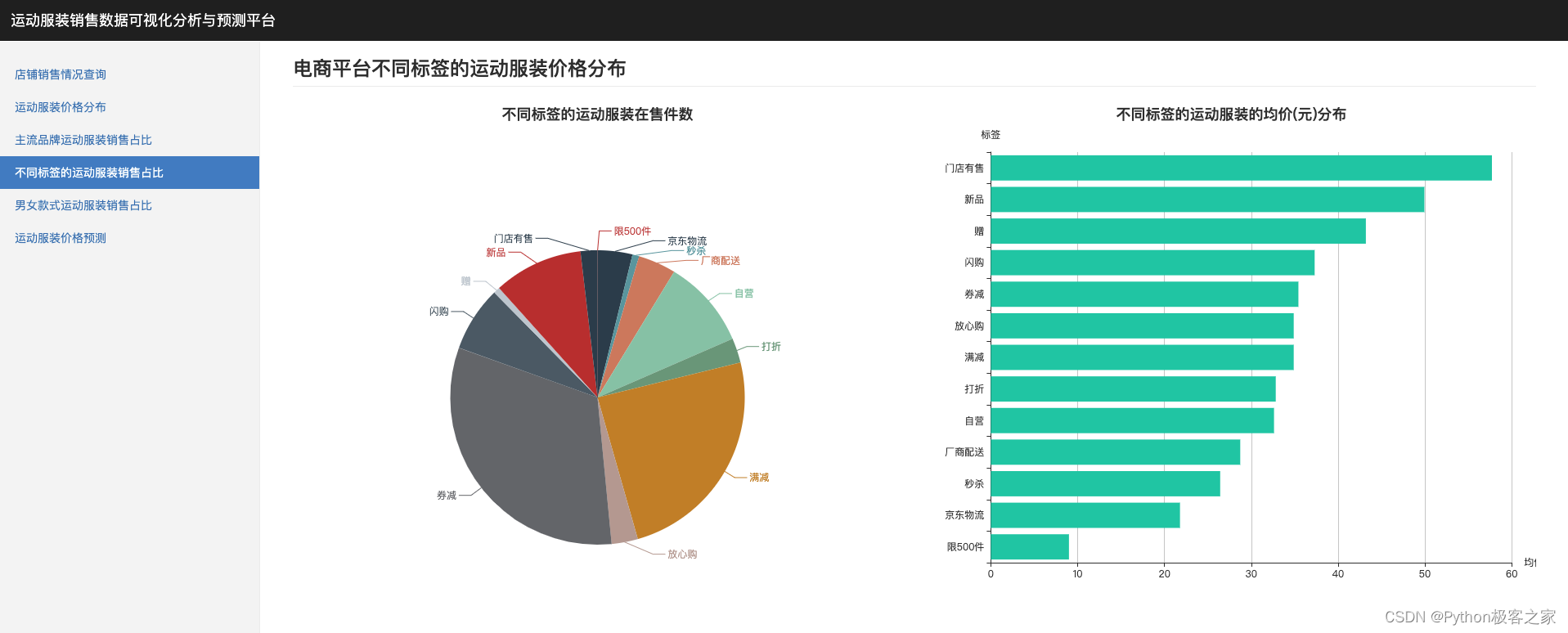
4.4 不同标签的运动服装销售占比
对新品、放心购、闪购、赠、门店有售、厂商配送、物流、险、自营、满减、满赠等不同标签的商品就行统计分析:
4.5 男女款式运动服装销售占比
分析性别对运动服饰销售的影响程度,对齐销售占比就行统计分析:

4.6 基于神经网络的运动服装价格预测
利用商品的描述文本和标签等信息,预测商品的销售价格。基于 keras 或 TensorFlow 构建双向 GRU+Dense 的神经网络模型,利用抓取的运动服装数据进行模型的训练和验证:
# 构造双向 GRU + Dense 神经网络模型
def build_model():inp = Input(shape=(maxlen,))x = Embedding(max_features, embed_size)(inp)x = Bidirectional(GRU(64, return_sequences=True))(x)x = GlobalMaxPool1D()(x)x = Dense(16, activation="relu")(x)x = Dropout(0.1)(x)x = Dense(len(all_price_levels_map), activation="softmax")(x)model = Model(inputs=inp, outputs=x)model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])return model
模型结构如下:
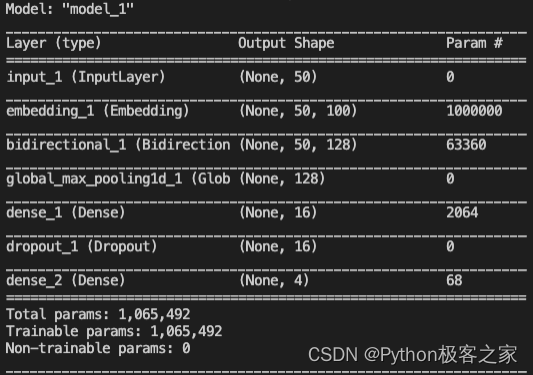
并对商品的描述文本进行中文分词和词性标注:
# 词性标注算法
from jieba.analyse.tfidf import TFIDFclass WordSegmentPOSKeywordExtractor(TFIDF):def extract_sentence(self, sentence):......seg_words = []pos_words = []for w in words:wc = w.wordseg_words.append(wc)pos_words.append(w.flag)if len(wc.strip()) < 2 or wc.lower() in self.stop_words:continuefreq[wc] = freq.get(wc, 0.0) + 1.0return seg_words, pos_wordsextractor = WordSegmentPOSKeywordExtractor()

5. 结论
本项目基于python网络爬虫从某电商平台抓取所有运动服饰的销售数据,分析不同品牌运动服装价格分布、主流品牌运动服装销售占比、不同标签的运动服装销售占比、男女款式运动服装销售占比等信息,多维度对比各类服装价格的高低。并利用 TensorFlow 构建深度学习模型,实现对运动服饰销售价格的建模和预测。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 Wechat / QQ 名片 :)
精彩专栏推荐订阅:
1. Python 毕设精品实战案例
2. 自然语言处理 NLP 精品实战案例
3. 计算机视觉 CV 精品实战案例

这篇关于基于python的电商运动服饰销售可视化分析系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






